9 minute read · November 15, 2022
What is a Semantic Layer?

· Senior Product Marketing Manager, Dremio


A semantic layer is a business representation of corporate data for your end users.
The semantic layer sits between the data store and consumption tool. It is a self-service data layer to explore and access data using business-friendly terms that make sense to end users. This helps them do things like creating meaningful dashboards without needing to understand the underlying data structure. It encourages collaboration between teams. Data is consistent and simplified through business context.
As a concept, the semantic layer empowers end users to become decision-makers with analytics.

A semantic layer is not:
- a replacement for a data lakehouse
- an alternative for a data transformation or BI tool
- an OLAP cube or aggregation layer
Why Use a Semantic Layer?
End users need access to data stored across on-premises data centers, local machines, and applications in the cloud.
The data warehouse is used in the data layer serving as a central repository of corporate data. The purpose of a semantic layer is to expose a business representation of an organization’s data assets so that it can be accessed using common business terms. End users want to understand this data without being exposed to the technical complexities of data infrastructure. For example, data engineers will create table definitions such as DimProduct, with columns ProductID and ProductSourceName. To an end user, the underlying data definitions can be hard to interpret without business context. With a semantic layer, the table DimProduct becomes Product, and the column ProductSourceName becomes ProductName. This simplifies technical jargon so it becomes easier for end users to understand and share datasets.
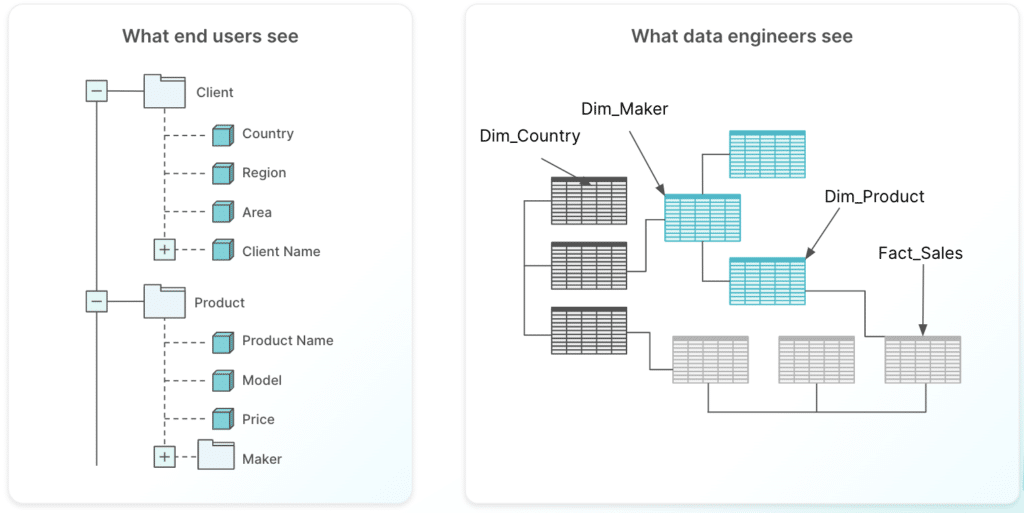
Semantic Layer vs. Data Marts vs. OLAP Cubes
Now that we’ve set a baseline for what a semantic layer is, we’ll review common ways organizations implement a semantic layer.
Data Marts
Data marts are curated subsets of the data warehouse. Data marts are designed to deliver domain-specific information to specific business units.
Challenges with Data Marts
A limitation of data marts is their dependency on the data warehouse. Slow and bombarded data warehouses are often the reason for creating data marts. The size of a data warehouse is typically larger than 100 GB and often more than a terabyte. Data marts are designed to be less than 100 GB for optimal query performance.
If a line of business requires frequent refreshes on large data marts, then that introduces another layer of complexity. Data engineers will need more ETL pipelines to create processes ensuring the data marts are performant.
Now that your data mart is less than 100 GB, what happens if end users request data outside the context of the data warehouse?
Many organizations have data sources that have to stay on-premises or reside in another proprietary data warehouse across different cloud providers. This makes it hard for end users to do ad-hoc analysis outside the context of the data warehouse. Business units create their own data marts, resulting in data sprawls across the enterprise - a data governance nightmare.
OLAP Cubes
In addition to planned queries and data maintenance activities, data warehouses may also support ad hoc queries and online analytical processing (OLAP). An OLAP cube is a multidimensional database that is used for analytical workloads. It performs analysis of business data, providing aggregation capabilities and data modeling for efficient reporting.
Challenges with OLAP Cubes
OLAP cubes for self-service analytics can be unpredictable because the nature of business queries is not known in advance. Organizations cannot afford to have analysts running queries that interfere with business-critical reporting and data maintenance activities. Because of this, datasets required to support OLAP workloads are extracted from the data warehouse, and analysts run queries against these data extracts.
OLAP cube’s dependency on the data warehouse poses many challenges.
As extracted datasets from the data warehouse, OLAP cubes require an understanding of the underlying logical data model. In many cases, massive amounts of data are ingested into memory for analytical queries, incurring expensive computing bills. Because the data extracts are a snapshot in time of the data warehouse, it offers limited interaction with the data until the OLAP cubes are refreshed. Depending on the workload, it’s not uncommon for cubes to take hours for data refresh.

What is the solution?
Most organizations prefer to have a single source of enterprise data rather than replicating data across data marts, OLAP cubes, or BI extracts. Data lakehouses solve some of the problems with a monolithic data warehouse, but it’s only part of the equation. A unified semantic layer is just as important.
Your unified semantic layer is a mandatory component for any data management solution such as the data lakehouse. Some benefits include
- A universal abstraction layer. Technical fields from facts and dimensions tables are transposed into business-friendly terms like Last Purchase or Sales.
- Prioritizing data governance. A unified semantic layer makes it easy for teams to share views of datasets in a consistent and accurate manner, meaning only users with provisioned access can see the data.
- All your data. Your end users need self-service to new data. You don’t want to spend more time creating ETL pipelines with dependencies on proprietary systems. Consume data where it lives.
Next steps
It’s clear that a semantic layer can help an organization integrate data for BI users. Bringing self-service analytics to your organization should be easy.
Ready to see how Dremio enables self-service analytics across all your data? Check out how organizations are enabling no-copy data marts with Dremio’s unified semantic layer.
Additional resources you may find helpful
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->