51 minute read · March 26, 2018
Making Data Fast and Easy to Use with Data Reflections
· Founder & Chief Product Officer
Making Data Fast and Easy to Use with Data Reflections
Webinar Transcript
Tomer Shiran:The topic of this talk is data reflections, making data fast and easy to use without making copies. Let’s dive right into this. My name is Tomer, I’m the co-founder and CEO of Dremio, and Jacques Nadeau is the co-founder and CTO of the company. He’s also the PMC chair of Apache Arrow which is a columnary in-memory technology that is now in use by many different open-source and commercial technologies. It’s the foundation for projects like pandas and various GPU databases, projects like Spark use it and so forth. Let’s get started here. So this is kind of what our world looks like today. We have a lot of raw data in many different places, and that includes things like operational databases, these would be the Oracle or the SQL server, basically lots of different systems in which applications are creating data, and then there are also many applications these days where our data is stored. These can be SAS applications like Salesforce and NetSuite and hundreds of others.In order to make this data available what we’ve traditionally done as an industry is we deploy something like a data warehouse where we’re copying data from all these different places into a single kind of clean well-organized schema in a data warehouse and those are typically relational databases. The data warehouse itself is not something that can be used by every single project in the organization, and so what typically happens is for every project there are different needs or every user has a slightly different need for the data, and so that’s kind of why we have data marts, right? We copy data from the data warehouse into various data marts and different departments or different groups and data marts offer kind of a slightly different view of that data. Then querying data marts often not fast enough, so what ends up happening in most organizations is that you then see different users creating BI extracts where they’re extracting data into various BI servers, often in an effort to accelerate queries or at least queries that are known in advance for kind of reports. We create cubes. Often you see users downloading data into kind of flat files, into spreadsheets or CSV files and maybe sharing those in emails. We see data being aggregated in advance in aggregation tables, that’s either in the data mart or in a different system. Then, finally, that data is kind of available for that analysis but the result of all this is that we have now dozens of copies of data in the organization. It’s just this giant, giant mess. Say, about 10 years ago we started seeing kind of the concept of the data lake. Initially with Hadoop and now we see that a lot with cloud storage like S3 and things like Azure data lake store. Basically what this looks like is data gets copied into kind of a landing zone into one of these data lakes which is a very scalable distributed file system, very inexpensive, it’s very easy to get data into that data lake because there are no requirements to create the schema in advance. Then often data gets extracted from the lake into a data warehouse, maybe the last 30 days or some aggregate level data so that people can can query it more efficiently.
Then, finally, that data is kind of available for that analysis but the result of all this is that we have now dozens of copies of data in the organization. It’s just this giant, giant mess. Say, about 10 years ago we started seeing kind of the concept of the data lake. Initially with Hadoop and now we see that a lot with cloud storage like S3 and things like Azure data lake store. Basically what this looks like is data gets copied into kind of a landing zone into one of these data lakes which is a very scalable distributed file system, very inexpensive, it’s very easy to get data into that data lake because there are no requirements to create the schema in advance. Then often data gets extracted from the lake into a data warehouse, maybe the last 30 days or some aggregate level data so that people can can query it more efficiently. The problem is that this data lake really made the problem with data copies even worse. So now, instead of actually making it simpler and more streamlined, we see lots and lots of copies being created inside of that data lake. So we have these ELT processes that are running in that data lake. We have tools like data prep tools that make it even easier to create copies. So now maybe an even broader set of users in the organization can create of data of course. We have tools to create cubes inside of the data lake, and we have various distributed processing frameworks like Spark and prior to that MapReduce that were all about creating more and more and more copies of data. So this creates a big challenge for organizations, and the challenges range from, of course, the obvious just the cost and complexity of managing all these different copies of data that includes storage costs, the disk space and so forth, but it also means that it’s very hard to maintain the security and governance of this data. Now you have potentially sensitive data that’s being copied all over the place whether that’s in the data lake or in all these external tools, floating around in emails, and basically IT kind of loses control of the organization’s data when there are dozens of copies of data inside the company. So that’s a big problem.Well, really, you might be asking, well, why is this happening? Why isn’t it possible for us to just avoid this and maybe define some rules that would prevent people from copying? Well, it turns out there are actually good reasons and that cause this to happen. Well, first of all, there are individual preferences and needs. Different users have different requirements and different needs. One user needs to join the data in the data warehouse or the data lake with their own private data, maybe they need to look at the data with more business-friendly column names or they need to look at a subset of the data. So every user has their own preferences and requirements when they’re doing their analysis. They also need to be able to blend it with their personal data.
The problem is that this data lake really made the problem with data copies even worse. So now, instead of actually making it simpler and more streamlined, we see lots and lots of copies being created inside of that data lake. So we have these ELT processes that are running in that data lake. We have tools like data prep tools that make it even easier to create copies. So now maybe an even broader set of users in the organization can create of data of course. We have tools to create cubes inside of the data lake, and we have various distributed processing frameworks like Spark and prior to that MapReduce that were all about creating more and more and more copies of data. So this creates a big challenge for organizations, and the challenges range from, of course, the obvious just the cost and complexity of managing all these different copies of data that includes storage costs, the disk space and so forth, but it also means that it’s very hard to maintain the security and governance of this data. Now you have potentially sensitive data that’s being copied all over the place whether that’s in the data lake or in all these external tools, floating around in emails, and basically IT kind of loses control of the organization’s data when there are dozens of copies of data inside the company. So that’s a big problem.Well, really, you might be asking, well, why is this happening? Why isn’t it possible for us to just avoid this and maybe define some rules that would prevent people from copying? Well, it turns out there are actually good reasons and that cause this to happen. Well, first of all, there are individual preferences and needs. Different users have different requirements and different needs. One user needs to join the data in the data warehouse or the data lake with their own private data, maybe they need to look at the data with more business-friendly column names or they need to look at a subset of the data. So every user has their own preferences and requirements when they’re doing their analysis. They also need to be able to blend it with their personal data. Imagine somebody who’s looking at a broad, a very large dataset of all the transactions in the company and they really only want to look at the ones corresponding to their own accounts, the accounts that they manage, so they could bring in their own spreadsheet and join it with the broader dataset that’s available, right? So that’s an example of blending with your own personal datasets. Most users do not want to wait weeks and months for IT to make changes. So we see this kind of notion of shadow analytics where users, rather than waiting for IT to make the necessary changes and to prioritize those requests, they do whatever they can to kind of work around the system. That’s why they download data into spreadsheets or they deploy an external BI tool to do whatever they can.Of course, all sorts of limitations around scalability and so forth, but maybe that’s better than waiting so much time in their mind. Then the other thing here is is performance requirements, right? What we see is that when data volumes get really big sometimes data has to be organized in ways that make it more efficient for querying. That can be everything from pre-aggregating the data so that we’re only looking at session level data instead of the raw data and that means that queries can be much faster on that kind of data, or maybe it’s looking at different subsets of the different partitions of the data as opposed to the whole dataset. But all these reasons are really legitimate reasons for wanting to create these duplications or these copies of data in the company.I’ll say just to summarize this what I consider the golden rule of analytics is that a single gold copy of the data is never enough to meet the needs of data consumers. So every time and there’s an attempt to create kind of a gold or a master copy of the data in kind of a clean organized data warehouse, that really … I mean, that’s a good thing to have, but it’s never the end-game, right? It’s never a situation in a company where all the users are just happy with that one golden copy and that meets all their needs. So no matter what you try to do, people are always going to want to kind of massage the data and create new flavors of it, new perspectives on it.What’s the solution to this? Well, we believe that because there’s no way around those needs that the user have, that that’s just the reality of the world we live in, there has to be a logical world to enable that flexibility to curate and to look at different perspectives of the data without creating copies. We call these virtual datasets. So that’s kind of the … We believe that that is the solution to this problem is give users the ability to transform and copy data in a logical way without physically creating copies of that data. So what does that mean? Well, it’s really, these virtual datasets are effectively very similar to database views but really designed for the data consumer, so somebody who’s like an analyst and don’t have kind of that technical skill. They’re not a DBA. They may not know how to write code or even write SQL.
