13 minute read · June 2, 2022
Table Format Governance and Community Contributions: Apache Iceberg, Apache Hudi, and Delta Lake
· Senior Tech Evangelist, Dremio

One of the most important decisions in the architecture of modern data lakes and data lakehouses is what table format to use to represent the data, as it can determine what tools are available to engineers, how the data can evolve, and more.
In this article, we compared the three major data lake table formats: Apache Iceberg, Apache Hudi, and Delta Lake. One of the areas we compared was the governance and community of the project. In this article, we will explore those aspects more by delving deeper into the differences between an Apache Foundation project or Linux Foundation project, explore what can be learned from analyzing a project's committer diversity, and provide a discussion of why “open source” doesn’t always mean “open.”
This is important because when you embrace an open-source technology you want project governance and a community that will ensure the project follows the direction that’s best for its users, provides ongoing support, and delivers improvements in the project so you don’t find yourself making painful and avoidable migrations down the road.
Apache Foundation and the Linux Foundation
The Apache Foundation was originally created to help maintain the open-source Apache web server which now powers much of the web. Since then, the Apache Foundation has become home to hundreds of open source projects to help promote more open software ecosystems.
The Linux Foundation also provides a home to open source projects to house code and intellectual property ownership.
When it comes to open-source table formats, Iceberg and Hudi are both Apache projects while Delta Lake is a Linux Foundation project.
Each of these foundations have several requirements and standards for projects to meet. This is important because it gives insight into the governance requirements that the open-source projects must meet, which ultimately impacts how the projects operate.
| Apache Foundation | Linux Foundation | |
| Requirements to Join | Working codebase, sponsoring foundation member, intention to transfer IP to join incubator program | Open source, establish open governance processes, transfer IP, and have a sponsoring foundation member |
| Committer Diversity | Must be achieved before incubation period ends to meet community and independence pillars of maturity model | No requirement |
| Project Governance | ASF Board delegates to Project Management Committee (PMC) | Foundation works with founders to document and open process |
| Intellectual Property | Transferred to foundation | Transferred to foundation |
As you can see, the requirements that both foundation projects have to adhere to are generally similar. In return for following the requirements, the projects receive legal, financial, and logistical support to help the open-source projects grow.
The main difference between the two sets of requirements is Apache’s emphasis on independence and community in their maturity model. The requirements include having an active community where any good-faith contributor can advance and earn credit and maintaining independence from the influence of any particular commercial entity. Together, this results in a diverse committer pool.
The committer-driven and open community emphasis originates from the development of the Apache web server, a project started by a group of developers from different companies who saw the value of working on a project together for the benefit of the community at large. Since there wasn’t any particular controlling interest, new developers joined the community and were able to contribute and help evolve projects freely, creating a virtuous cycle of growing volunteers to maintain these projects in the long term.
Apache projects are governed by PMCs (Project Management Committees) whose membership is public knowledge. For example, you can easily find who controls the project (i.e., the committee members) for Apache Iceberg and Apache Hudi.
Delta Lake, on the other hand, is governed by a Technical Steering Committee (TSC) whose current membership is not publicly available. You can see members who potentially make up the committee on this commit, which removes their names from the contribution guide, all of whom are Databricks employees. This commit removes the only public reference to who is on the committee that I’m aware of. That said, the management of Delta Lake is currently not as transparent as Apache Iceberg or Apache Hudi, which raises concerns when it refers to itself “open.”
The Diversity of Committers
So if the big difference between the foundations’ rules is the diversity of committers, let’s examine the distribution of contributors to these projects based on their company association. (Note: This data was collected via the GitHub API, and efforts were made to fill in missing company data and standardize information where possible to create a more accurate picture.)
