

Getting Your Data to the Lake
AUTOPLAY JOURNEY OR CLICK PHASES FOR MORE DETAIL

Security and governance management
Self-managed data copies
Platform-managed data copies
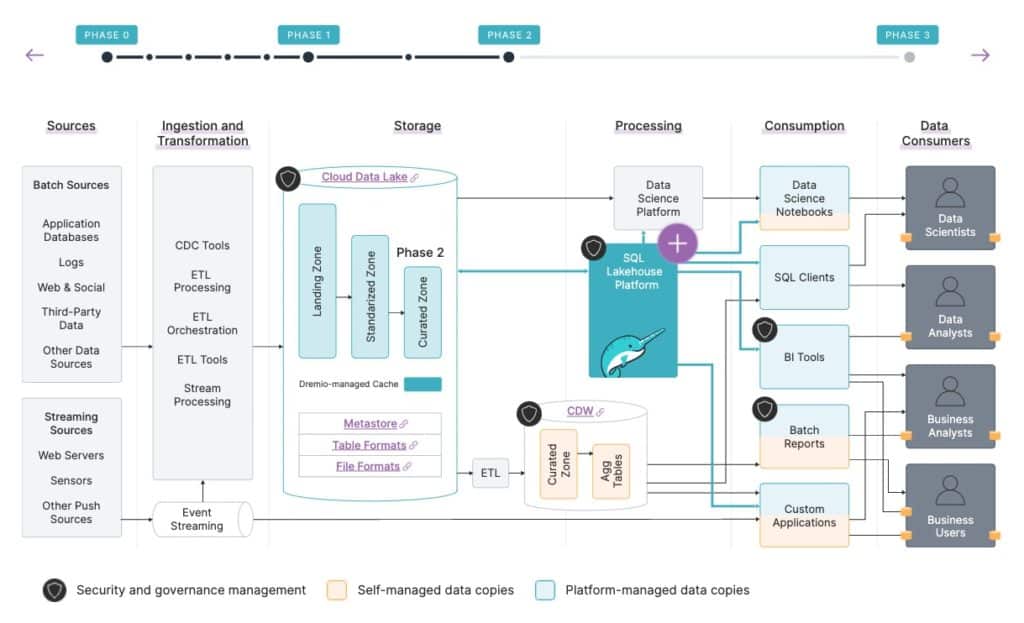
Data from the various sources is first loaded into the data lake by ETL, CDC, and streaming tools, in its raw form to the "landing zone".
Then, it is taken through a series of processing steps for it to be in a structure that can be used by the data consumers, first getting the data in a “standardized” form so users can understand the structures and trust the data quality, then further “curating” it so even more users who aren't as familiar with the data can leverage it.
Now the data is in a form in the cloud data lake that all users should be able to leverage, so most companies provide users with a SQL engine to query their data lake. However, this engine is only sufficient for non-interactive workloads.
For interactive workloads, there are two main problems that traditionally prevent them from running directly on the data lake - performance and ease of use.
The only way to address these limitations of the non-interactive engines in the past has been with data copies, traditionally into a data warehouse.
In order to meet interactive workloads requirements, data engineers need to write and operationalize ETL jobs to copy the data into the cloud data warehouse (CDW).
CDWs are cost prohibitive and aren’t performant enough on the granular data, so it’s further copied and transformed into “aggregation tables”. Different businesses units need to view the data differently, again requiring copy and transformation of the data into “data marts”.
Security and governance need to be implemented and maintained in these environments, on an upfront and on an ongoing basis.
A lot of dashboards and reports still can't deliver the desired performance, so data engineers and/or data SMEs need to coordinate with the people actually building the dashboards and copy the data yet again, creating and operationalize the necessary BI extracts to provide that performance.
Permissioning also needs to be applied in the BI tool.
In addition to all of these data copies within your environment, you also have people copying data to their laptops because they can't access all the data they need from one system and/or they can't get the performance they need.
Now that they have data on their laptops though, you've lost all control and visibility of that data!