Imagine somebody who’s looking at a broad, a very large dataset of all the transactions in the company and they really only want to look at the ones corresponding to their own accounts, the accounts that they manage, so they could bring in their own spreadsheet and join it with the broader dataset that’s available, right? So that’s an example of blending with your own personal datasets. Most users do not want to wait weeks and months for IT to make changes. So we see this kind of notion of shadow analytics where users, rather than waiting for IT to make the necessary changes and to prioritize those requests, they do whatever they can to kind of work around the system. That’s why they download data into spreadsheets or they deploy an external BI tool to do whatever they can.Of course, all sorts of limitations around scalability and so forth, but maybe that’s better than waiting so much time in their mind. Then the other thing here is is performance requirements, right? What we see is that when data volumes get really big sometimes data has to be organized in ways that make it more efficient for querying. That can be everything from pre-aggregating the data so that we’re only looking at session level data instead of the raw data and that means that queries can be much faster on that kind of data, or maybe it’s looking at different subsets of the different partitions of the data as opposed to the whole dataset. But all these reasons are really legitimate reasons for wanting to create these duplications or these copies of data in the company.I’ll say just to summarize this what I consider the golden rule of analytics is that a single gold copy of the data is never enough to meet the needs of data consumers. So every time and there’s an attempt to create kind of a gold or a master copy of the data in kind of a clean organized data warehouse, that really … I mean, that’s a good thing to have, but it’s never the end-game, right? It’s never a situation in a company where all the users are just happy with that one golden copy and that meets all their needs. So no matter what you try to do, people are always going to want to kind of massage the data and create new flavors of it, new perspectives on it.What’s the solution to this? Well, we believe that because there’s no way around those needs that the user have, that that’s just the reality of the world we live in, there has to be a logical world to enable that flexibility to curate and to look at different perspectives of the data without creating copies. We call these virtual datasets. So that’s kind of the … We believe that that is the solution to this problem is give users the ability to transform and copy data in a logical way without physically creating copies of that data. So what does that mean? Well, it’s really, these virtual datasets are effectively very similar to database views but really designed for the data consumer, so somebody who’s like an analyst and don’t have kind of that technical skill. They’re not a DBA. They may not know how to write code or even write SQL. These virtual datasets can include data from multiple sources, so they’re not limited to being defined on a single source of data. You could have a virtual dataset that joins data from maybe your S3 bucket or your Hadoop cluster and maybe a table you have in Oracle and then a personal spreadsheet. So that’s an example of a single virtual dataset that’s just a join across all those things. It’s important for users to be able to curate new datasets using virtual datasets so that they don’t have to copy data. So when the data is not clean or it’s not in the format that the user expects or doesn’t have the right column names, the user can make all those changes on their own without having to create a copy of the data, without having to export data into a spreadsheet.Then collaboration and security are critical ingredients here. So collaboration, this has to be as easy as using something like Google Docs where you can create a new dataset, share it with your colleagues, they can build on top of each other, and then, of course, collaboration and security are basically two things that go hand in hand, right? The ability to decide who’s allowed to see this dataset and control that. One of the really important things here is if we create a system like this where users can operate in that logical world and do whatever they want, but the system understands what they’re doing so they’re not downloading data into an external spreadsheet and sending that in an email but instead doing things through kind of an IT governance system that provides a whole different level of security and governance compared to the world that we live in today where everybody’s creating copies of data.The next question is well, okay, that’s great, we have this logical world, anybody can do anything with data and we’re not paying any price. There are no physical copies, there are no risks that come with kind of physical copies, right? So on the left here you see kind of the world prior to this approach where everything was a physical copy. Every time we wanted to look at a different perspective on the data we had to copy and ETL that data. With this new approach the data consumers here at the top are able to operate in a logical world where the relationship between datasets are entirely logical. They’re just defined kind of based on relational algebra.Well, how do we leverage … how do we still provide the performance that people expect when everything that’s being done is done at the logical level? For that purpose we kind of think about caching and various data structures that allow us to do that and having a system that can automatically handle the physical world while users only have to worry about the logical world. We talked about the notion of a relational cache, basically maintaining different data structures behind the scenes that can help us achieve the performance that users want without users having to worry about copying the data.
These virtual datasets can include data from multiple sources, so they’re not limited to being defined on a single source of data. You could have a virtual dataset that joins data from maybe your S3 bucket or your Hadoop cluster and maybe a table you have in Oracle and then a personal spreadsheet. So that’s an example of a single virtual dataset that’s just a join across all those things. It’s important for users to be able to curate new datasets using virtual datasets so that they don’t have to copy data. So when the data is not clean or it’s not in the format that the user expects or doesn’t have the right column names, the user can make all those changes on their own without having to create a copy of the data, without having to export data into a spreadsheet.Then collaboration and security are critical ingredients here. So collaboration, this has to be as easy as using something like Google Docs where you can create a new dataset, share it with your colleagues, they can build on top of each other, and then, of course, collaboration and security are basically two things that go hand in hand, right? The ability to decide who’s allowed to see this dataset and control that. One of the really important things here is if we create a system like this where users can operate in that logical world and do whatever they want, but the system understands what they’re doing so they’re not downloading data into an external spreadsheet and sending that in an email but instead doing things through kind of an IT governance system that provides a whole different level of security and governance compared to the world that we live in today where everybody’s creating copies of data.The next question is well, okay, that’s great, we have this logical world, anybody can do anything with data and we’re not paying any price. There are no physical copies, there are no risks that come with kind of physical copies, right? So on the left here you see kind of the world prior to this approach where everything was a physical copy. Every time we wanted to look at a different perspective on the data we had to copy and ETL that data. With this new approach the data consumers here at the top are able to operate in a logical world where the relationship between datasets are entirely logical. They’re just defined kind of based on relational algebra.Well, how do we leverage … how do we still provide the performance that people expect when everything that’s being done is done at the logical level? For that purpose we kind of think about caching and various data structures that allow us to do that and having a system that can automatically handle the physical world while users only have to worry about the logical world. We talked about the notion of a relational cache, basically maintaining different data structures behind the scenes that can help us achieve the performance that users want without users having to worry about copying the data. Let’s talk a little bit more about that relational cache now, something that we call data reflections. Before we start, just a quick relational algebra refresher. When we talk about relational algebra and working with data, there are a few concepts that you’ll hear kind of again and again. So the first one is relation. A relation is basically a table, right? It’s a set of rows. Each row has a fixed number of columns. So that’s kind of what a relational is. Then we have operators and operators are really designed to do some kind of transformation on a relation. So the first operator is the scan operator that can scan the data from wherever it is.
Let’s talk a little bit more about that relational cache now, something that we call data reflections. Before we start, just a quick relational algebra refresher. When we talk about relational algebra and working with data, there are a few concepts that you’ll hear kind of again and again. So the first one is relation. A relation is basically a table, right? It’s a set of rows. Each row has a fixed number of columns. So that’s kind of what a relational is. Then we have operators and operators are really designed to do some kind of transformation on a relation. So the first operator is the scan operator that can scan the data from wherever it is. Then we have the project operator which can restrict the columns that we’re looking at. We have the filter operator which can restrict the number of rows that we’re looking at. Then operators such as aggregations and joins. Properties, those are traits of data at a particular relation. Data can be sorted by a specific attribute, so it can be sorted by X or it can be hash distributed by Y. X and y are examples of properties. We have various rules, and so these rules allow us to basically look at different combinations of operators and say that those are equivalent. We can have these rules that can transform, let’s say, a project followed by a filter to the filter followed by the project. Those two things are equivalent, and so the rules basically define these kind of equivalents, these equality conditions. Another example here is a scan, for example, doesn’t have to project columns that aren’t used later on in the kind of an execution graph. Then finally, we have a graph which is a collection of operators structured in some specific order, chained together in a specific way, and that defines a dataset.The basic concept behind the relational cache is actually very simple. Basically what we’re doing is we’re maintaining derived data that is between what the user wants and what the raw data is, right? So rather than going in and scanning the raw data for every single query, we’re maintaining some materialization of data that is closer to what the user … the answer that the user wants, but it’s not the raw data. Right? And it’s also not the answer that the user wants. So the goal here is to really shorten the distance to data, what we call the DTD. You can see in this picture here, we have the original distance to data which is the distance between what you want, what the query is and the answer for that query, and what the raw data is. So that’s what we call the distance to data. By having one of these materializations, we call them reflections, that can actually reduce the distance to data, right? It can be something that’s closer to what the user wants, and therefore when a query comes in, rather than going through the raw data again, maybe there’s already some pre-processing that’s been done at that level.
