Intro
Elasticsearch features a powerful scale-out architecture based on a feature called Sharding. As document volumes grow for a given index, users can add more shards without changing their applications for the most part. Another option available to users is the use of multiple indexes. Given 1 billion documents, is it better to use multiple shards or multiple indexes? Each approach can be valid, and each presents different tradeoffs. Sometimes the best option is to model your data across multiple indexes. Fortunately, Elasticsearch makes it easy to write queries if you’re using a single index, or if you’re using many. In this tutorial we’ll show you how to take advantage of the ability to query across multiple indexes using SQL and Dremio. The good news is that Dremio inherits Elasticsearch’s flexibility in this regard, while giving your all the power and simplicity of SQL for analytics.
Assumptions
For this tutorial we assume you’re familiar with Elasticsearch and know how to load data into your cluster. We recommend you first read Getting Oriented to Dremio and Working With Your First Dataset. We will build off some of the examples in Compiling SQL to Elasticsearch Painless, but you should be able to follow along even if you haven’t worked through all of the examples in that tutorial.
Why Multiple Indexes
There are several reasons you might be using multiple indexes for a given application in your Elasticsearch cluster. One of the most popular is the fact that deleting an index is very efficient (whereas deleting many documents is much less so). This is useful if your application is adding and removing data frequently. For example, if your application keeps data “hot” in Elasticsearch for the most recent 100 days, you might partition your data as a single index for each week. This approach makes rolling a week of data out of your cluster very efficient, with the modest tradeoff of searching across ~15 indexes to query all 100 days.Another example is multi-tenant applications (eg, a Gmail-like app), where each user’s data is stored in a single index. This allows you to scale each index independently.In cases where you need to query multiple indexes, Elasticsearch makes this easy by allowing you to specify the “scope” of your search to include multiple indexes, either as a comma-delimited list, or based on a regular expression, or other convenient options as well.Assuming a scheme that uses one index per week, here are some examples, searching for documents with a tag of “dremio”:
# search a specific index curl -XGET 'localhost:9200/2017-week47/_search?q=tag:dremio' # search specific year curl -XGET 'localhost:9200/2017-*/_search?q=tag:dremio' # search a specific week across all years (eg, holidays) curl -XGET 'localhost:9200/*-week51/_search?q=tag:dremio' # search across all weeks curl -XGET 'localhost:9200/_all/_search?q=tag:dremio' # search across all weeks, except Christmas week curl -XGET 'localhost:9200/+_all,-*week51/_search?q=tag:dremio' # In case you are using types, the same idea applies to types: # search across users and orders, for all weeks, except Christmas week curl -XGET 'localhost:9200/+_all,-*week51/users,orders/_search?q=tag:dremio'
What’s great is that most of these options are supported in Dremio, let’s take a closer look.
Mapping SQL Concepts to Elasticsearch
If you’re coming from the traditional world of relational databases, it can be helpful to think about how the core data model of Elasticsearch is similar to that of SQL, and how it is different. Here are several of the high-level concepts:
| Relational | Elasticsearch |
| Schema | Mapping |
| Database | Index |
| Table | Type |
| Row | Document |
| Column | Field |
| SQL | DSL+Painless |
| Aggregation | Aggregation |
| Projection | Projection |
| Boolean | Boolean |
| Primary Key | _id Field |
| Join | Does not exist |
| Foreign Key | Does not exist |
Using The Elasticsearch Syntax In SQL
Dremio uses a hierarchical namespace for all datasets. When Elasticsearch is the source, this follows the pattern of source.index.type. For example, if you follow the tutorial for loading Yelp data in Compiling SQL to Elasticsearch Painless, the Yelp data is stored in a single index with multiple types:

Following the hierarchical namespace model, each dataset has the following name:
- ES.yelp.business
- ES.yelp.checkin
- ES.yelp.review
- ES.yelp.user
We also just happen to have other indexes and types in this cluster:
- ES.bank.account
- ES.shakespeare.act
- ES.shakespeare.line
- ES.shakespeare.scene
With this in mind, the following queries are all valid in Dremio:
/* Select all records from the index.type "yelp.business" */ SELECT * FROM ES.yelp.business /* Select all records from any index that beings with "y" and a type of "business" */ SELECT * FROM ES."y*".business /* Select all records from any index that beings with "y" and a type of "business" OR "user" */ SELECT * FROM ES."y*"."business,user"
A few things to note:
- the expression for index or type needs to be in double quotes if you’re using wildcards or a delimited list.
- you can use wildcards for the index but not the type (let us know on you think wildcards in type are important)
- you cannot use + and - for index or type
What About Querying Different Mappings Across Indexes and Types?
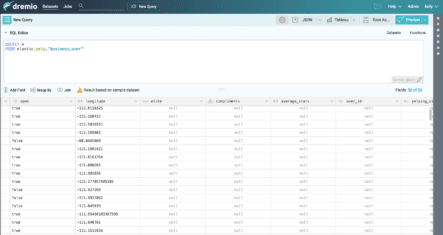
The ability to query across multiple indexes is especially useful when you have the same mapping. In this case, the query is essentially performing a UNION over all the matching indexes, which makes sense because they follow the same sense of schema. If you issue a query that spans multiple indexes or types with different schemas, what happens then? Dremio will use its schema learning engine to determine a schema that includes columns from all matching indexes or types. When this happens the results might be fairly sparse. For example, if you query the business and user types in the Yelp index, the results look something like this:

The first rows are all businesses, so their columns for elite, compliments, average_stars, user_id are all null. This makes sense because these columns correspond to fields from the user type and don’t apply to businesses. However, all documents have _index, _type, and _uid because this is true for all records in both types.
Aliases Work Too!
Another nice feature of Elasticsearch is the ability to assign one or more indexes to an aliases. This gives you a level of indirection between your physical indexes and the “view” your users have of the data for an application. In many ways this is similar to a view in a relational database.Going back to our example of keeping the most recent 100 days of data hot, you could create an alias over the appropriate indexes:
curl -XPOST 'localhost:9200/_aliases?pretty' -H 'Content-Type: application/json' -d'
{
"actions" : [
{ "add" : { "index" : "2017-week1", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week2", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week3", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week4", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week5", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week6", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week7", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week8", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week9", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week10", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week11", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week12", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week13", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week14", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week15", "alias" : "recent-100" } }
]
}'Then, as each week passes, you would periodically update the alias to add a new week, and remove a week that is rolling off:
curl -XPOST 'localhost:9200/_aliases?pretty' -H 'Content-Type: application/json' -d'
{
"actions" : [
{ "remove" : { "index" : "2017-week1", "alias" : "recent-100" } },
{ "add" : { "index" : "2017-week16", "alias" : "recent-100" } }
]
}'These operations are efficient and transparent to your application, which makes this approach very useful.
From the perspective of Dremio, an alias is no different from a table. It will show up in Dremio’s catalog in exactly the same way. You can’t alias a type in Elasticsearch, but if you alias an index with one or more types, they come along for the ride. For example, if you add an alias to the Yelp index:
curl -XPOST 'localhost:9200/_aliases?pretty' -H 'Content-Type: application/json' -d'
{
"actions" : [
{ "add" : { "index" : "yelp", "alias" : "test-alias" } }
]
}'Now when you look at the available indexes for this data source, ‘test-alias’ shows up.

If you double click, you’ll see the same types available under ‘yelp’.
Also note that you can effectively accomplish the same thing using Dremio’s virtual datasets.
Conclusion
It is common to use multiple indexes when modeling data in Elasticsearch. Dremio makes it easy to take advantage of Elasticsearch’s flexibility to scope queries to one or more indexes when analyzing data via SQL. In this tutorial we’ve taken a look at examples of the Elasticsearch DSL and how those can be expressed in SQL. This opens up BI tools, Python, R, and many other languages and tools that support SQL to take advantage of the data stored in Elasticsearch clusters.




