27 minute read · July 7, 2022
The Origins of Apache Arrow & Its Fit in Today’s Data Landscape
· Developer Advocate, Dremio

The data landscape is a constantly changing one. We started with relational databases to store and process transactional data that was generated by a business’s day-to-day operations (e.g., customer, order details) to serve OLTP use cases. Then, with the rising need to derive analytical insights from a business’s stored data (e.g., average sales over time), we moved onto OLAP-based systems with data warehouses and data lakes as sources.
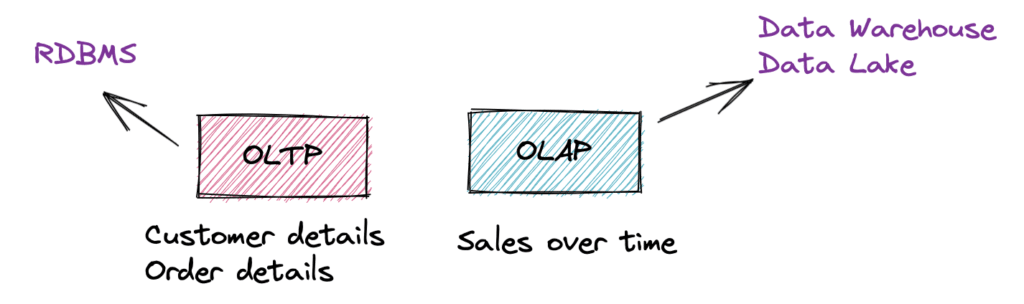
Figure 1: OLTP and OLAP
As the volume and speed at which the data was being generated surged, we had to rely on systems that could enable large-scale and cost-efficient data processing and storage. Apache Hadoop opened up that scope and brought along a gamut of tools to satisfy a variety of use cases. For instance, Apache Hive made it possible to read, write, and manage large datasets residing in HDFS using SQL-like syntax. Similarly, Apache Drill, a distributed SQL engine, was designed to enable data exploration and analytics on non-relational data stores.
Row or Column?
With the ability to store and process large datasets, performance became a focus to facilitate faster analytical workloads. A critical angle to this was to address how exactly the data was stored — either by row or column? Columnar formats provide a significant advantage compared to row-based ones by keeping all of the data associated with a column adjacent to each other, thereby limiting the amount of data that needs to be fetched by accessing the relevant columns (for a query).
Apache Parquet is an open source columnar file format that has experienced wide adoption from the Hadoop days to present-day cloud data lakes (such as Amazon S3) due to its efficient storage, compression, and faster access patterns with analytical queries.
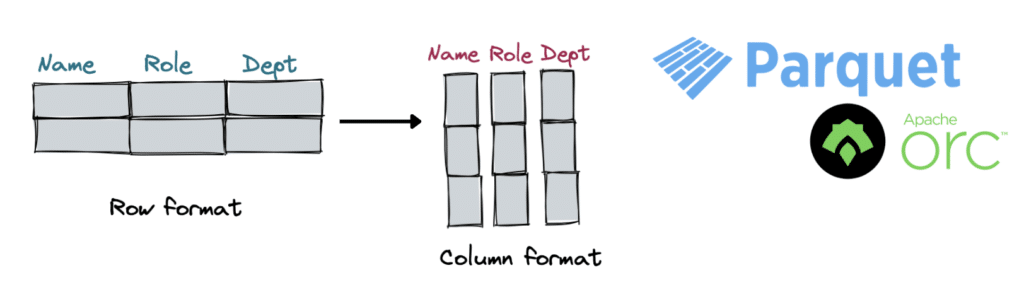
Figure 2: Row vs. columnar file formats
In-Memory Compute
Over the years, memory has become less expensive, and the need for low-latency analytics (e.g., BI) has only increased. This has allowed us to seek faster processing alternatives — one that involves storing more data in memory for both transient and persistent storage for processing instead of only relying on disks. With in-memory processing, we have the data directly in the system memory, thus avoiding transferring data from the disk to memory and having to wait.
While various processing engines embraced in-memory computing for working with a larger volume of data, one area that wasn’t focused on at that time was “interoperability” between the systems (i.e., transporting data from one system to another).