Then we have the project operator which can restrict the columns that we’re looking at. We have the filter operator which can restrict the number of rows that we’re looking at. Then operators such as aggregations and joins. Properties, those are traits of data at a particular relation. Data can be sorted by a specific attribute, so it can be sorted by X or it can be hash distributed by Y. X and y are examples of properties. We have various rules, and so these rules allow us to basically look at different combinations of operators and say that those are equivalent. We can have these rules that can transform, let’s say, a project followed by a filter to the filter followed by the project. Those two things are equivalent, and so the rules basically define these kind of equivalents, these equality conditions. Another example here is a scan, for example, doesn’t have to project columns that aren’t used later on in the kind of an execution graph. Then finally, we have a graph which is a collection of operators structured in some specific order, chained together in a specific way, and that defines a dataset.The basic concept behind the relational cache is actually very simple. Basically what we’re doing is we’re maintaining derived data that is between what the user wants and what the raw data is, right? So rather than going in and scanning the raw data for every single query, we’re maintaining some materialization of data that is closer to what the user … the answer that the user wants, but it’s not the raw data. Right? And it’s also not the answer that the user wants. So the goal here is to really shorten the distance to data, what we call the DTD. You can see in this picture here, we have the original distance to data which is the distance between what you want, what the query is and the answer for that query, and what the raw data is. So that’s what we call the distance to data. By having one of these materializations, we call them reflections, that can actually reduce the distance to data, right? It can be something that’s closer to what the user wants, and therefore when a query comes in, rather than going through the raw data again, maybe there’s already some pre-processing that’s been done at that level. Now, these reflections can be basically any … They can be anything, any materialization of data. They have to be of course derived from the raw data, but they can be derived with any arbitrary kind of operator deck. There can be some kind of relational algebra performed on the raw data. Here’s another example here. It doesn’t have to be that trivial of a relationship. In this case we have two reflections that have been created based on the raw data. You can see here, one of the questions, the one on the top right here, can be answered by looking at some … Or can be constructed by looking at both the reflection, the second reflection, as well as the raw data. That may be cheaper than going against just the raw data, right? So this is an example where … And you see several examples here where answering a specific query, that kind of what you want boxes at the top, requires data from more than a single reflection as we saw earlier.Now, this may seem, okay, unique or interesting, but the reality is you’re already doing this today, you’re just doing it manually, right? So if you think about how you’re materializing data today, you’re most likely already doing things like sessionizing the data. So taking the raw data and kind of aggregating it by sessions. You’re probably already cleaning your data, cleansing it, and so that’s another example of you’re creating materialization of data that’s a little bit closer to what the users are going to be interested in or at least closer than the actual raw data. You may be creating data that’s partitioned by the region or the time so that queries can run faster. So that’s an example of materializing data that’s, again, closer to what the user wants or can enable queries to be much faster. Or maybe you have the data summarized for a specific kind of purpose.Now, the challenge here is that today by doing this you’re creating all these other copies of the data and the user has to choose depending on their need. So you have to take your analyst and you have to train them to use a different table depending on the use case that they have. So if the analyst wants to do some arbitrary ad hoc query against the raw events, maybe you have to go against the raw data, but if they’re interested in session level information, maybe they can go against the sessionized data, right? If they want to query only for data in a specific region, maybe they want to look at a specific kind of aggregations on data belonging to just one region or one year. Well, then using a dataset that’s already partitioned by region and time can be more effective, but the user or the analyst, I should say, has to know what is the ideal materialization to use. As they’re going through an analysis journey they have to be able to understand that the dataset, the optimal dataset for each query may be different. So they kind of have to go in and out from different datasets.The benefits of having a relational cache compared to doing this kind of manual copy and pick type of an approach is that the cache is able to pick the best optimization to use. If you think about the approach with these data reflections, the user doesn’t have to worry about these data reflections. The user’s not even aware that these reflections exist. They’re just querying the logical model, and the cache automatically picks the right optimization to use. In fact, the cache can also design and maintain these reflections. So these reflections, really, that is what the relational cache contains. Just to summarize a reflection is really a materialization that’s designed to accelerate queries. It’s transparent to data consumers. It’s not required on day one. You can add any reflections at any time. So that means you can get started with the system and do ad hoc analysis within a minute of setting it up, and then reflections can be created over time to optimize various workloads, right? Very different from kind of traditional approaches to query acceleration like cubes where you spend weeks or months in advance trying to figure out what questions are people going to ask, and how do I model that data, and how to create these cubes.In this approach here with reflections none of that is needed. You can just get started, query any data at any time and the reflections kind of kick in behind the scenes without having to point your your BI tool or your application at a specific materialization. What’s really important here is that one reflection can help accelerate queries on thousands of different virtual datasets. So the logical model, here at the logical world, you may have thousands or hundreds of thousands of different datasets that users have created over time. That doesn’t mean you need thousands of these reflections. You may have one reflection that’s helping to accelerate queries on thousands of different datasets. That’s because ultimately, most of the data in an organization is derived from a much smaller subset of kind of raw datasets.The system can understand the relational algebra and the relational connections between all these different datasets and leverage these reflections in a more intelligent way, right, in kind of a broader way. The reflections themselves are persistent. They do not require any memory overhead. They don’t have to fit in memory. The system can utilize things like S3 for HDFS or local disks to accelerate those queries. A combination of columnar on disk and columnar in memory is utilized here. Columnar on disk, we utilize Parquet for the most part, and in memory we utilize Arrow. These technologies is scalable and scale up the thousands of nodes. It’s entirely open source as well, so you can get a website and just download it or go to GitHub and look at the source code.Let’s talk a little bit about just two different types of reflections based on how they’re managed, how they’re refreshed. The simplest type of reflection to use is the managed reflection. The managed reflection is basically managed by Dremio in this case. Just for manageability reasons a reflection is always associated with a specific physical or virtual dataset. Again, it may accelerate queries on thousands of other datasets as well, but in order for users to be able to manage and find that reflection, they’re always tied to a specific dataset. Then in connection with that dataset that they’re attached to there are two types of reflections that are very easy to create. One is a raw reflection, which is kind of the raw level of granularity reflection.
Now, these reflections can be basically any … They can be anything, any materialization of data. They have to be of course derived from the raw data, but they can be derived with any arbitrary kind of operator deck. There can be some kind of relational algebra performed on the raw data. Here’s another example here. It doesn’t have to be that trivial of a relationship. In this case we have two reflections that have been created based on the raw data. You can see here, one of the questions, the one on the top right here, can be answered by looking at some … Or can be constructed by looking at both the reflection, the second reflection, as well as the raw data. That may be cheaper than going against just the raw data, right? So this is an example where … And you see several examples here where answering a specific query, that kind of what you want boxes at the top, requires data from more than a single reflection as we saw earlier.Now, this may seem, okay, unique or interesting, but the reality is you’re already doing this today, you’re just doing it manually, right? So if you think about how you’re materializing data today, you’re most likely already doing things like sessionizing the data. So taking the raw data and kind of aggregating it by sessions. You’re probably already cleaning your data, cleansing it, and so that’s another example of you’re creating materialization of data that’s a little bit closer to what the users are going to be interested in or at least closer than the actual raw data. You may be creating data that’s partitioned by the region or the time so that queries can run faster. So that’s an example of materializing data that’s, again, closer to what the user wants or can enable queries to be much faster. Or maybe you have the data summarized for a specific kind of purpose.Now, the challenge here is that today by doing this you’re creating all these other copies of the data and the user has to choose depending on their need. So you have to take your analyst and you have to train them to use a different table depending on the use case that they have. So if the analyst wants to do some arbitrary ad hoc query against the raw events, maybe you have to go against the raw data, but if they’re interested in session level information, maybe they can go against the sessionized data, right? If they want to query only for data in a specific region, maybe they want to look at a specific kind of aggregations on data belonging to just one region or one year. Well, then using a dataset that’s already partitioned by region and time can be more effective, but the user or the analyst, I should say, has to know what is the ideal materialization to use. As they’re going through an analysis journey they have to be able to understand that the dataset, the optimal dataset for each query may be different. So they kind of have to go in and out from different datasets.The benefits of having a relational cache compared to doing this kind of manual copy and pick type of an approach is that the cache is able to pick the best optimization to use. If you think about the approach with these data reflections, the user doesn’t have to worry about these data reflections. The user’s not even aware that these reflections exist. They’re just querying the logical model, and the cache automatically picks the right optimization to use. In fact, the cache can also design and maintain these reflections. So these reflections, really, that is what the relational cache contains. Just to summarize a reflection is really a materialization that’s designed to accelerate queries. It’s transparent to data consumers. It’s not required on day one. You can add any reflections at any time. So that means you can get started with the system and do ad hoc analysis within a minute of setting it up, and then reflections can be created over time to optimize various workloads, right? Very different from kind of traditional approaches to query acceleration like cubes where you spend weeks or months in advance trying to figure out what questions are people going to ask, and how do I model that data, and how to create these cubes.In this approach here with reflections none of that is needed. You can just get started, query any data at any time and the reflections kind of kick in behind the scenes without having to point your your BI tool or your application at a specific materialization. What’s really important here is that one reflection can help accelerate queries on thousands of different virtual datasets. So the logical model, here at the logical world, you may have thousands or hundreds of thousands of different datasets that users have created over time. That doesn’t mean you need thousands of these reflections. You may have one reflection that’s helping to accelerate queries on thousands of different datasets. That’s because ultimately, most of the data in an organization is derived from a much smaller subset of kind of raw datasets.The system can understand the relational algebra and the relational connections between all these different datasets and leverage these reflections in a more intelligent way, right, in kind of a broader way. The reflections themselves are persistent. They do not require any memory overhead. They don’t have to fit in memory. The system can utilize things like S3 for HDFS or local disks to accelerate those queries. A combination of columnar on disk and columnar in memory is utilized here. Columnar on disk, we utilize Parquet for the most part, and in memory we utilize Arrow. These technologies is scalable and scale up the thousands of nodes. It’s entirely open source as well, so you can get a website and just download it or go to GitHub and look at the source code.Let’s talk a little bit about just two different types of reflections based on how they’re managed, how they’re refreshed. The simplest type of reflection to use is the managed reflection. The managed reflection is basically managed by Dremio in this case. Just for manageability reasons a reflection is always associated with a specific physical or virtual dataset. Again, it may accelerate queries on thousands of other datasets as well, but in order for users to be able to manage and find that reflection, they’re always tied to a specific dataset. Then in connection with that dataset that they’re attached to there are two types of reflections that are very easy to create. One is a raw reflection, which is kind of the raw level of granularity reflection. The data is columnized, very highly compressed and then it can be sorted and partitioned and distributed in specific ways. Then you can have aggregation reflections as well tied to that dataset. Aggregation reflections are basically reflections that are partially aggregated versions of that dataset based on specific dimensions and measures. Again, they can be sorted, partitioned and distributed as well. The managed reflections are always persisted as Parquet files on either S3, Azure Data Lake Store, HDFS, MapR-FS, local disks, et cetera. So these are persistent columnary representations of that logical data. In the future there will also be in memory reflections based on Apache Arrow. That’ll be great for data that’s very frequently accessed, for example.
