
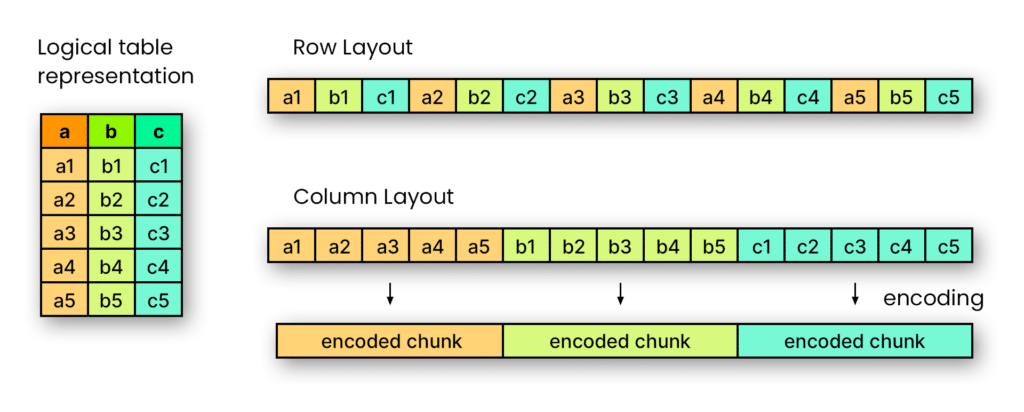
Apache Parquet is an open source file format that stores data in columnar format (as opposed to row format). As a columnar data storage format, it offers several advantages over row-based formats for analytical workloads. Your choice of data format can have significant implications for query performance and cost, so it’s important to understand the differences between Apache Parquet and other file formats.
Benefits of Apache Parquet
In simple terms, row-based formats such as CSV and JSON are (mostly) readable by humans, whereas column-based formats are optimized for computers. As a columnar file format, Apache Parquet can be read by computers much more efficiently and cost-effectively than other formats, making it an ideal file format for big data, analytics, and data lake storage. Some of Parquet’s main benefits are that it is high performance, has efficient compression, and is the industry standard.
High Performance
In Apache Parquet, each column’s values are stored together on disk. Because analytical queries often need only a subset of columns for an operation, this reduces the amount of data needed to be read.
Parquet files also have statistics about the data stored within the file, such as minimum and maximum values for the column’s data in the file, and how many rows are in that segment. This allows engines to skip entire segments or entire files based on what portion of the dataset the job is looking for.
These two features result in significant performance improvements and lowering overall costs, due to a reduction in the amount of data needed to be read.
Efficient Compression
Apache Parquet supports highly efficient compression. Many compression codecs are more effective when they compress similar data. Parquet’s columnar format means that columns of similar data can be compressed together, resulting in greater efficiencies.
Compressed data is more cost-effective to store than raw data, so using Parquet can reduce the cost of storing large data sets. Compressed data is also more performant to read than uncompressed data when I/O is the bottleneck, which can often be the case in analytical workloads, so compressed data in Parquet files can improve performance as well.
Industry Standard
Apache Parquet is the industry standard columnar file format. Parquet files can be read by just about every engine and tool out there. This provides you interoperability to use multiple tools today, and peace of mind you’ll be able to leverage new engines and tools that come out tomorrow, since they’ll most likely support Parquet.
Drawbacks of Apache Parquet
While Apache Parquet is the industry standard file format for analytical workloads, there are some drawbacks to be aware of. Different workloads and requirements may result in a different format for certain situations.
Binary-Based Files Cannot Be Read by Humans
Parquet is a binary-based (rather than text-based) file format optimized for computers, so Parquet files aren’t directly readable by humans. You can’t open a Parquet file in a text editor the way you might with a CSV file and see what it contains. There are utilities that convert the binary representation to a text-based one, such as parquet-tools, but it’s an extra step.
Slower Write Times
Parquet files can be slower to write than row-based file formats, primarily because they contain metadata about the file contents. For analytical purposes, these slower write times are more than made up for by fast read times. However, for situations where data freshness and event latency are most important (e.g., in the 10s of milliseconds range), it can be worth leveraging a row-based format without statistics like Avro or CSV.
Apache Parquet vs. CSV
The most common file format in the world at large is CSV (comma-separated values). It’s used by familiar applications like Microsoft Excel or Google Sheets. While CSV files are easily opened for human review and some data analysts are comfortable working with large CSV files, there are many advantages to using Apache Parquet over CSV.
Advantages of Parquet Over CSV
Analytics
Parquet is better suited for OLAP (analytical processing) workloads than CSV. CSV is good for interchange because it’s text-based and a very simple standard that’s been around for a very long time, but Parquet’s columnar structure and statistics enable queries to zero in on the most relevant data for analytic queries by selecting a subset of columns and rows to read. By contrast, a row-based format like CSV requires you to read the entire file, and where a table is composed of CSV files, the whole table/partition.
Where Performance Matters
Because queries are only made on a subset of columns rather than against the entire dataset, entire files can be skipped if the query doesn’t ask for it. Parquet has much better compression, and responses are much faster with Parquet than with CSV.
More Cost-Effective
Parquet can result in significant cost savings both in I/O and storage compared to CSV. For example, after converting from CSV to Parquet, data-as-a-service firm Veraset was able to reduce by half the time it took to run its data pipeline and reduce the infrastructure required for an annual savings of half a million dollars.
Apache Parquet vs. Apache Avro
Apache Avro is also a binary file format, like Parquet. However, Avro is a row-based file format, similar to CSV, and was designed for minimizing write latency. Avro files have far fewer rows per file than Parquet, sometimes even just one row per file. The most common use case for Avro is streaming data.
Parquet has the same advantages over Avro as it does over CSV. It's better for analytics, has better performance, and is more cost-effective.
Advantages of Avro over CSV
Apache Avro files have the schema of the records embedded in the file. This is especially useful in streaming analytics, such as when the schema of the application producing the data can change over time.
Avro is also a binary protocol, providing better read performance than CSV.
Advantages of CSV over Avro
The main advantage of CSV over Avro is due to the fact that it is a text-based file format. This makes it more human-readable, which can be easier for exchanging smaller files with people not familiar with the data, such as other business units or external organizations.
Ready to go deeper? Read more technical articles on Apache Parquet.




