dremio platform
Dremio Lakehouse Management for Apache Iceberg
Simplify and automate Iceberg data management for the lakehouse
OVERVIEW
Iceberg Data lakehouse management with automatic optimization and Git-for-data in Dremio Cloud
Dremio's data lakehouse management service for Apache Iceberg enables data teams to manage their data with Git-like version control and automatically optimize their data for high performance analytics

A Modern Data Catalog built on Apache Iceberg
Dremio's Iceberg-native data catalog enables easy management of multiple domains and gives data teams centralized security and governance. The Modern Data Catalog is accessible by multiple execution engines for a variety of workloads, including Dremio's Arrow-based SQL Query Engine, Spark, Flink, and more. Data always remains in an open format in the data lake, so you maintain control over your data.
Automated data optimization for high performance and cost management
Eliminate time-consuming data management tasks while keeping queries performant and reducing storage utilization. Dremio automatically optimizes and cleans up Apache Iceberg tables in the data catalog. Automatic optimization features include compaction, which automatically rewrites small files into larger ones to keep queries performant, and garbage collection, which automatically removes unused manifest files, manifest lists, and data files.

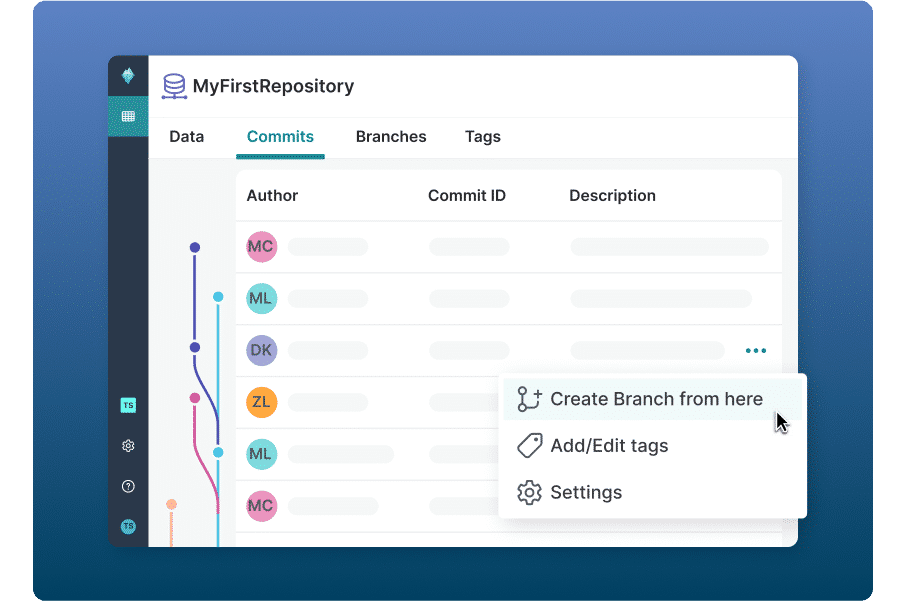
Git-inspired versioning for virtual data isolation, experimentation, and quality
Use Git-like branching to support development, test, and production use cases on the same Iceberg lakehouse environment without creating physical copies of data. Experiment and make changes to data without disrupting production workloads, instantly expose changes to users. Easily roll back from mistakes.
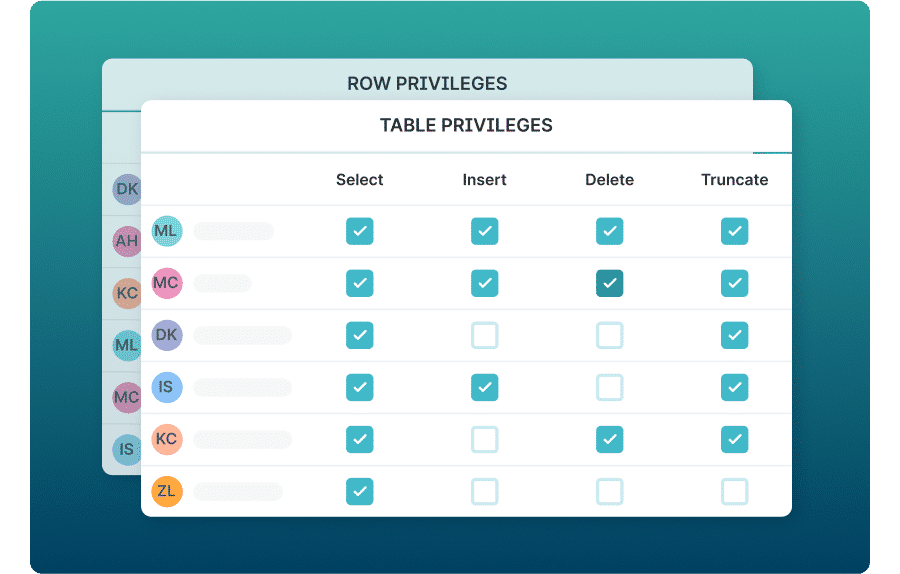
Centralized Data Governance for Apache Iceberg Data Catalog
Simplify and scale data governance with secure access to data using Role-Based Access Control (RBAC) privileges. Easily audit who made changes and when using a built-in commit log.
customer stories