The data is columnized, very highly compressed and then it can be sorted and partitioned and distributed in specific ways. Then you can have aggregation reflections as well tied to that dataset. Aggregation reflections are basically reflections that are partially aggregated versions of that dataset based on specific dimensions and measures. Again, they can be sorted, partitioned and distributed as well. The managed reflections are always persisted as Parquet files on either S3, Azure Data Lake Store, HDFS, MapR-FS, local disks, et cetera. So these are persistent columnary representations of that logical data. In the future there will also be in memory reflections based on Apache Arrow. That’ll be great for data that’s very frequently accessed, for example. Here’s an example, when using the command line as opposed to the user interface on how to create a reflection. So you basically use kind of an alter dataset, this is the path to the dataset that you’re attaching the reflection to, and then you either create the raw reflection or the AGG reflection. You can give it a name that makes it easy to then track how it’s being utilized and so forth. So when it comes to aggregation reflections you specify the dimensions and the measures, when it comes to raw reflections you’re just specifying the columns or the fields that are included in that reflection. You don’t have to include all the fields in that dataset. You may say, “You know what? There are 300 fields in this dataset. People are only going to be querying these 15 fields.” so those are the ones you’re going to have. It would be great to use the partitioning or the local sort kind of methods here in order to designate specific fields that are often being used inside of filters, for example.
Here’s an example, when using the command line as opposed to the user interface on how to create a reflection. So you basically use kind of an alter dataset, this is the path to the dataset that you’re attaching the reflection to, and then you either create the raw reflection or the AGG reflection. You can give it a name that makes it easy to then track how it’s being utilized and so forth. So when it comes to aggregation reflections you specify the dimensions and the measures, when it comes to raw reflections you’re just specifying the columns or the fields that are included in that reflection. You don’t have to include all the fields in that dataset. You may say, “You know what? There are 300 fields in this dataset. People are only going to be querying these 15 fields.” so those are the ones you’re going to have. It would be great to use the partitioning or the local sort kind of methods here in order to designate specific fields that are often being used inside of filters, for example. Now how the these reflections, these managed reflections get refreshed really depends on the dataset size and the nature in which the dataset, the raw data is getting updated. There are multiple different strategies here for refreshing partitions. It starts with kind of … The simplest one is the full refresh where the reflection gets recreated from scratch on a schedule, basically, or at some period of time to maintain a specific SLA. So that’s great for reflections or for creating reflections on datasets that are generally smaller, right? In the millions maybe billions of data. And also when the data is highly mutating, right?Sometimes it’s just most efficient to recreate that reflection every time if the data is changing rapidly. For datasets, for example, that are very large and maybe append-only in nature, and that’s a very common kind of pattern that we see is event data or time series type data where you’re never really changing the data, but you’re adding tons and tons and tons of data. We can use kind of a more incremental approach there. When it comes to files in a file system, basically the system can automatically identify new files in a directory and based on that … Incrementally these raw or aggregation reflections. Partition reflections are great when you have things like Hive partitions or data is organized in directories, and so there’s a well-defined way of identifying new buckets of data that are being added to that reflection. Then finally, incremental, for kind of smaller tables, maybe relational databases or no SQL tables. We can also build the reflections incrementally based on a monotonically increasing field. So you may have like a last created or created at kind of a field or just a primary key that’s always increasing.Now, the alternative to this is what we call unmanaged reflections or external reflections. You can utilize your own ETL pipeline on your own external tools to create reflections as well. When you’re using these these external reflections you can basically run, for example, a Spark job, your own Spark job that creates some materialization of data, and then you kind of register that materialization with the optimizer and say, “This materialization is represented by this SQL query.” Then the optimizer can use that as a reflection across the entire logical space.There’s a lot to cover here in terms of managed reflections as well. One thing we didn’t mention is there’s a refresh order in which these reflections get refreshed. So sometimes it’s beneficial to, for example, first update the raw reflection, and then if there’s an aggregation reflection as well, update that based on the raw reflection rather than utilizing the source data. What users are really defining is not so much just a schedule, but what we call freshness SLA. That’s roughly similar to the refresh frequency, but it’s really designed to ensure that queries on data never return data that’s older or more stale than a specific kind of defined SLA. So the system automatically tries to figure out, okay, what’s the right time to start updating the reflection, how should the these reflection updates be ordered and so forth in the optimal way to achieve that kind of an SLA.I kind of mentioned briefly the unmanaged or external reflections, which are new in actually Dremio 1.5. With unmanaged reflections you can create managed materializations on your own. So you can use Spark or you can use ETL jobs, you can use scripts, but basically you’re responsible for creating these reflections and refreshing them as needed. Basically you can create reflections in any data source that Dremio supports. Dremio supports not just compliant systems and data lakes but even relational databases and no-SQL databases. So these reflections can live anywhere. The key is that once you’ve created or refreshed the reflection, or actually just when you’ve created it, you can call a specific command, specific SQL statement here to register that reflection with the optimizer. So basically you do that by providing a SQL statement in the form of a virtual dataset that defines what is that target, what does the reflection represent. So if you’ve used, say, Spark to create an aggregation based on a few dimensions and you have a few measures there, you simply provide that equivalent group-by SQL statement as the definition of a virtual dataset, and then you utilize this command to say, okay, this SQL statement represents that specific materializations that you’ve created through some external system.