Lack of a Standard
Take a look at the representation below. As you can see, many “copy & convert” operations happen among these systems, making this representation look overly complex. Let us understand this in some more detail.
Figure 3: Pre-Arrow world
Imagine you have to read some data (i.e., numerical) stored in a Parquet file format in Amazon S3, and you want to use Spark’s Python API , PySpark. To do this, you first need to copy the bytes from one system’s memory into another, and at the same time you have to convert them into your native memory representation of data (one that PySpark can understand).
These two operations are shown in the image above. The crux of this problem is that Parquet represents “number” in a way that is different from how Python does; therefore, for PySpark to use the data, it needs to be converted into its internal in-memory data structure. The process where you re-create the object from the byte stream is referred to as “deserialization.”
As you might have realized by now, every time we need to move data from one system to another, a “copy & convert” operation must be run. This comes with a considerable cost and performance factor, and these factors only multiply with larger datasets. So, instead of every engine implementing its own internal in-memory formats, what if there was a standard way of representing the data in memory?
Interoperability Issue – Programming Languages & Tools
The performance caveats that originate from the data interoperability issues (serialization, deserialization) discussed above can also be seen between programming languages. For example, languages such as Python and R have proven to be established tools in the data science space.
For instance, Pandas —a data analysis and manipulation tool—needs no introduction. Pandas offers a data structure called “DataFrame,” which is extensively used to deal with tabular data. Similarly, in the R world, data frames are made intrinsically available. As you can see from the code snippets below, the way to leverage data frames is basically the same in both environments.
However, can you use the data frame created in Python in the R environment? Unfortunately, no! Since Pandas’ way of representing data frames is different from R’s internally, you cannot possibly do so without experiencing considerable transport cost. Instead, it would be best to establish a standard in-memory format that both environments can understand.

Figure 4: A data frame in both Python (Pandas) and R
Another problem that arises is that for any large-scale analytics workload (involving massive datasets), typically, data scientists or analysts rely on server-side MPP (massively parallel processing) systems for powerful computing resources and data. However, a lot of computation today also happens on the client-side using tools like Python and its ecosystem. For instance, you can use Python code to issue some SQL to a compute engine like Dremio for at-scale SQL processing and use the resulting data to build an ML (machine learning) model. This involves moving the data from the server to the client before analyzing or building models using it. Therefore, an efficient transfer protocol is imperative for this use case.
To recap, we have discussed the changes in the data landscape, how columnar file formats help with faster access patterns when dealing with large datasets, and how in-memory computation enables speed to insights by bringing data close to memory. We also talked about the interoperability issues when moving data from one system to another or when working with various programming languages/engines. Fortunately, each of these issues can be solved with a standard in-memory representation that multiple systems can adopt to improve efficiency with data interchange.
Origin and History of Apache Arrow
Back in 2015, Jacques Nadeau, the co-founder of Dremio (a SQL-based data lake engine and platform), came across similar “data transport” problems and had been thinking about ways to address it during his time at Dremio by utilizing a standard columnar in-memory format. At the same time, there was a huge interest for columnar in-memory processing from many other folks involved in the other big data projects such as Apache Drill, Impala, Calcite, etc.
Wes McKinney,creator of Pandas, had also been thinking about making Python interoperable with large-scale data processing systems like Apache Impala and Spark and noted that it was extremely expensive to move large tabular datasets from one process memory space to another. As a result, having a productive experience when working with both these systems and Python (Pandas) was quite tricky.
One of the other problems (and a driving factor) that both Jacques and Wes realized early on was how developers, with every project, were trying to reinvent the wheel to represent columnar data efficiently in memory and be able to operate on that data. For instance, projects that enabled doing operations on the data, such as adding the values of two columns, had to build most of it from scratch specific to their system and then optimize the implementations to represent them efficiently in memory. Other projects that wanted to achieve similar functionalities had to do a completely new implementation … and it goes on. So, the focus really was to have a one standardized representation for columnar in-memory data.
