What Is AWS Glue?
AWS Glue is a fully managed extract, transform and load (ETL) tool that automates the time-consuming data preparation process for consequent data analysis. AWS Glue automatically detects and catalogs data with AWS Glue Data Catalog, recommends and generates Python or Scala code for source data transformation, provides flexible scheduled exploration, and transforms and loads jobs based on time or events in a fully managed, scalable Apache Spark environment for data loading in a data target. The AWS Glue service also provides customization, orchestration and monitoring of complex data streams.
AWS Glue Architecture
AWS Management Console
- Defines AWS Glue objects such as crawlers, jobs, tables, and connections
- Sets up a layout for crawlers to work
- Designs events and timetables for job triggers
- Searches and filters AWS Glue objects
- Edits scripts for transformation scenarios
AWS Glue Data Catalog
AWS Glue Data Catalog provides centralized uniform metadata storing for tracking, querying and transforming data using saved metadata.
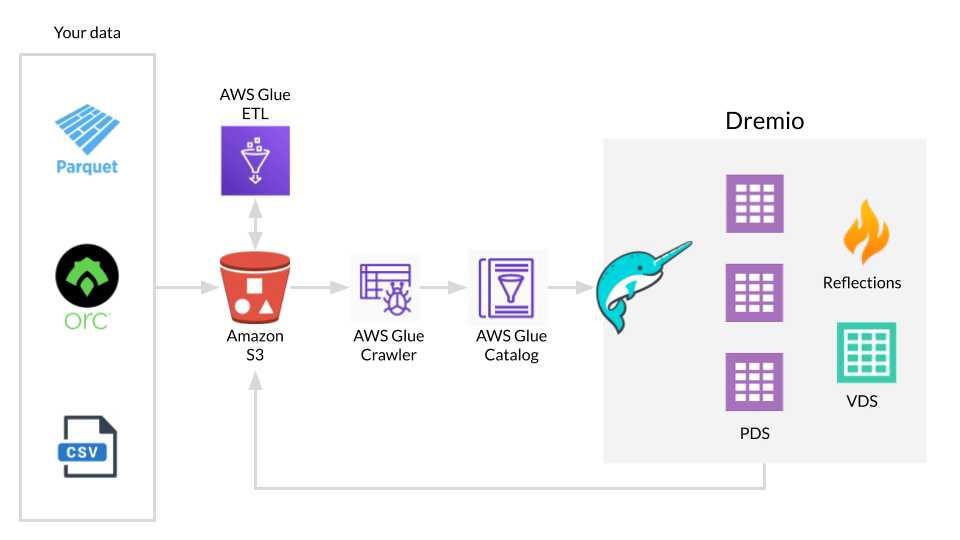
Creating a Cloud Data Lake with Dremio and AWS Glue
Read the Tutorial
AWS Glue Crawlers
Crawlers and classifiers scan data from different sources, classify data, detect schema information and store metadata automatically in AWS Glue Data Catalog.
AWS ETL Operations
The ETL program core provides Python or Scala code generation for data cleaning, enrichment, duplicate removal and other complex data transformation tasks.
Job Scheduling System
A flexible scheduling system starts jobs based on various events or by timetable.
AWS Glue Core Features and Components
AWS Glue Data Catalog
AWS Glue Data Catalog is a metadata repository that keeps references to your source and target data. The Data Catalog is compatible with Apache Hive Metastore and is a ready-made replacement for Hive Metastore applications for big data used in the Amazon EMR service.
AWS Glue Data Catalog uses metadata tables to store your data. You append the table to the database when you set it in the Data Catalog. A table can be stored in one database and each table represents a single data store only.
Data from different data stores like Amazon S3 and Amazon RDS can be defined in these tables. When you create a table manually or run a crawler, the database is created. In the AWS Glue management console you can view tables from selected databases, edit database descriptions or their names and delete databases. You can also manage databases and tables in Data Catalog via AWS Glue API and AWS Command Line Interface (CLI).