Now how the these reflections, these managed reflections get refreshed really depends on the dataset size and the nature in which the dataset, the raw data is getting updated. There are multiple different strategies here for refreshing partitions. It starts with kind of … The simplest one is the full refresh where the reflection gets recreated from scratch on a schedule, basically, or at some period of time to maintain a specific SLA. So that’s great for reflections or for creating reflections on datasets that are generally smaller, right? In the millions maybe billions of data. And also when the data is highly mutating, right?Sometimes it’s just most efficient to recreate that reflection every time if the data is changing rapidly. For datasets, for example, that are very large and maybe append-only in nature, and that’s a very common kind of pattern that we see is event data or time series type data where you’re never really changing the data, but you’re adding tons and tons and tons of data. We can use kind of a more incremental approach there. When it comes to files in a file system, basically the system can automatically identify new files in a directory and based on that … Incrementally these raw or aggregation reflections. Partition reflections are great when you have things like Hive partitions or data is organized in directories, and so there’s a well-defined way of identifying new buckets of data that are being added to that reflection. Then finally, incremental, for kind of smaller tables, maybe relational databases or no SQL tables. We can also build the reflections incrementally based on a monotonically increasing field. So you may have like a last created or created at kind of a field or just a primary key that’s always increasing.Now, the alternative to this is what we call unmanaged reflections or external reflections. You can utilize your own ETL pipeline on your own external tools to create reflections as well. When you’re using these these external reflections you can basically run, for example, a Spark job, your own Spark job that creates some materialization of data, and then you kind of register that materialization with the optimizer and say, “This materialization is represented by this SQL query.” Then the optimizer can use that as a reflection across the entire logical space.There’s a lot to cover here in terms of managed reflections as well. One thing we didn’t mention is there’s a refresh order in which these reflections get refreshed. So sometimes it’s beneficial to, for example, first update the raw reflection, and then if there’s an aggregation reflection as well, update that based on the raw reflection rather than utilizing the source data. What users are really defining is not so much just a schedule, but what we call freshness SLA. That’s roughly similar to the refresh frequency, but it’s really designed to ensure that queries on data never return data that’s older or more stale than a specific kind of defined SLA. So the system automatically tries to figure out, okay, what’s the right time to start updating the reflection, how should the these reflection updates be ordered and so forth in the optimal way to achieve that kind of an SLA.I kind of mentioned briefly the unmanaged or external reflections, which are new in actually Dremio 1.5. With unmanaged reflections you can create managed materializations on your own. So you can use Spark or you can use ETL jobs, you can use scripts, but basically you’re responsible for creating these reflections and refreshing them as needed. Basically you can create reflections in any data source that Dremio supports. Dremio supports not just compliant systems and data lakes but even relational databases and no-SQL databases. So these reflections can live anywhere. The key is that once you’ve created or refreshed the reflection, or actually just when you’ve created it, you can call a specific command, specific SQL statement here to register that reflection with the optimizer. So basically you do that by providing a SQL statement in the form of a virtual dataset that defines what is that target, what does the reflection represent. So if you’ve used, say, Spark to create an aggregation based on a few dimensions and you have a few measures there, you simply provide that equivalent group-by SQL statement as the definition of a virtual dataset, and then you utilize this command to say, okay, this SQL statement represents that specific materializations that you’ve created through some external system. Okay, so let’s look at an example here. We’ll look at a few examples of how the reflections get matched. A lot of the the algorithms here that make this work are about how do you take a specific query or a specific query plan, which is what happens after the query gets compiled, and match that to specific reflections. So let’s look at what that looks like. The first example here is an aggregation rollup. In this case we have the user’s query plan, so this is what the SQL, the user’s SQL query got compiled to. You can see that it has a scan at the bottom of table one. It’s then projecting two columns, a and c, and then aggregating by a and summing up the c column and then finally filtering that column so that we’re keeping only the records where c is less than 10. If you take that query plan here, and we have a reflection in this case which is a scan of t1 and an aggregation of a and b by a and b on top of that, and summing c, what you can see here is that we can actually replace the aggregation … Sorry, that we can replace the scan of t1 part of the aggregation by utilizing this reflection.You can see on the right-hand side here, we have scan of r1 instead of scan of t1. So we’re actually not needing the raw data at all in this case, we’re taking the reflection itself, aggregating by a because the reflection itself wasn’t aggregated by both a and b, and so we kind of need to aggregate again on a, and then finally apply that filter on top of that. So what we were able to do here is take advantage of the reflection which was most likely much, much smaller than the original table, than t1. Let’s look at another example here where we’re doing a join/aggregation transposition. In this example here we have a simple join, it’s an inner join between two tables, t1 and t2. Then we’re aggregating by a and summing c. In this case we have a reflection in the system that’s a scan of t1 and an aggregation on the ID on the join key and then again summing c. So what we can do here is replace the scan of t1 with a scan of this specific reflection which is aggregated already by the ID. That’s possible because the join key is that ID. Then again, we apply the aggregation on top of that. In this case most likely r1 is much, much smaller than t1, that depends, of course, on the cardinality of the ID column, but this provides the solution with potentially a much lower cost query plan.Okay. One other example here where we have a simple query, this is a scan of t1 and then a filter on a column called a. So we’re filtering and keeping only the records where a is equal to 10. In this case, we have two different reflections in the system that are logically the same. So they’re both simply scans of t1, but in one case it’s a scan that’s partitioned by a, and in one case it’s a skin that’s partitioned by b. So in this case the optimizer automatically figures out that it can actually leverage the reflection which has the data and t1 partition by a and utilize that, simply prune the partitions and keep only the partition where a is equal to 10.That helps us look at a very, very small subset of the original data and provide a much faster response here. This is another example here, something we call snowflake reflections. In this example here we have a scan of the original query. The user’s query is a scan of t1 aggregated by a and we’re summing c. So we have a single reflection here which is basically a join of t1 and t2, and it’s what we call a non-expanding join, meaning the number of records is not changing as a result of the join. This is what you typically see with a fact table and dimension tables, right, where the dimension tables, joining the fact tables or the dimension tables results in the same number of records that you had in the fact table.
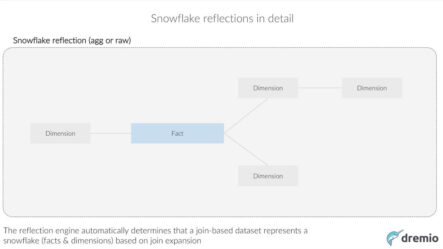
Okay, so let’s look at an example here. We’ll look at a few examples of how the reflections get matched. A lot of the the algorithms here that make this work are about how do you take a specific query or a specific query plan, which is what happens after the query gets compiled, and match that to specific reflections. So let’s look at what that looks like. The first example here is an aggregation rollup. In this case we have the user’s query plan, so this is what the SQL, the user’s SQL query got compiled to. You can see that it has a scan at the bottom of table one. It’s then projecting two columns, a and c, and then aggregating by a and summing up the c column and then finally filtering that column so that we’re keeping only the records where c is less than 10. If you take that query plan here, and we have a reflection in this case which is a scan of t1 and an aggregation of a and b by a and b on top of that, and summing c, what you can see here is that we can actually replace the aggregation … Sorry, that we can replace the scan of t1 part of the aggregation by utilizing this reflection.You can see on the right-hand side here, we have scan of r1 instead of scan of t1. So we’re actually not needing the raw data at all in this case, we’re taking the reflection itself, aggregating by a because the reflection itself wasn’t aggregated by both a and b, and so we kind of need to aggregate again on a, and then finally apply that filter on top of that. So what we were able to do here is take advantage of the reflection which was most likely much, much smaller than the original table, than t1. Let’s look at another example here where we’re doing a join/aggregation transposition. In this example here we have a simple join, it’s an inner join between two tables, t1 and t2. Then we’re aggregating by a and summing c. In this case we have a reflection in the system that’s a scan of t1 and an aggregation on the ID on the join key and then again summing c. So what we can do here is replace the scan of t1 with a scan of this specific reflection which is aggregated already by the ID. That’s possible because the join key is that ID. Then again, we apply the aggregation on top of that. In this case most likely r1 is much, much smaller than t1, that depends, of course, on the cardinality of the ID column, but this provides the solution with potentially a much lower cost query plan.Okay. One other example here where we have a simple query, this is a scan of t1 and then a filter on a column called a. So we’re filtering and keeping only the records where a is equal to 10. In this case, we have two different reflections in the system that are logically the same. So they’re both simply scans of t1, but in one case it’s a scan that’s partitioned by a, and in one case it’s a skin that’s partitioned by b. So in this case the optimizer automatically figures out that it can actually leverage the reflection which has the data and t1 partition by a and utilize that, simply prune the partitions and keep only the partition where a is equal to 10.That helps us look at a very, very small subset of the original data and provide a much faster response here. This is another example here, something we call snowflake reflections. In this example here we have a scan of the original query. The user’s query is a scan of t1 aggregated by a and we’re summing c. So we have a single reflection here which is basically a join of t1 and t2, and it’s what we call a non-expanding join, meaning the number of records is not changing as a result of the join. This is what you typically see with a fact table and dimension tables, right, where the dimension tables, joining the fact tables or the dimension tables results in the same number of records that you had in the fact table. So what we’re able to do in this case is that, even though the user’s query is only on the t1 table and the reflection itself was created on a join between t1 and t2, we can actually leverage this reflection to accelerate this query. You can see that we’re able to utilize the reflection and then aggregate by a and sum c on top of that reflection, right? This is really, really useful when you have these kind of snowflake type of designs where you can have a fact table and then many dimension tables, often joined to that fact table. So you can take that big join that you have with all those different tables, create a reflection, whether an aggregation reflection or a raw reflection on that, and that can then help accelerate queries even when they’re not querying that entire kind of join, maybe they’re only according two tables out of those. Let’s look at that example in more detail.This is an example of snowflake reflection. Here we have a fact table and dimension tables joined to that fact table. We also have another dimension table off of one of these dimension tables. So when you have this kind of a join represented as a virtual dataset and then you define reflections associated with that, the reflection engine automatically determines that this join represents a snowflake, meaning it has the fact table and all these dimensions, and it determines that based on the join expansion. When this reflection is getting materialized, and the system is actually running this join for the creation of that reflection, it can see how are these joins behaving based on the actual data.So the user never has to say, “This is a fact table. This is a dimension table.” They just … Somebody created a join between all these things and the engine is smart enough to figure that out based on the fact that, just as a simple example, the number of records coming out of the join between the fact and one of these dimensions is the same number of records that were in the fact table. So that means it’s a non-expanding join, and when somebody queries data that lets us match a broader set of queries here. In this case, if somebody is querying just these three dimensions and the fact table, that query can get accelerated thanks to the snowflake reflection. Also, if somebody was querying just the fact table and these two dimension tables that you see in the green box here, that could also get accelerated. The system’s kind of intelligence around looking at the understanding the data itself when the reflections get created, it helps it then make these determinations that this reflection can be utilized for these types of queries because in some situations if we weren’t looking at the data, there can be joins where the join is actually creating duplicate records, right? Then it would not make sense to utilize that kind of join, the reflection on that join for subsets kind of joins like you see here.What we’ve seen in real-world results, generally with the reflections, not just for snowflakes, is that many or actually virtually all organizations that utilize reflections are seeing anywhere from 10 to many orders of magnitude performance improvement in their real world analytics environments. It’s not just about speed, though. It also reduces the compute resources that you need to achieve the desired performance. So when it comes to deploying in the cloud, that means potentially orders of magnitude lower and lower bills, right, when it comes to how much resources you’re needing or potentially just being able to do more round trips, more iterations on the data. Then it also results in a reduction in disk space because you’re now eliminating the need for all these hundreds of copies that people are creating today. Again, going back to that having kind of a logical world for users to operate in and having the relational cache utilize a much, much smaller footprint just for the purpose of performance, right? So that gives you a big cost saving as well.Let’s dive into kind of a demonstration here. What we’re going to start with here is let’s look at the system. Okay. Let’s turn on the VPN here. Okay, great. So what we have here … Actually, let me connect to a newer cluster. I grab the URL here on Slack. That’s actually … Okay, so what we have here is a single Dremio cluster. Right now it’s only connected to three data sources, so we have an HDFS cluster, we have Elasticsearch, MongoDB. You can connect to many different data sources. Dremio actually supports over a dozen different sources of data. You have the spaces here. Spaces are place where these virtual datasets live. Basically the area of the space is here, that’s where this logical world exists where users are creating virtual datasets. In fact, users can also create virtual datasets in their own personal space, so every user has their own personal space. This is a simple example to get started here.Let’s look at some data. We have this dataset here with New York City taxi trips. This dataset has about a billion records, and it has all the New York City taxi trips from the last five years. Well, not the last five years, but some five years here. So each record here represents a single taxi trip. You see the pickup time, the drop-off time, number of passengers, the trip distance and so forth. This is a logical … Or sorry, a virtual dataset. So Nyctaxi.trips, that’s kind of the canonical name for this virtual dataset. We make it really easy with a variety of different tools to launch these tools on your desktop with a live connection to the Dremio cluster. I’ll show you what that looks like.
