6 minute read · September 19, 2022
Ensuring High Performance at Any Scale with Apache Iceberg’s Object Store File Layout
· Senior Tech Evangelist, Dremio

Note: You can find this and many other great Apache Iceberg instructional videos and articles at our Apache Iceberg 101 article.
Cloud object storage services like AWS S3, Azure Blob Storage and Google Cloud Storage have been transformational in the world of data storage. By drastically lowering the cost and complexity of storing large amounts of data many have migrated away from Hadoop clusters.
Cloud object storage has its own architectural considerations as the scale of your data analytics grows and Apache Iceberg is the data lakehouse table format best suited for ensuring high performance at any scale on cloud object storage.
The Prior Hadoop and Hive Paradigm
When it came to large-scale data lake storage, large Hadoop clusters were the standard. Huge networks of low-cost hardware acting as one large-scale distributed hard drive through the Hadoop File System (HDFS). The Hive table format was created originally to help recognize groups of folders stored on HDFS as “tables” for facilitating better data analytics workloads.
The Hive table format relied heavily on the physical layout of files in the file system to know what files belonged to a table. A directory would represent a table and any sub-directories would represent partitions like so:
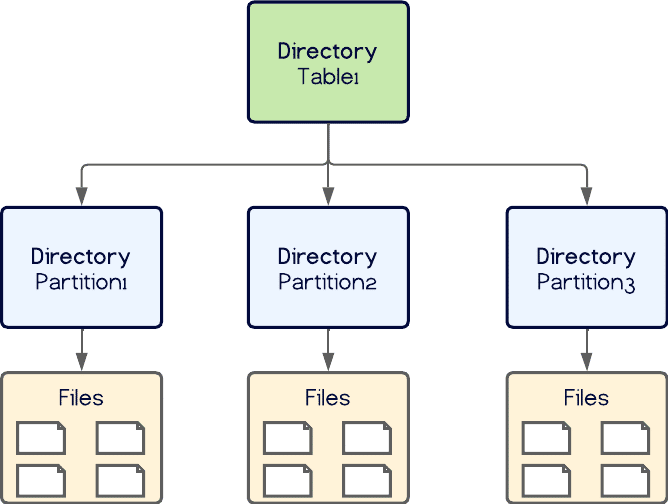
This all works fine from the HDFS paradigm, but a particular bottleneck arises when we structure our data files in this way on object storage.
In object storage, there aren’t traditional directories but “prefixes” (a string before the file name like /this/is/the/prefix/file.txt). Many cloud storage providers like S3 are architected in such a way that there are limits on how many requests can be made per second to files with the same prefix (equivalent to the same directory).
This can be a problem if you depend on the hive-type file layout which can lead to large table partitions having so many files under the same prefix that throttling occurs when accessing the data, causing slow performance.
Table formats like Delta Lake and Apache Hudi rely heavily on the hive file layout exposing themselves to these issues when using cloud object storage.
The Apache Iceberg Solution
Apache Iceberg abandoned this file layout-heavy approach to instead rely on a list of files within its metadata structure. This means the actual data files themselves don’t need to be in any particular location, as long as the file manifests list the right location for that file.
This allows Apache Iceberg to use traditional file layouts when on HDFS but to use alternative file layouts on object storage for better scaling.
When creating an Apache Iceberg table you set the following properties so files written will be optimized in multiple prefixes for cloud object storage.
CREATE TABLE this_catalog.db.my_table ( id bigint, name string, ) USING iceberg OPTIONS ( 'write.object-storage.enabled'=true, 'write.data.path'='s3://the-bucket-with-my-data' ) PARTITIONED BY (bucket(8, id));
With this setting it will generate a hash and write the file to a path with the hash in it.
So let’s say it generates a hash of 7be596a8 – the resulting file path for a data file would be:
s3://the-bucket-with-my-data/table/7be596a8/partition/filename.parquet
This spreads files within a partition under many prefixes, avoiding throttling when accessing lots of files in a large table or large partition.
Conclusion
Cloud object storage has been a great innovation in making data lakehouses more accessible. When paired with Apache Iceberg, you get the full benefits of cloud storage and a table format without any risk of hitting bottlenecks at scale.
Read this article to learn how to create Iceberg tables on S3 using AWS Glue to try Iceberg’s object store file layout yourself.
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Dremio Blog: Product Insights,
Learn More ->

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->