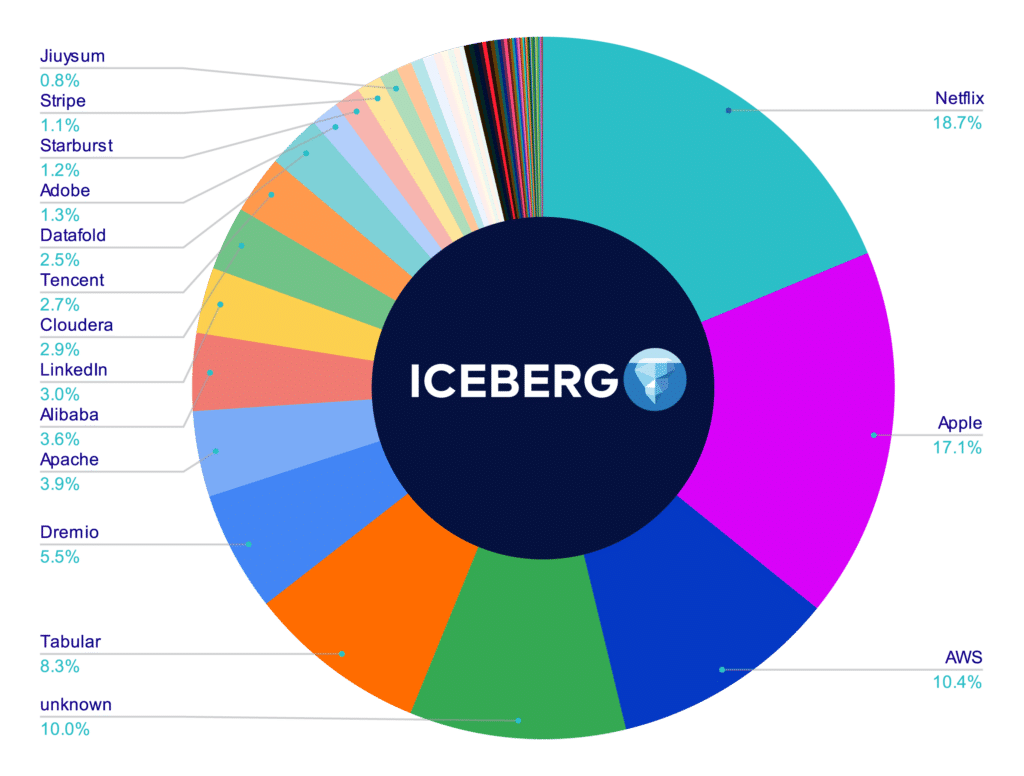
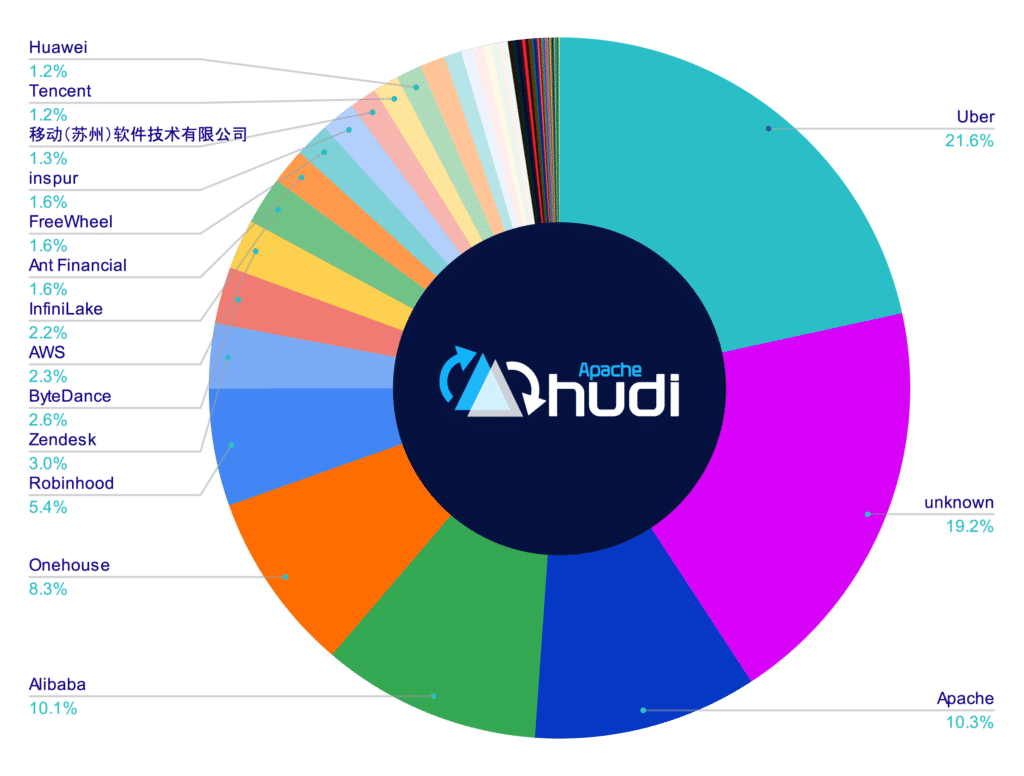
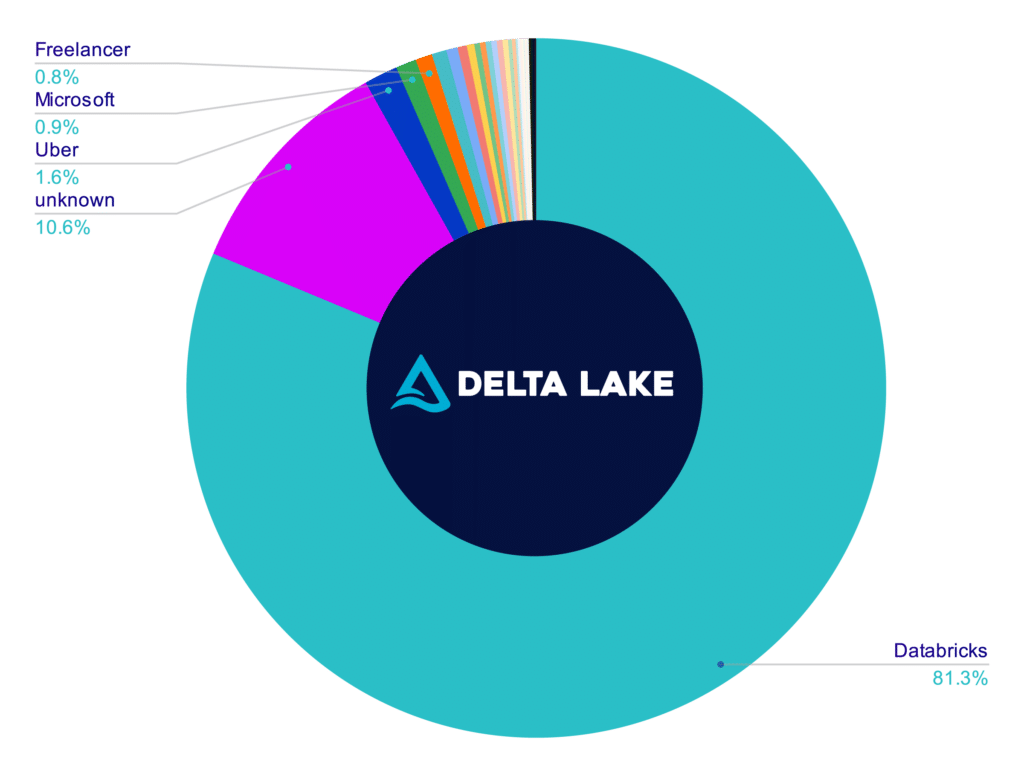
You can see from this data that no single company makes up a third or more of the contributions to either of the Apache Foundation projects (Iceberg and Hudi), while contributions by committers to the Delta Lake public repo is dominated by Databricks employees.
This means that Databricks effectively controls the project's direction, which impacts what the project roadmap will be, what pull requests will be merged, and what issues are prioritized.
The following GitHub statistics for all three formats highlight the number of merged pull requests in their core GitHub repositories.