So what we’re able to do in this case is that, even though the user’s query is only on the t1 table and the reflection itself was created on a join between t1 and t2, we can actually leverage this reflection to accelerate this query. You can see that we’re able to utilize the reflection and then aggregate by a and sum c on top of that reflection, right? This is really, really useful when you have these kind of snowflake type of designs where you can have a fact table and then many dimension tables, often joined to that fact table. So you can take that big join that you have with all those different tables, create a reflection, whether an aggregation reflection or a raw reflection on that, and that can then help accelerate queries even when they’re not querying that entire kind of join, maybe they’re only according two tables out of those. Let’s look at that example in more detail.This is an example of snowflake reflection. Here we have a fact table and dimension tables joined to that fact table. We also have another dimension table off of one of these dimension tables. So when you have this kind of a join represented as a virtual dataset and then you define reflections associated with that, the reflection engine automatically determines that this join represents a snowflake, meaning it has the fact table and all these dimensions, and it determines that based on the join expansion. When this reflection is getting materialized, and the system is actually running this join for the creation of that reflection, it can see how are these joins behaving based on the actual data.So the user never has to say, “This is a fact table. This is a dimension table.” They just … Somebody created a join between all these things and the engine is smart enough to figure that out based on the fact that, just as a simple example, the number of records coming out of the join between the fact and one of these dimensions is the same number of records that were in the fact table. So that means it’s a non-expanding join, and when somebody queries data that lets us match a broader set of queries here. In this case, if somebody is querying just these three dimensions and the fact table, that query can get accelerated thanks to the snowflake reflection. Also, if somebody was querying just the fact table and these two dimension tables that you see in the green box here, that could also get accelerated. The system’s kind of intelligence around looking at the understanding the data itself when the reflections get created, it helps it then make these determinations that this reflection can be utilized for these types of queries because in some situations if we weren’t looking at the data, there can be joins where the join is actually creating duplicate records, right? Then it would not make sense to utilize that kind of join, the reflection on that join for subsets kind of joins like you see here.What we’ve seen in real-world results, generally with the reflections, not just for snowflakes, is that many or actually virtually all organizations that utilize reflections are seeing anywhere from 10 to many orders of magnitude performance improvement in their real world analytics environments. It’s not just about speed, though. It also reduces the compute resources that you need to achieve the desired performance. So when it comes to deploying in the cloud, that means potentially orders of magnitude lower and lower bills, right, when it comes to how much resources you’re needing or potentially just being able to do more round trips, more iterations on the data. Then it also results in a reduction in disk space because you’re now eliminating the need for all these hundreds of copies that people are creating today. Again, going back to that having kind of a logical world for users to operate in and having the relational cache utilize a much, much smaller footprint just for the purpose of performance, right? So that gives you a big cost saving as well.Let’s dive into kind of a demonstration here. What we’re going to start with here is let’s look at the system. Okay. Let’s turn on the VPN here. Okay, great. So what we have here … Actually, let me connect to a newer cluster. I grab the URL here on Slack. That’s actually … Okay, so what we have here is a single Dremio cluster. Right now it’s only connected to three data sources, so we have an HDFS cluster, we have Elasticsearch, MongoDB. You can connect to many different data sources. Dremio actually supports over a dozen different sources of data. You have the spaces here. Spaces are place where these virtual datasets live. Basically the area of the space is here, that’s where this logical world exists where users are creating virtual datasets. In fact, users can also create virtual datasets in their own personal space, so every user has their own personal space. This is a simple example to get started here.Let’s look at some data. We have this dataset here with New York City taxi trips. This dataset has about a billion records, and it has all the New York City taxi trips from the last five years. Well, not the last five years, but some five years here. So each record here represents a single taxi trip. You see the pickup time, the drop-off time, number of passengers, the trip distance and so forth. This is a logical … Or sorry, a virtual dataset. So Nyctaxi.trips, that’s kind of the canonical name for this virtual dataset. We make it really easy with a variety of different tools to launch these tools on your desktop with a live connection to the Dremio cluster. I’ll show you what that looks like. Normally, according on this dataset … Let’s see. all this stuff here. Normally, a query on this dataset takes, if we were just querying the raw data without the help of reflections, will take us something like maybe six to 10 minutes using kind of a sequential on this data and on this size of cluster. But the reflections basically help us make this much faster. So we can look here, an example. Again, this is a query run in Hive or kind of any other sequential would take us minutes. I can drag that here and you can see that the response comes back in less than a second.
Normally, according on this dataset … Let’s see. all this stuff here. Normally, a query on this dataset takes, if we were just querying the raw data without the help of reflections, will take us something like maybe six to 10 minutes using kind of a sequential on this data and on this size of cluster. But the reflections basically help us make this much faster. So we can look here, an example. Again, this is a query run in Hive or kind of any other sequential would take us minutes. I can drag that here and you can see that the response comes back in less than a second. So we’ve just counted 1.03 billion records. I can group this by, let’s say, the drop-off time and see, okay, when are taxi trips, what year or how many taxi trips were there per year. So you can see here, we have about 170 million taxi trips every year. If I wanted to look at other things like the tip amount maybe and put that in the color here, and let’s change that to an average, you can see that everything here is fast, happening extremely fast. So all these response times are kind of sub-second response times. What we’re seeing is that the average tip amount has been going up from 2009 to 2014, that’s because the economy has been getting better, I think. If I’ve looked at it by month I could see that if I wanted to be a taxi driver, would be better to do that later in the year than earlier in the year when the tips are lower at the beginning of the year, July seems like anomaly. I kind of drill down by day and so forth. So you can see all this response time for the quarries that I’m running on this New York City Taxi trips dataset are extremely fast.
So we’ve just counted 1.03 billion records. I can group this by, let’s say, the drop-off time and see, okay, when are taxi trips, what year or how many taxi trips were there per year. So you can see here, we have about 170 million taxi trips every year. If I wanted to look at other things like the tip amount maybe and put that in the color here, and let’s change that to an average, you can see that everything here is fast, happening extremely fast. So all these response times are kind of sub-second response times. What we’re seeing is that the average tip amount has been going up from 2009 to 2014, that’s because the economy has been getting better, I think. If I’ve looked at it by month I could see that if I wanted to be a taxi driver, would be better to do that later in the year than earlier in the year when the tips are lower at the beginning of the year, July seems like anomaly. I kind of drill down by day and so forth. So you can see all this response time for the quarries that I’m running on this New York City Taxi trips dataset are extremely fast. If I go to the jobs screen here inside of Dremio, what I’ll see here is this flame here. This flame basically is an indicator that these queries got accelerated. You can see here that they got accelerated, and we even show here what reflection helped accelerate this data. So you can see there’s actually reflection not on that specific virtual dataset, but on this other dataset called trips with date that helped us accelerate this data. I can actually open up this reflection and see, okay, what does that reflection look like? This is a reflection, actually, that was created kind of attached to a dataset that was derived from the taxi dataset. It has, I think, some additional columns like the drop-off date. But you can see there are dimensions and measures here, and so it’s kind of a partial aggregation on that data. It’s consuming 79 megabytes as its footprint on this much larger dataset. So this is providing us with the ability to achieve much faster response time on this data. So it’s an example of reflections.