Figure 5: Apache Arrow
Since the key problem that Jacques and Wes were trying to solve was common, i.e., how to effectively transport data between the various systems, and there were similar interests in the industry, they started to consult and recruit other open source leaders from projects such as Impala, Spark, Calcite, etc. to create a new Apache project. After a round of votes on the formal name of the project (check out the ballot with alternate names such as Honeycomb and Keystone), the project was finally named “Arrow.”
Meet Apache Arrow 🏹
Apache Arrow started as a columnar in-memory representation of data that every processing engine can use. Arrow by itself is not a storage or execution engine but serves as a language-agnostic standard for in-memory processing and transport. In fact, it started as Dremio’s in-memory representation of data. For example, using Arrow, Python, and R, accessing a dataset will have the exact representation in memory. So this means that when two systems “speak” Arrow, there is no extra effort to serialize and deserialize data when transporting it across systems. This is what makes Apache Arrow a language-agnostic in-memory format.
For a holistic view, take a look at the representation below. Arrow acts as a shared foundation for data science tools such as Pandas and Spark, SQL execution engines such as Dremio and Impala, and storage systems such as Cassandra. In contrast to Figure 3, where a “copy & convert” operation runs every time we move data from one system to another, adopting Arrow results in a zero-copy design.
Figure 6: Post Apache Arrow World
Another facet of how Arrow achieves compelling performance is by efficiently using modern-day CPUs. Arrow organizes data in a way that makes it possible to leverage SIMD (single instruction multiple data) instructions, thus giving the advantage of running an algorithm in a single clock cycle. Arrow also uses memory mapping of its files to load only the required and possible data into the memory. This means that any engine leveraging Arrow doesn’t need to reinvent the wheel—if they’re using Arrow, they get this benefit out of the box.
Today, Apache Arrow is the de facto standard for efficient in-memory columnar analytics. It essentially provides a software development platform that allows developers to use Arrow and build high-performance applications that process and transport large datasets. Arrow libraries allow you to work with data in the Arrow columnar format in more than 10 languages, including C++, Java, JavaScript, R, Python, etc. The use cases range from reading/writing columnar storage formats (e.g., Pandas uses it to read Parquet files), using it as an in-memory data structure for analytical engines, moving data across the network, and more. These use cases have been driving massive adoption of Arrow over the past couple years, thereby making it a standard. For instance, the Arrow Python language binding, PyArrow, has seen an increasing number of downloads over the years.
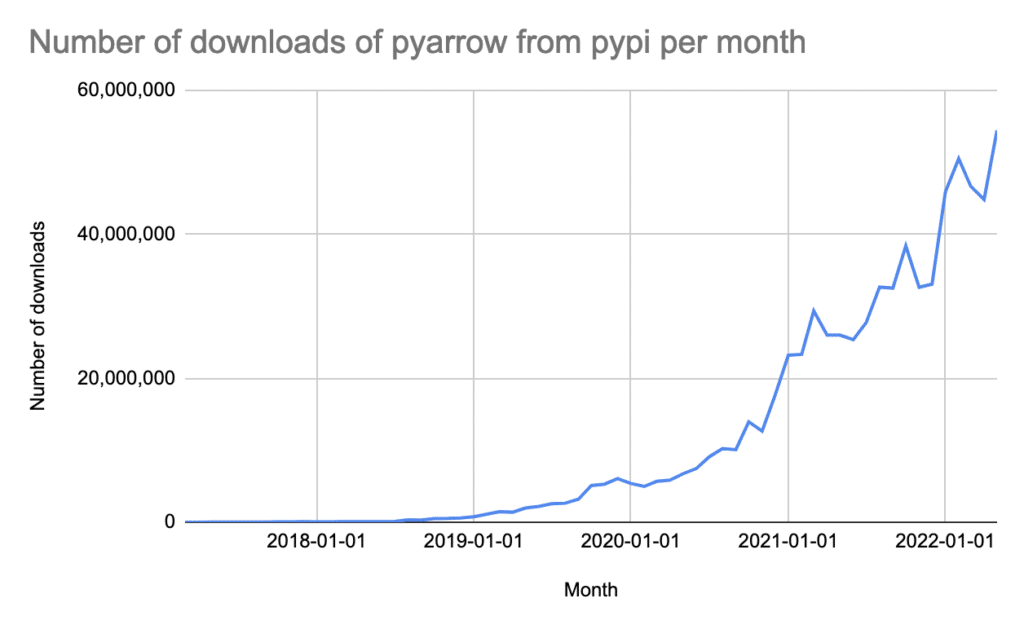
Figure 7: PyPi number of downloads of PyArrow
The Ecosystem
Arrow’s ecosystem is rapidly growing, and there are already a large number of projects that have benefited from leveraging Arrow. One exciting aspect of the Apache Arrow project is its diverse applications in today’s data landscape, specifically its robust capability for various analytical use cases. This section first looks at some of the new capabilities within the project, followed by a couple of libraries/tools that are built on Arrow or have adopted Arrow.