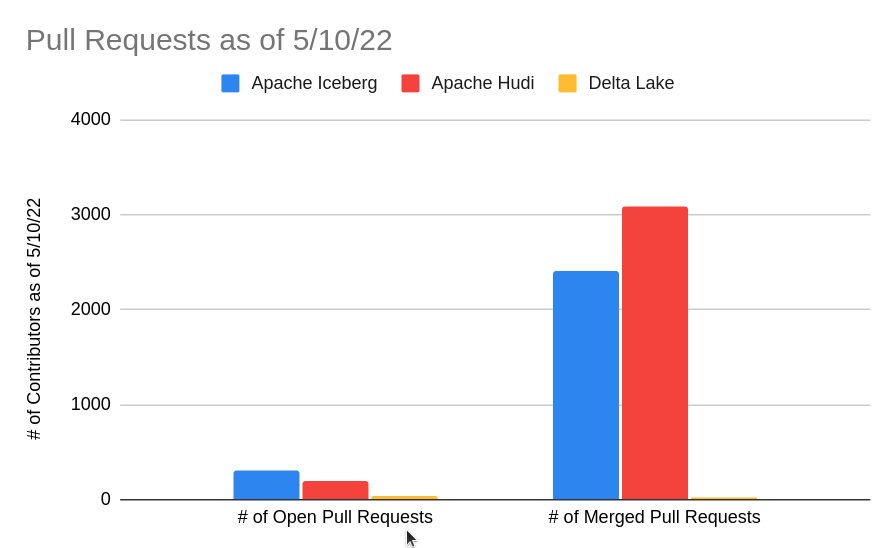
When looking at the charts above you can see a lot of activity in Hudi and Iceberg, with larger numbers of merged pull requests on their core open source repos. Again, this shows you the pace of development that community-led open source projects have over open source projects with a heavy corporate influence.
Open Source Doesn’t Always Mean Open
All three table formats are open source, their code is publicly viewable, people can attempt to contribute, and all IP is in the hands of a non-profit foundation. Unfortunately, being open source doesn’t mean a particular project truly enables open data architectures that allow different engines to be first-class citizens with the ability to read and write your data so you are not boxed into any one tool.
The Tale of Two Delta Lakes
One thing to keep in mind is that there are two versions of Delta Lake, there is Databricks Delta Lake used on the Databricks platform and there is the open-source Delta Lake. The two versions of Delta Lake don’t have feature parity. Some of the differences are due to some features of Databricks Delta Lake relying on the Databricks platform-specific fork of Apache Spark which has features that open source Apache Spark doesn’t have. This can affect things like access to newer features like generated columns, and more.
Engine Support
In the chart below, write support is considered to be available if multiple clusters using a particular engine can safely read and write to the table format.
| Apache Flink | Read & Write | Read & Write | Read |
| Apache Spark | Read & Write | Read & Write | Read & Write |
| Databricks Spark | Read & Write | Read & Write | Read & Write |
| Databricks Photon | Read & Write | ||
| Dremio Sonar | Read & Write | Read | |
| Presto | Read & Write | Read | Read |
| Trino | Read & Write | Read | Read & Write |
| Athena | Read & Write | Read | Read |
| Snowflake External Tables | Read | Read | |
| Apache Impala | Read & Write | Read & Write | |
| Apache Beam | Read | ||
| Apache Drill | Read | ||
| Redshift Spectrum | Read | Read | |
| BigQuery External Tables | Read |
Conclusion
This blog post evaluates the three primary data lake table formats’ approach to community and governance and how they’ve made different choices on which open-source foundation should house their project. From this decision, you can see the ramifications in regards to enabling an open architecture by examining the diversity of each project’s committers and their prioritization on being open formats accessible by as many tools as possible.
Your data lakehouse shouldn’t be something you have to spend the time and effort required for a lengthy rebuild because a new tool isn’t compatible or your table format’s direction changes, so think carefully on which format(s) will have the momentum, features, and openness to house your data analytics today and in the future.
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Dremio Blog: Product Insights,
Learn More ->

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->