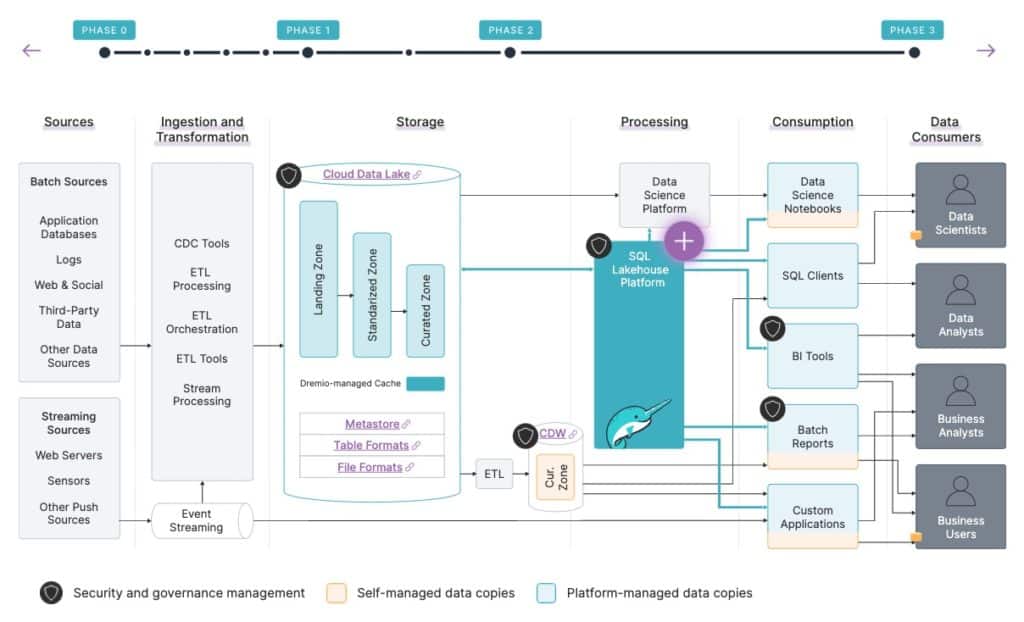
The first step of the journey is simply to add Dremio to your environment. No need to rip & replace any other systems. Identify a set of use cases you want to migrate first for quick wins. Then gradually larger use cases and workloads.
In parallel, Dremio can be rolled out to users for direct access. These users now have the option to connect and use Dremio from their BI tools and SQL clients, especially for their ad-hoc needs.
While it requires some planning, it’s generally straightforward to migrate the workloads that currently run on the non-interactive data lake engine.
Once the migration of those workloads is complete, you're able to retire your non-interactive data lake engine because all of those workloads are now running on Dremio.
For the interactive workloads that needed to run in the CDW, a lot of them can now run on Dremio instead, reducing the footprint of your CDW.
As you migrate the workloads to Dremio different business units are now able to achieve their org-specific view of the data virtually in Dremio’s semantic layer, which removes the need for the data mart copies.
You're also able to eliminate BI extracts from your environment, because instead of needing to extract data from the CDW to provide BI users with interactivity, these BI dashboards now run live queries directly against Dremio, which provides such interactivity without BI extracts.
Users also have a much lower need to download data to their laptop to get their job done, because Dremio is able to provide self-service interactivity directly on all the data in the data lake and allow users to upload their own datasets to integrate with data already in the data lake, addressing most of the reasons users download data to their laptops.
You can see that Dremio has eliminated the need for the BI extracts and data mart copies, reduced the amount of data copies your users need to download, and reduced the footprint of the CDW.
You can also see that based on the shading of the consumption boxes, less data usage throughout the organization is based on the orange unmanaged and often stale data copies created through brittle ETL processes.
This process of migrating workloads to Dremio is a continual process, as you'll see in the next phase.
This is where many of our customers are today and what their analytics architecture looks like.
Depending on the specifics of their workloads, some customers choose to keep some workloads on the CDW for the time being.
As lakehouse architectures continue to mature, these workloads are fewer and fewer.
With this architecture, customers are able to provide much faster time to insight and truly deliver on the promise of data democratization, therefore greatly increasing the business value obtained from their data, while still ensuring security and governance.