Capabilities/Sub Projects
Arrow Flight
Arrow Flight is a high-performance client-server framework for sending “Arrow” data over the network that was developed by Dremio, Ursa Labs (now Voltron Data Labs), and Two Sigma as part of the Arrow project. To clarify, Arrow serves as the standard in-memory data format, and Arrow Flight is the protocol to move such data across a network.
Figure 8: Arrow and Arrow Flight for data transfer
Some of the key benefits of Arrow Flight include:
- Multi-language support – Flight ships with Arrow libraries in Python, Java, Rust, etc.
- Parallelism – Flight enables parallel transfer of data while other data transfer frameworks such as ODBC do not.
- No serialization or deserialization costs – Since Arrow data is sent directly, there is no need to serialize or deserialize the data, and no need to make an extra copy of the data.
- Security – Flight is built on top of gRPC and uses its built-in TLS/OpenSSL capabilities for encryption. By default, it also comes with a built-in BasicAuth.
You can read more about these capabilities here.
A real-world application of the Arrow Flight framework is the Arrow Flight-based connector developed by Dremio that beats ODBC by 20-50x without parallelism.
Gandiva
Gandiva is a high-performance execution kernel for Arrow developed by Dremio and contributed to the Apache Arrow project. Gandiva, based on LLVM, provides just-in-time compilation abilities to generate highly optimized assembly code on the fly for faster execution of low-level operations such as sorts, filters, etc. Gandiva is catching momentum, and already offers bindings for languages such as C++ and Java. It is used in production as part of Dremio’s SQL engine to attain performance improvements for analytical workloads.

Figure 9: Gandiva initiative – Apache Arrow
Libraries/Tools
PyArrow
PyArrow is the Python API of Apache Arrow. It was downloaded 52 million times in May 2022 and is a popular library for Python folks in the data science space. To install PyArrow, refer to the instructions here.
To understand the performance differences, let’s try reading a CSV file with 11 million records and compare Pandas CSV reader (default engine) with PyArrow’s.

Figure 10: PyArrow vs. Pandas CSV reader
PyArrow does it 15x faster with Arrow’s in-memory columnar format!
Also, if you want to interface with Pandas, PyArrow provides various conversion routines to consume Pandas structures and convert them back to Arrow easily. See below.
Figure11: Pandas to Arrow and vice versa
Dremio
Dremio is an open lakehouse platform. It presents a SQL-based distributed query engine for data lakes called “Sonar” that is built on Arrow and leverages it end to end. As data is accessed from different sources, Dremio reads the data into native Arrow buffers directly, and all processing is performed on these buffers. This enables robust query performance, and along with many performance features, empowers companies to run mission-critical BI directly on the lakehouse.

Figure 12: Dremio Sonar – The SQL Engine
As an example, take a look at this Tableau dashboard. Here, Dremio is used to connect with Tableau natively and query the dataset from S3 lake storage, which has ~338 million records.
Figure 13: Tableau using Dremio to do analysis on 338M records
For perspective, loading such a vast amount of data in Tableau directly would take significantly more time. In a traditional BI world, this would mean making many data copies to get it into a data mart so you can make some improvements. However, with Dremio’s engine (supported by Arrow), building a chart and analyzing it is blazing fast, and you have a no-copy architecture! In fact, most of the queries took ~4 secs with raw reflections (a query acceleration method on a set of rows/columns) and some were sub-seconds with aggregated reflections (query acceleration on BI-style queries).