If I go to the jobs screen here inside of Dremio, what I’ll see here is this flame here. This flame basically is an indicator that these queries got accelerated. You can see here that they got accelerated, and we even show here what reflection helped accelerate this data. So you can see there’s actually reflection not on that specific virtual dataset, but on this other dataset called trips with date that helped us accelerate this data. I can actually open up this reflection and see, okay, what does that reflection look like? This is a reflection, actually, that was created kind of attached to a dataset that was derived from the taxi dataset. It has, I think, some additional columns like the drop-off date. But you can see there are dimensions and measures here, and so it’s kind of a partial aggregation on that data. It’s consuming 79 megabytes as its footprint on this much larger dataset. So this is providing us with the ability to achieve much faster response time on this data. So it’s an example of reflections. Now, users can operate, again, in the logical world. So a user may take this trip dataset and say, “You know what? I’m not happy with this data.” maybe I don’t need the vendor ID, so I’m going to drop that. Maybe I only want to look at … I want to rename passenger_count to passenger_num. I can go ahead and save this dataset as a new virtual dataset, give it a new name, maybe I’ll put in the same space called New York City taxi but I’ll call it trips_ without_vendor. Now this is a new virtual dataset. There was no cost to creating this new copy of data. It’s all logical. In fact, I can even see the definition of this dataset. So I can see passenger_count being renamed to passenger_num, and you’ll actually … I guess you won’t see that, but you may notice that vendor ID is no longer in this. So we’ve kind of trimmed down the … We’re projecting basically a subset of columns. If I go and query this dataset now from the BI tool, so if I go back to my BI tool, in this case, Tableau and I click on data source here.Let’s go to our space here, the New York City taxi space. I can drag the trips_without_vendor, and I can start querying this data. This will be just as fast. So you can see that just refreshed the quarry on this dataset, and that was fast, even though that’s a completely new kind of dataset that’s a different copy of the data. Let’s look at the quarter here, and that’s, again, a different query. You can see that I was able to aggregate based on the quarter extremely fast. If I go to the jobs, I can see these queries on the trips_without_vendor dataset here, see trips_without_vendors is the name of the dataset. Again, it’s being accelerated thanks to that same aggregation reflection that we were looking at earlier. So this is a very simple example of how reflections are providing orders of magnitude performance improvement.
Now, users can operate, again, in the logical world. So a user may take this trip dataset and say, “You know what? I’m not happy with this data.” maybe I don’t need the vendor ID, so I’m going to drop that. Maybe I only want to look at … I want to rename passenger_count to passenger_num. I can go ahead and save this dataset as a new virtual dataset, give it a new name, maybe I’ll put in the same space called New York City taxi but I’ll call it trips_ without_vendor. Now this is a new virtual dataset. There was no cost to creating this new copy of data. It’s all logical. In fact, I can even see the definition of this dataset. So I can see passenger_count being renamed to passenger_num, and you’ll actually … I guess you won’t see that, but you may notice that vendor ID is no longer in this. So we’ve kind of trimmed down the … We’re projecting basically a subset of columns. If I go and query this dataset now from the BI tool, so if I go back to my BI tool, in this case, Tableau and I click on data source here.Let’s go to our space here, the New York City taxi space. I can drag the trips_without_vendor, and I can start querying this data. This will be just as fast. So you can see that just refreshed the quarry on this dataset, and that was fast, even though that’s a completely new kind of dataset that’s a different copy of the data. Let’s look at the quarter here, and that’s, again, a different query. You can see that I was able to aggregate based on the quarter extremely fast. If I go to the jobs, I can see these queries on the trips_without_vendor dataset here, see trips_without_vendors is the name of the dataset. Again, it’s being accelerated thanks to that same aggregation reflection that we were looking at earlier. So this is a very simple example of how reflections are providing orders of magnitude performance improvement. Again, it doesn’t have to be … I was using one specific BI tool. You can use other tools like Qlik and Power BI and so forth, but I can also use just SQL queries or notebooks. So for my more technical users, they can go through the notebook here. Let’s look at an example here. The first example here just uses PyODBC to connect. So what we’re doing here is that same query, we’re looking at the average tip amount and counting the number of records from that New York City taxi trips dataset, and we’re grouping on the year, so we’re using the SQL extract function to extract the year from the timestamp. We can also use pandas. A lot of people in Python use pandas because that allows you more flexibility. In this case we’re using pandas and we’re calling the read SQL function here and basically getting kind of a table here with the year, the average tip amount and the number of trips in that year. You may remember the 170 million number that we were looking at through Tableau, we’re seeing the same thing here.Let’s look at some simple examples here. We can kind of rollup, do an aggregation rollup here. This is, we’re extracting the month, and so we’re taking that dataset and now looking at it by month. That was a simple example we also did in Tableau. Here what we’re doing is we’re actually looking at kind of raw data. So we’re looking at the drop-off time, the passenger count, the total amount, so three columns from this New York City taxi trips dataset, but we’re not aggregating. So here we’re just looking at, give me the records where the vendor ID equals VTS and the date portion of the timestamp is … This is Christmas, I guess, 2010. So if I run this, you can see that comes back extremely fast as well. So even though we have a billion records, I got a sub-second response time on a raw query, one that did not involve aggregating the data.So you can see that these are … I limited it to 10 just for display purposes, but you can see the drop-off time here. These are all passenger drop-offs that happened on the 25th of December in 2010. Number of passengers, the total amount. Let’s change this to 2014 and do another query here. You can see that, again, it comes back in less than a second. If I go to the jobs screen here and scroll up to the top, I can see these queries come in, and you can see this is the query that was just sent from the Jupyter notebook. Again, why did this get accelerated? Why does this have a flame here that caused it to come back in less than a second? Well, let’s just look at the accelerated by and see the reflection that was helping us accelerate this. So in this case it’s a raw reflection. You can see it has all these different columns, but it’s partitioned by the drop-off date. So these queries, because they are filtering on the drop-off date, this specific reflection, the optimizer was able to identify that it could utilize this reflection and look at a very, very small subset of the data and prune away the other partitions.Let’s go back here. Final example I have here is a one of a snowflake reflection. In this case, you can see what we’re doing is we’re doing a query … This is across three different tables. One of them is an Elasticsearch dataset called review. These are all the Yelp reviews. Another one is an elastic … Or sorry, a dataset inside of MongoDB with the businesses on Yelp, and then we have the users on Yelp. That’s a kind of the third one, it’s a simple inner join across these two. So review, think of that as the fact table. Businesses and users are the dimension tables. Then we’re grouping on city. So let’s look at that. We can see that comes back really fast. Let’s look at why that came back fast.Again, we’ll go to the jobs screen here, that’s the easiest way to kind of figure that out. You can see we have these three datasets, but why were we able to do that so fast? Well, we actually didn’t have to do that join in real time in this case. We used this reflection called by_business_location_and_user_cohort. It’s a reflection associated with reflections.ereviews. So we had created this virtual dataset, I happen to call it reflections.ereviews, so let’s click on that. I’m using the built-in data catalog here. You can see what this dataset is is basically a join between the business dataset in Yelp, the review dataset in Elasticsearch … Sorry, the business dataset in Mongo, review dataset in Elastic and the user dataset inside of Mongo.