Now in this future state, you can address all workloads that have required the DW in the past.
Provide users with the performance, access, and ease of use that eliminates the need for data copies.
They’re able to fully meet the business requirements while providing reduced operational overhead, data drift, costs, and security & compliance risks. Resulting in rapid time to insight, true data democratization for all workloads and users, further increasing the ROI of data!!
Traditional Data Architecture Is Broken
Traditional data tools have not kept up with the explosive growth of data today and the level of access that is required throughout the organization to drive the business forward. To overcome these limitations, data users such as data analysts and business decision-makers have resorted to techniques that result in an excessive proliferation of data copies that impact real-time visibility, accuracy, security, and innovation.
Data users such as data analysts, business analysts, and data scientists need to perform analysis and gain insights from the data in order to do their jobs. Data needs to be collected from various sources into a place and form where users can access the data in a performant way. Data from the various sources is first loaded into a data lake by some combination of extract transform and load (ETL), change data capture (CDC), and streaming tools, where it is written in its raw form to the "landing zone" for ease of ingest as well as retention purposes.
Then, the data is taken through a series of steps to process it into a structure that can be used by the data consumers. This includes getting the data into a standardized form so users can understand the structures and trust the data quality. Additional curation may be required for users who aren't as familiar with the data and can also benefit. At this point, the data is housed in a cloud data lake (such as Amazon S3 or Microsoft ADLS) in a form that all users should be able to leverage. Most companies provide users with a SQL engine to query the data lake, however, it is only sufficient for non-interactive workloads.
For interactive business intelligence (BI) workloads, there are typically two main problems that prevent running directly on the data lake: performance and ease of use. The only way to address the limitations of non-interactive engines in the past has been with data copies.
Typically, data engineering teams spend a lot of time writing and operationalizing ETL jobs via complex data pipelines to copy the data into a cloud data warehouse (CDW). Unfortunately, data warehouses are cost prohibitive, so not all of the data is loaded into them.
Additionally, data warehouses often aren’t performant enough on the granular data, so it’s further copied and transformed into aggregation tables. Different lines of business (LOB) view the data differently to make best use of the data, so data engineering must collaborate with each business unit to again copy and transform the data into data marts. Security and governance also need to be implemented and maintained in each of these environments, and security permissions need to be copied and managed on an ongoing basis.
To further compound the problem, dashboards and reports are unable to achieve the performance needed, so data engineering and/or data subject matter experts (SMEs) must coordinate with the people actually building the dashboards, and then create and operationalize the necessary BI extracts to provide that performance. Permissioning also needs to be applied in the BI tool.

TCO Considerations of using a Cloud Data Warehouse for BI and Analytics
GET THE TCO EXEC BRIEFIn addition to the plethora of data copies within your environment, people are copying data to their laptops because they can't access all the data they need from one system and/or they can't get the performance they need. With your data on their laptops, you’ve lost all control and visibility into it.
End users probably send their data to other people too, so now they are the ones making the decisions. Plus, they probably don't know exactly when the source data gets updated, which often leads to inaccurate information and different sets of numbers.
It is clear that this approach is riddled with challenges:
- Data copies mean more operational overhead, less productive data engineers, data drift, higher costs, higher security risk, and greater compliance risk
- Every time business requirements change or a new business question needs to be answered, it can take weeks to address the new requirement from a business analyst standpoint, and it’s frustrating for your data engineers, data architects, and IT/analytics leaders
- With ad hoc and exploratory analysis to address new business questions, the amount of business value gathered in a given amount of time is severely limited
- Consequently, you impact productivity, miss new revenue opportunities, and lose competitive advantage
With all these downsides: Why is this an industry-standard data architecture? The answer is simple: It’s because this has actually been the best way given the available tools at the time.
Interactive Data Lake Engine for Self-Service Analytics
Dremio is the new platform without the limitations of traditional tools. The improvements in time to insight and data democratization increase the business value obtained from your data, while ensuring security and governance. It may sound like a daunting task to resolve these issues by migrating your workloads to a new platform/tool, but as with any migration, it's a phased journey.