The best part? Dremio is free. You can get started here.
Streamlit
Streamlit provides a faster way to build web apps for machine learning and data science teams. In the past, Streamlit accepted data frames as inputs and they had to be sent over the wire to a JavaScript environment. So, a lot of serialization and deserialization were happening within the platforms and they had a custom code (Protobufs) to do that.
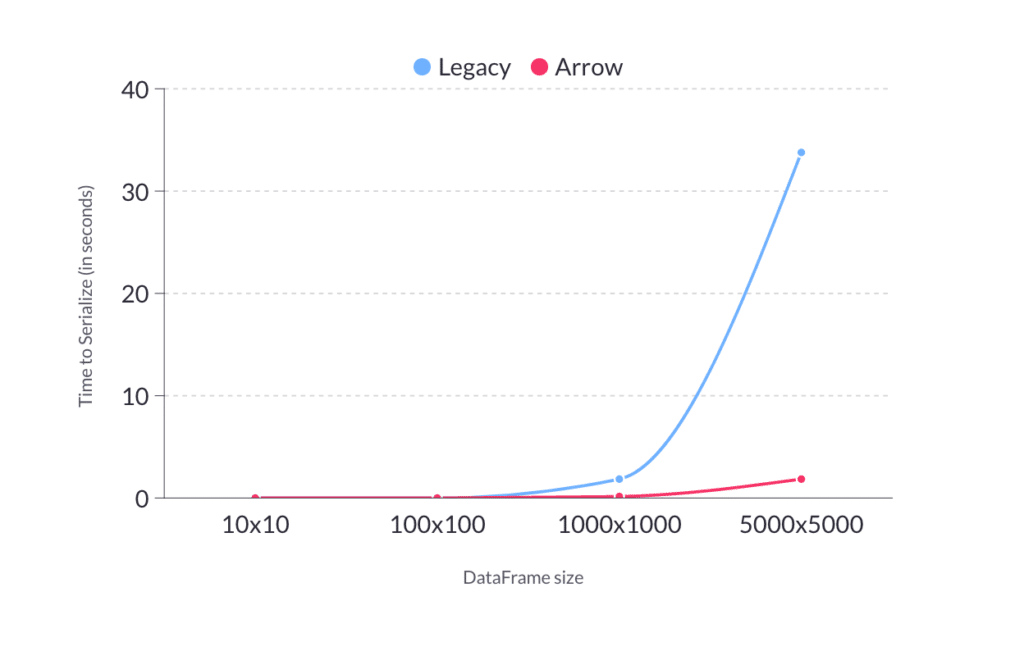
Figure 14: Time to serialize Vs DataFrame size shared by Streamlit
Last year, Streamlit shared how they made significant performance improvements by adopting Apache Arrow for their serialization problem. Read more about how they’re all-in on Apache Arrow here.
Apache Spark
Apache Spark is an open source unified analytics engine for large-scale data processing and machine learning. Spark leverages Apache Arrow in its Python API, PySpark to efficiently transfer data between JVM and Python (non-JVM) processes. This is primarily beneficial for Spark users who prefer working with Pandas in a Python environment.

Figure 15: Apache Spark
Prior to Arrow, the conversion from Spark DataFrames to Pandas was a very inefficient process since we had to go through the costly process of serialization (all rows getting serialized into Python pickle format) and deserialization (Python worker unpickling each row into a list of tuples). With Arrow as the in-memory format, PySpark achieved two advantages:
- There is no need to serialize or deserialize the rows
- When Python receives the Arrow data, PyArrow will create a data frame from the entire chunk of data at once instead of doing it for individual values
Nvidia RAPIDS cuDF
cuDF is a GPU DataFrame library for loading, joining, aggregating, filtering, and manipulating data. It is based on the Apache Arrow columnar memory format. cuDF has been widely used in the Kaggle world to accelerate workflows. Again, it has a Pandas-like API. More details are available here.

