Intro
Sources such as Hadoop support the ability to perform impersonation, i.e. the ability to access the source data as the user in Dremio. If the user cannot access specific datasets in the underlying source, then they will be unable to view the data for those datasets. However, as these permissions are independent of Dremio’s internal Sharing abilities, users will still see those datasets listed in the UI.
Let’s imagine that we have an application hosted in a web server. When the application tries to connect to the web server, it provides the credentials specific for this app in general. The application could be called example_app and therefore the app’s credentials for the web server could be something like example_app_login/example_app_pass_123.
But our application also has a lot of different users who have to log in before using this app. Although, each user has its own username and password which he/she enters to access the application, the application, in turn, uses its own username and password to access web server (not the credentials of the user which uses the app in a given moment of time). The situation when the app uses its user’s credentials to access the web server rather than its own credentials is called impersonation.
So, if impersonation is turned on, and the user with the username=test_user and the password=test_user_pass_987 executes some action which requires to access the web server, the app will use the credentials pair test_user/test_user_pass_987 rather than example_app_login/example_app_pass_123 to authorize in the web server.
Impersonation is an important security option, which developers or system administrators should care about when creating any solution. In this tutorial, we want to explain how to set up impersonation in the connections between Dremio, HDFS and/or Hive.
Assumptions
For this tutorial, we assume that your Dremio environment meets the minimum requirements, and also that you have Hadoop, and Hive installed. For this tutorial, we will use Ubuntu OS.
HDFS preparation
Prior to setting up Dremio, we need to upload at least 1 file to HDFS. We assume that you have a fresh Hadoop installation. So, you need to start HDFS nodes first:
~/<hadoop_folder>/sbin$ ./start-dfs.sh hadoop fs -mkdir -p /user/dremio
We will use a freely available Bank Marketing Dataset. The next command is used to upload a file bank-additional-full.csv from the local filesystem to previously created /user/dremio/ folder in HDFS:
hadoop fs -put /path/to/file/in/local/filesystem/bank-additional-full.csv /user/dremio
The last what we need to do with the target file is to change the ownership of this file in HDFS with the following command:
hadoop fs -chown -R dfesenko:hadoop /user/dremio/bank-additional-full.csv
Here the Dremio user (dfesenko) is assigned as an owner of the /user/dremio/bank-additional-full.csv file in the HDFS.
In order to complete the preparation of the HDFS we need to fulfill one more step. It is a change to the configuration files instead of the Terminal commands we used before. Find the core-site.xml file in the /etc/hadoop/ folder of the Hadoop’s directory. In this file, you should give Dremio process owner permission to impersonate anyone from any host. To do this, the following piece of configuration should be added to the file (if Dremio process owner is dremio):
<property>
<name>hadoop.proxyuser.dremio.hosts</name>
<value></value>
</property>
<property>
<name>hadoop.proxyuser.dremio.groups</name>
<value></value>
</property>This should be enough to prepare HDFS. The next step we need to complete is to connect Dremio to HDFS source and check if everything works as expected.
Dremio and HDFS connection
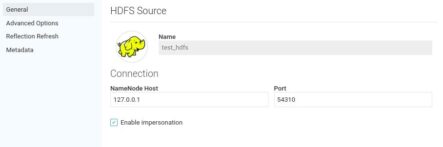
To connect the HDFS source to Dremio click on the “+” sign near the Sources on the main page of the Dremio UI. This will open the window where different connection details should be specified. We are interested only in General parameters:

We will use test_hdfs as the name of the source. As we use an HDFS cluster on a local machine, the NameNode Host parameter should be set to the localhost address (127.0.0.1). To fill the Port field, we need to get the port of the NameNode. If we open in the web browser the link http://localhost:50070/, the page which you can see below will appear. In the top header you will be able to see the port which you need to enter in Dremio (marked with a red circle):

Don’t forget to click on the Enable impersonation checkbox, which is our primary target here.
After the connection is completed successfully, we can check if everything works fine. The test_hdfs source should appear in the list of sources:

As you can see, the folder user is available. Remember that our file is located by the path: /user/dremio/bank-additional-full.csv. If you are logged as the user to which you give permissions to read the file, you can click on the user folder, then on the dremio folder, and then open the file bank-additional-full.csv. This will open the file and you will be able to start working with it in Dremio:

So, we added HDFS source to Dremio and enabled impersonation for this source. Now we want to do the same thing but for Hive source.
Hive preparation
We assume that you already have Hive properly installed and configured. Hive tables are stored in HDFS filesystem. In this section, we will use the same file with data to generate a Hive table from it and then connect Dremio to this table.
First, as for HDFS, in core-site.xml file, we should add configuration which allows both dremio process owner user and hive user to impersonate anyone from any host. Here is the code:
<property>
<name>hadoop.proxyuser.dremio.hosts</name>
<value></value>
</property>
<property>
<name>hadoop.proxyuser.dremio.groups</name>
<value></value>
</property>
<property>
<name>hadoop.proxyuser.hive.hosts</name>
<value></value>
</property>
<property>
<name>hadoop.proxyuser.hive.groups</name>
<value></value>
</property>
</configuration>Next, we need to create a Hive table. To do this, you should already have the following path: /user/hive/warehouse/. We will move the bank-additional-full.csv *file to the root Hive directory first. Then we will run the hive console using the command - *hive. The next step is to create a table with specific column names:
CREATE TABLE example_data (age string, job string, martial string, education string, default string, housing string, loan string, contact string, month string, day_of_week string, duration string, campaign string, pdays string, previous string, poutcome string, emp_var_rate string, cons_price_idx string, cons_conf_idx string, euribor3m string, nr_employed string, y string) row format delimited fields terminated by ";";
The table schema should be created after this command. But the table is still empty. Now we want to populate our table example_data with the data from the .csv file. The following statement could be used for this purpose:
LOAD DATA LOCAL INPATH "bank-additional-full.csv" INTO TABLE example_data;
After loading the data we can check if the operation was successful using the following commands, where the first checks the existence of the example_data table and the second checks the presence of data in the table.
SHOW TABLES; SELECT * FROM example_data LIMIT 3;
The image below demonstrates all the aforementioned operations and their respective outputs:

As we can see, the table was successfully created. The next step is to change directory ownership of the Hive table to reflect the username in Dremio:
hadoop fs -chown -R dfesenko:hadoop /user/hive/warehouse/example_data
Now, we can check the presence of the table in the specified directory of the HDFS and the ownership of the table:

Dremio and Hive connection
Now, it’s time to connect Hive to Dremio. Before making a connection you should run Hive metastore service:
hive --service metastore
In Dremio, click on the “+” button near the Sources, then pick Hive. On the General tab of the connection menu give a name to the data source (we choose test_hive). As we use Hive on the local machine, we will enter the localhost address (127.0.0.1). The default port is 9083. In the Authorization section, select the Storage Based with User Impersonation option.

On the Advanced Options tab we will add the following new property:
“hive.server2.enable.doAs” : “false”. Then click Save.

Now the test_hive data source and the example_data table should be available on the main page of the Dremio web UI:

You can open the example_data table and start working with it in Dremio:

This means that we added Hive source to Dremio and enabled impersonation for it.
Conclusion
In this article, we showed how to set up HDFS and Hive impersonation in their connection with Dremio. Let’s briefly recall the main steps that should be completed for proper setup of each of the data sources.
Steps to enable HDFS impersonation in Dremio:
1) Give the Dremio process owner permission to impersonate anyone from any host by modifying the core-site.xml file.
2) Change the ownership of the directory to correspond with the username in Dremio: hadoop fs -chown -R :hadoop /
3) When adding the HDFS source to Dremio, on the General page, select the Enable impersonation checkbox.
4) Log in as the user whose username was given ownership of the HDFS file(s).
5) The file(s) should be available for reading access.
Steps to enable Hive impersonation in Dremio:
1) Give the Dremio process owner permission to impersonate anyone from any host by modifying the core-site.xml file.
2) Give the hive user permission to impersonate anyone from any host by modifying the core-site.xml file.
3) Change the ownership of the table to correspond with the username in Dremio: hadoop fs -chown -R :hadoop/users/hive/warehouse/
4) When adding Hive source to Dremio, on the Advanced Options tab, add the key-value pair: “hive.server2.enable.doAs” : “false”.
5) Log in as the user whose username was given ownership of the Hive table(s).
6) The table(s) should be available for reading access.
Impersonation is a useful security setting which is often used to control the access and resources usage. Now you should be ready to work with HDFS and Hive impersonation in their connection with Dremio.
We hope you enjoyed this tutorial, stay tuned for more tutorials and resources to learn how you can use Dremio to start gaining insights from your data, faster.
Learn More