To define Data Catalog objects such as databases, tables, partitions, crawlers, classifiers and connections, you can use AWS CloudFormation templates that are compatible with AWS Glue. The Data Catalog can also keep resource links to local or shared databases and table resource links. You can use these resource links in cases where you use database names.
The Data Catalog also contains information about connections to particular data stores, a feature called AWS Glue Connections. Connections stores URI strings, authorization credentials, virtual private cloud info and so on.
Automatic Schema Discovery
When you run crawlers, the classifiers are triggered. You can use built-in classifiers or set up custom classifiers to specify the appropriate schema to categorize your data sources. Custom classifiers first run in your specified order. If a custom classifier detects the format of your data, it automatically generates a schema. Otherwise, built-in classifiers are invoked to define the schema, format and properties associated with raw data. Then crawlers group the data into tables or partitions and write metadata to the Data Catalog. In the configuration, you can specify how the crawler adds, deletes or updates tables or partitions. When the crawler scans Amazon S3 and detects multiple folders in a bucket and schemas are similar at a folder level, it creates two or more partitions in a table instead of separate tables.
To update table schema you can rerun the crawler with an updated configuration or run ETL job scripts with parameters that provide table schema updates.
AWS Glue provides classifiers for different formats including CSV, JSON, XML, weblogs (Apache logs, Microsoft logs, Linux Kernel logs, etc.) and many database systems (MySQL, PostgreSQL, Oracle Database, etc.). Compressed files can only be classified in formats including ZIP, BZIP, GZIP and LZ4.
Code Generation and Customization
When you create a job in a console, you specify a data source with one or more required connections and data targets that are represented in tables defined in the Data Catalog. You also point to the job processing environment by providing arguments, describing scenarios when jobs are invoked. Based on your inputs, AWS Glue automatically generates PySpark or Scala scripts to perform ETL tasks. You can also write your own scripts using AWS Glue ETL libraries, edit existing scripts in the built-in AWS console, and edit to fit your business needs, and import scripts from external sources, for example from GitHub. AWS Glue provides flexible tools to test, edit and run these scripts. You can use Python or Scala for scriptwriting. In addition to this, you can also import your own libraries and Jar files in the AWS Glue ETL task.
AWS Glue provides a specific environment — known as a development endpoint — to develop and test, extract, transform and load (ETL) scripts. To create a development endpoint you need to specify network parameters to access data stores securely. Later you can create, debug, test and add new functions using the so-called notebook interactively to generate scripts that satisfy your needs to perform ETL tasks. You can create, edit and delete development endpoints in the AWS Glue console or use the AWS Glue API. Data Preparation (Cleaning and Deduplicating)
AWS Glue provides data transformation tasks based on machine learning (ML) solutions. At the moment, only FindMatches transformation is available. ML transformation solves issues with record binding and deduplication. For example, you can link customer records across various databases even in cases where records have different entries and do not match exactly (misspelled names, addresses that don’t match, incorrect data, etc.). ML transformation also finds duplicate records where the records have no common unique key. You can clean your data source with a FindMatches transformation job that can find duplicates. You can label your example dataset as matching and not matching to “teach” ML transformation. You can also download, label and upload the labeled file to create a better transformation. With this tool you are also able to import, export, generate labels and estimate the quality of ML transformation. ML transformations can be saved and run later in the ETL script.
API for Developers
The AWS Glue API provides additional tools for developers to work with the AWS Glue service effectively. You can interact with AWS Glue using different programming languages or CLI. AWS Glue API provides capabilities to create, delete, list databases, perform operations with tables, set schedules for crawlers and classifiers, manage jobs and triggers, control workflows, test custom development endpoints, and operate ML transformation tasks. AWS Glue API also has an exception section that you can use to localize the problem and fix it.
Job Scheduler
To start ETL jobs manually or automatically you can create Data Catalog objects called triggers. You can set a chain of job-dependent triggers based on the time schedule, a combination of events or on demand. Time-based schedules use a Unix-like cron syntax. You can specify a day of the week, time and day of the month to trigger an ETL job or set of jobs. You can define constraints for job triggers. You also need to consider the features and limits of cron. Job triggers based on events are actuated when they meet a list of conditions. You can specify the status for previous jobs like success, time out and failure, as a condition for triggering an ETL job. You can add triggers or a set of triggers for ETL jobs, and activate and deactivate these triggers using AWS Glue console, AWS Glue API or AWS CLI.