Figure 16: NVIDIA RAPIDS
Community
The Apache Arrow community and its ecosystem has grown over the years. In this blog, we saw how Arrow is leveraged as an in-memory columnar format for various applications such as data processing (PyArrow, cuDF, polars), accessing and sharing datasets in ML-based libraries, query engines such as Dremio, and visualizations such as Streamlit and Falcon.
Figure 17: Superhero Arrow series, but you get it
The Arrow developer community has over 700 individuals, with 67 of them having commit access. This trend is only increasing as the data community embraces more of Arrow. Arrow has the potential to be a strong foundation for next-gen analytical computing by defining a common standard and serving a variety of use cases from data engineering to science. Some of the lead developers from the following projects are involved in Apache Arrow: Calcite, Dremio, Drill, Ibis, Pandas, Parquet, Spark, etc.
Apache Arrow repository contributions
Arrow has a diverse set of contributions and interests from the community. The repository currently has 9,701 stars, which depicts developers’ interest in the project. Historically, this trend has only been increasing. See the chart below.
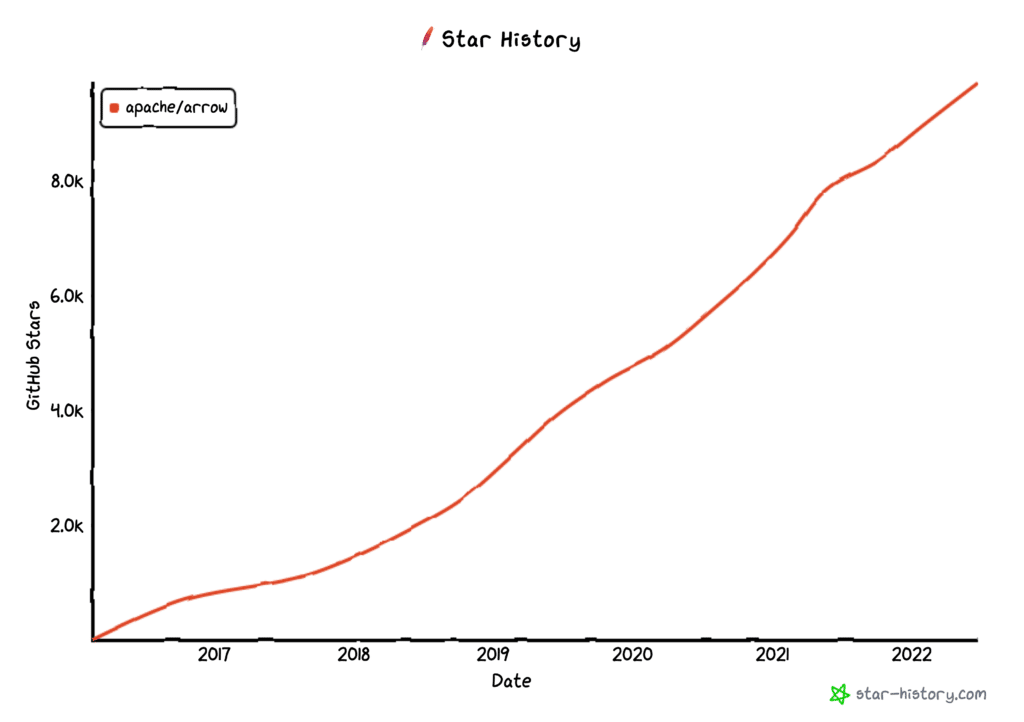
Figure 18: Trending stars
Final Notes
This blog details the origins of Apache Arrow and shows how it fits in today’s constantly changing data landscape. The libraries and tools using Arrow illustrate that while data consumers may not directly consume Arrow, they probably have interacted with it underneath the covers and have taken advantage of numerous tasks. Arrow started as a solution to a common problem when dealing with data, and today it has established itself as a “standard” for in-memory analytics. We look forward to seeing how Arrow is utilized in future. Have you used Arrow-based tools or libraries and want to share some of your learnings? Reach out to us for an opportunity to present at a Subsurface community meetup.
Sign up for AI Ready Data content
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Product Insights from the Dremio Blog,
Learn More ->

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->