Again, it doesn’t have to be … I was using one specific BI tool. You can use other tools like Qlik and Power BI and so forth, but I can also use just SQL queries or notebooks. So for my more technical users, they can go through the notebook here. Let’s look at an example here. The first example here just uses PyODBC to connect. So what we’re doing here is that same query, we’re looking at the average tip amount and counting the number of records from that New York City taxi trips dataset, and we’re grouping on the year, so we’re using the SQL extract function to extract the year from the timestamp. We can also use pandas. A lot of people in Python use pandas because that allows you more flexibility. In this case we’re using pandas and we’re calling the read SQL function here and basically getting kind of a table here with the year, the average tip amount and the number of trips in that year. You may remember the 170 million number that we were looking at through Tableau, we’re seeing the same thing here.Let’s look at some simple examples here. We can kind of rollup, do an aggregation rollup here. This is, we’re extracting the month, and so we’re taking that dataset and now looking at it by month. That was a simple example we also did in Tableau. Here what we’re doing is we’re actually looking at kind of raw data. So we’re looking at the drop-off time, the passenger count, the total amount, so three columns from this New York City taxi trips dataset, but we’re not aggregating. So here we’re just looking at, give me the records where the vendor ID equals VTS and the date portion of the timestamp is … This is Christmas, I guess, 2010. So if I run this, you can see that comes back extremely fast as well. So even though we have a billion records, I got a sub-second response time on a raw query, one that did not involve aggregating the data.So you can see that these are … I limited it to 10 just for display purposes, but you can see the drop-off time here. These are all passenger drop-offs that happened on the 25th of December in 2010. Number of passengers, the total amount. Let’s change this to 2014 and do another query here. You can see that, again, it comes back in less than a second. If I go to the jobs screen here and scroll up to the top, I can see these queries come in, and you can see this is the query that was just sent from the Jupyter notebook. Again, why did this get accelerated? Why does this have a flame here that caused it to come back in less than a second? Well, let’s just look at the accelerated by and see the reflection that was helping us accelerate this. So in this case it’s a raw reflection. You can see it has all these different columns, but it’s partitioned by the drop-off date. So these queries, because they are filtering on the drop-off date, this specific reflection, the optimizer was able to identify that it could utilize this reflection and look at a very, very small subset of the data and prune away the other partitions.Let’s go back here. Final example I have here is a one of a snowflake reflection. In this case, you can see what we’re doing is we’re doing a query … This is across three different tables. One of them is an Elasticsearch dataset called review. These are all the Yelp reviews. Another one is an elastic … Or sorry, a dataset inside of MongoDB with the businesses on Yelp, and then we have the users on Yelp. That’s a kind of the third one, it’s a simple inner join across these two. So review, think of that as the fact table. Businesses and users are the dimension tables. Then we’re grouping on city. So let’s look at that. We can see that comes back really fast. Let’s look at why that came back fast.Again, we’ll go to the jobs screen here, that’s the easiest way to kind of figure that out. You can see we have these three datasets, but why were we able to do that so fast? Well, we actually didn’t have to do that join in real time in this case. We used this reflection called by_business_location_and_user_cohort. It’s a reflection associated with reflections.ereviews. So we had created this virtual dataset, I happen to call it reflections.ereviews, so let’s click on that. I’m using the built-in data catalog here. You can see what this dataset is is basically a join between the business dataset in Yelp, the review dataset in Elasticsearch … Sorry, the business dataset in Mongo, review dataset in Elastic and the user dataset inside of Mongo. If I look at, click on the gear icon here to see the settings and I go to reflections, I can actually see … Well, we don’t have any raw reflections here, but we have two aggregation reflections. So we have one where we’re aggregating this three-way join by city and by state and by yelping_since, that’s the user cohort, what month did the user join Yelp. Then we have some specific measures like the review_stars and just, also of course, the number of records. Then we have a separate aggregation reflection, this one is by business_id, which is a higher cardinality column, so we didn’t do this one along with the other dimensions in the same reflection, we have it as a separate dimension here. Then, again, we’re using the measure as review_stars.But this is a three-way join, and the query that we just ran through the notebook was actually on those three exact tables. So that was kind of a relatively easy one for the optimizer to figure out, even though we’re not referencing the virtual dataset, which we could. We could have just queried the virtual dataset here and said, you know what? Instead of doing this join here, we could query … Let’s see what this dataset was called … Reflections.ereviews. So we could query reflections.ereviews instead of querying the join. So that’s if the user actually knew that that virtual dataset existed, they could do that and get the same response. Okay? But that’s not what we were doing. We were actually doing the join from the raw tables in the SQL itself, and the optimizer was smart enough to figure out that it could do a match there. The system knows how to deal with different orders of the joins and all sorts of different query structures. There’s a lot of different algorithms here that help us do these kind of matches in a smart way.But where you see the snowflake reflection technology really helping out here is, let’s say, the user only cared about reviews and businesses. So the user was looking at, you know, I want to see how many businesses there are per city, okay, and kind of sort them in descending order, then show the top 10 businesses by … Sorry, the top 10 cities by number of businesses, right? So in this case, we’re going to run that and see that that comes back really fast. We see that Las Vegas has the most businesses in this dataset, followed by Phoenix and Scottsdale. But we didn’t actually have a reflection for this specifically on this join.
If I look at, click on the gear icon here to see the settings and I go to reflections, I can actually see … Well, we don’t have any raw reflections here, but we have two aggregation reflections. So we have one where we’re aggregating this three-way join by city and by state and by yelping_since, that’s the user cohort, what month did the user join Yelp. Then we have some specific measures like the review_stars and just, also of course, the number of records. Then we have a separate aggregation reflection, this one is by business_id, which is a higher cardinality column, so we didn’t do this one along with the other dimensions in the same reflection, we have it as a separate dimension here. Then, again, we’re using the measure as review_stars.But this is a three-way join, and the query that we just ran through the notebook was actually on those three exact tables. So that was kind of a relatively easy one for the optimizer to figure out, even though we’re not referencing the virtual dataset, which we could. We could have just queried the virtual dataset here and said, you know what? Instead of doing this join here, we could query … Let’s see what this dataset was called … Reflections.ereviews. So we could query reflections.ereviews instead of querying the join. So that’s if the user actually knew that that virtual dataset existed, they could do that and get the same response. Okay? But that’s not what we were doing. We were actually doing the join from the raw tables in the SQL itself, and the optimizer was smart enough to figure out that it could do a match there. The system knows how to deal with different orders of the joins and all sorts of different query structures. There’s a lot of different algorithms here that help us do these kind of matches in a smart way.But where you see the snowflake reflection technology really helping out here is, let’s say, the user only cared about reviews and businesses. So the user was looking at, you know, I want to see how many businesses there are per city, okay, and kind of sort them in descending order, then show the top 10 businesses by … Sorry, the top 10 cities by number of businesses, right? So in this case, we’re going to run that and see that that comes back really fast. We see that Las Vegas has the most businesses in this dataset, followed by Phoenix and Scottsdale. But we didn’t actually have a reflection for this specifically on this join. What’s happening here in this case is that we’re utilizing kind of the power of snowflake reflections. Let’s see … Sorry, that’s the wrong cluster. Let’s go here to the jobs section, and we can see that this query that had just come in on these two datasets was accelerated using that exact same reflections. So the system was smart enough to understand that this specific reflection, even though it was defined in association with a three-way join, one of those joined tables, in this case Mongo.yelp.user, could actually be ignored because it wasn’t affecting the number of records in the reflections, basically a simple dimension table, and there’s always a match. So that’s an example of where a reflection, or snowflake reflections, are helping.
What’s happening here in this case is that we’re utilizing kind of the power of snowflake reflections. Let’s see … Sorry, that’s the wrong cluster. Let’s go here to the jobs section, and we can see that this query that had just come in on these two datasets was accelerated using that exact same reflections. So the system was smart enough to understand that this specific reflection, even though it was defined in association with a three-way join, one of those joined tables, in this case Mongo.yelp.user, could actually be ignored because it wasn’t affecting the number of records in the reflections, basically a simple dimension table, and there’s always a match. So that’s an example of where a reflection, or snowflake reflections, are helping. So you’ve seen a bunch of different examples of how the optimizer is able to leverage reflections and be smart enough to kind of substitute something in the original query plan with one of these reflections and increase the speed of the query by orders of magnitude. The nice thing is the user never has to worry about it. The user is always kind of operating on the logical datasets, right? The user goes in, and they just play with the data. There are all sorts of capabilities we haven’t shown here, like being able to curate the data, all sorts of transformation.So even non-technical users go into a dataset and say, you know what? Let’s say in this case it’s a dataset inside of MongoDB, but maybe logically I want to drop the _id column, and I want to look at a subset of the cities. We provide all these visual tools to give the non-technical users also the ability to kind of curate it on their own. But again, all in a logical world. No copies are being created here. So even as the user goes in here, maybe they want to flatten this array of categories that we have for each business into one category per record. So the user does all these things, no copies are being created. Even when I go and save this new dataset, and let’s save it in my own personal space and call this categories, this is a virtual dataset. That’s why it’s green here. Users can go and create hundreds or thousands of these datasets without any problem. Reflections are all about the performance. Virtual datasets are all about enabling users to curate data and look at data through different kind of lenses.
So you’ve seen a bunch of different examples of how the optimizer is able to leverage reflections and be smart enough to kind of substitute something in the original query plan with one of these reflections and increase the speed of the query by orders of magnitude. The nice thing is the user never has to worry about it. The user is always kind of operating on the logical datasets, right? The user goes in, and they just play with the data. There are all sorts of capabilities we haven’t shown here, like being able to curate the data, all sorts of transformation.So even non-technical users go into a dataset and say, you know what? Let’s say in this case it’s a dataset inside of MongoDB, but maybe logically I want to drop the _id column, and I want to look at a subset of the cities. We provide all these visual tools to give the non-technical users also the ability to kind of curate it on their own. But again, all in a logical world. No copies are being created here. So even as the user goes in here, maybe they want to flatten this array of categories that we have for each business into one category per record. So the user does all these things, no copies are being created. Even when I go and save this new dataset, and let’s save it in my own personal space and call this categories, this is a virtual dataset. That’s why it’s green here. Users can go and create hundreds or thousands of these datasets without any problem. Reflections are all about the performance. Virtual datasets are all about enabling users to curate data and look at data through different kind of lenses.
Sign up for AI Ready Data content