Ability to Work with Data Streams
AWS Glue supports ETL operations with data streams from Amazon Kinesis Data Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK) and loads the results into Amazon S3 data lakes or JDBC data stores. Just add data streams to Data Catalog and then choose it as the data source when you set up ETL jobs.
Supported Data Sources
AWS Glue provides built-in support of data stored in Amazon Aurora, Amazon RDS for MySQL, Amazon RDS for Oracle, Amazon RDS for PostgreSQL, Amazon RDS for SQL Server, Amazon Redshift, DynamoDB and Amazon S3. It also supports MySQL, Oracle, Microsoft SQL Server databases and PostgreSQL on Amazon Virtual Private Cloud (Amazon VPC). AWS Glue also supports data streams from Amazon MSK, Amazon Kinesis Data Streams and Apache Kafka. You can create scripts using Python or Scala and import custom libraries and Jar files to AWS Glue ETL jobs to get access to data sources that have no built-in AWS Glue support.
Advantages of AWS Glue
- Serverless and scalable - AWS Glue is a fully managed service that scales up or down based on the workload, eliminating the need for infrastructure management and reducing costs.
- Easy to use - AWS Glue provides a user-friendly interface for defining and running ETL jobs, making it accessible to developers and data engineers of all skill levels.
- Centralized metadata catalog - The AWS Glue Data Catalog provides a centralized location for managing metadata about data assets, making it easy to discover and query data across different sources.
- Integrates with other AWS services - AWS Glue integrates seamlessly with other AWS services, such as Amazon S3, Amazon Redshift, and Amazon EMR, allowing you to build complex data workflows that span multiple services.
- Supports a variety of data formats - AWS Glue can handle a wide range of data formats, including structured, semi-structured, and unstructured data, making it a versatile solution for ETL.
Disadvantages of AWS Glue
- Limited control over resources - Because AWS Glue is a fully managed service, users have limited control over the underlying infrastructure, which can make it difficult to optimize performance for specific use cases.
- Limited customization - While AWS Glue provides a range of built-in transformations and connectors, users may find that they need to write custom code to handle specific data formats or use cases.
- Limited debugging capabilities - Debugging ETL jobs in AWS Glue can be challenging, as there is limited visibility into the underlying code and infrastructure.
- Cost - While AWS Glue is generally cost-effective compared to traditional ETL solutions, costs can add up if you have a large volume of data or complex data workflows.
Use Cases of AWS Glue
Data integration - AWS Glue can be used to integrate data from multiple sources, such as databases, data lakes, and data warehouses. It can also be used to combine structured and unstructured data.
Data transformation - AWS Glue can transform data into a format that is optimized for analysis, such as converting data from one schema to another or aggregating data into a summary table.
Data cleansing - AWS Glue can be used to clean and validate data by removing duplicates, correcting errors, and ensuring that data is consistent and accurate.
Data enrichment - AWS Glue can add additional information to data sets by combining data from different sources or by using machine learning models to generate insights.
Data cataloging - AWS Glue can be used to create a centralized catalog of metadata for data assets, making it easier to discover, analyze, and govern data.
Conclusion
AWS Glue is a serverless, cost-effective service that provides easy-to-use tools to catalog, clean, enrich, validate and move your data for storage in data warehouses and data lakes. AWS Glue can effectively operate with semi-structured and stream data. It is compatible with other Amazon services, can combine data from different sources, provides centralized storage, and prepares your data for the next phase of data analysis and reporting. Dremio provides seamless integration with the AWS Glue service and ensures a high-performance and high-efficiency query engine for fast and easy data analytics at the lowest cost per query.Visit our tutorials and resources to learn more about how Dremio can help you gain insights from your data stored in AWS.