The following details some of the milestones of that journey. And while each organization’s journey will be slightly different, these are the phases our customers have experienced. The first step is to simply add Dremio to your environment. You don't need to immediately decommission, or rip and replace other systems in your environment.
With Dremio, you can identify a set of use cases you want to migrate first for a quick win. This iterative process then repeats, initially on a smaller number of use cases, and then gradually on larger use cases and workloads. There is also typically an assessment of a broader set of use cases and workloads, which are prioritized. Dremio can be rolled out simultaneously to users for direct access.
Users now have the option to connect and use Dremio from their BI tools and SQL clients such as Tableau and Microsoft Power BI, especially for their ad hoc query needs. While it requires some planning, it’s straightforward to migrate the workloads that currently run on a non-interactive data lake engine. Again, this can happen in an iterative fashion. Once the migration of those workloads is complete, you can retire your non-interactive data lake engine because those workloads are now running on Dremio’s interactive data lake engine.
When new workloads and use cases arise, they can be implemented directly on Dremio. Many of the interactive workloads that once ran on the cloud data warehouse (CDW), can now run on Dremio, and reduce the footprint of your data warehouse as you migrate the workloads to Dremio.
Different business units can achieve their org-specific view of the data via Dremio’s self-service semantic layer, which removes the need for data mart copies. BI extracts can be eliminated from your environment because data no longer needs to be extracted from the CDW to provide BI users with interactivity. These BI dashboards can now run live queries directly on Dremio without BI extracts.
Twelve Considerations when Evaluating Data Lake Engine Vendors for Analytics and BI.
DOWNLOAD THE RFI EXEC BRIEF
Users no longer need to download data to their laptops to get their jobs done. Dremio provides self-service interactivity directly on the data lake and allows users to upload their own datasets to integrate with data already in the data lake, addressing most of the reasons users download data to their laptops in the first place. Data scientists can also leverage Dremio for business datasets and standard KPI definitions in their work. They're able to access standard definitions to enrich their machine learning models, and utilize Apache Arrow Flight for very high speed data transfer.
Once migration is complete, there is now less data usage throughout the organization on unmanaged and often stale data copies created through brittle ETL processes.
"Dremio as a next-generation data lake engine."Dremio allows business users to access data easily. Standardized semantic layer eliminates the need for copying and moving data — no more cubes, aggregation tables, or extracts — and recurring instances of data drift. Accelerate dashboards and reports: Integrate BI tools such as Tableau, Power BI directly with Dremio and accelerate dashboard/reporting queries. Accelerate ad hoc queries: driving lightning-fast queries directly on your data lake storage. Dremio’s combination of technologies — including an Apache Arrow-based engine.


"Made us rethink our whole architecture!"
Application System Architect
"Flexibility in data management."
Head of Big Data and Analytics Competency Center
"Turn on the lights on the data lake."
Business Intelligence Director
"Simplify Data Engineering."
Lead Data Engineer
Over time, more and more workloads are migrated off the data warehouse, reducing its footprint, data copies, and associated costs. The need for batch reports also decreases, since they can be migrated to run in more interactive, real-time, and online tools housed in Dremio.
Future-Proof Your Data Architecture with Dremio
As you continue on the phased journey, you need to consider the legacy applications and workloads with specific requirements that still need to run on the cloud data warehouse (CDW) — mainly workloads where the data consumer needs to modify datasets. Typically, these modifications are either workarounds for performance or development purposes or remain in place to avoid training large groups of data consumers on this new approach.
Our customers indicate that some of these workloads can be achieved on Dremio by utilizing Dremio’s proprietary virtual datasets and reflections features. Further, with rapid adoption of the next generation of open table formats, like Apache Iceberg and Delta Lake, data lakes can fill the gap of data consumers modifying datasets that still require a data warehouse.
With Dremio, you can provide users with the performance, access, and ease of use that eliminates their practice of downloading and sharing copies of the data. As a result, your teams can fully meet business requirements while reducing operational overhead, data drift, costs, security, and compliance risk.
Proof of Concept (POC) Guide for SQL Query Accelerator
GET THE POC GUIDE
Future-proof your business with rapid time to insight and truly deliver on the promise of data democratization for all workloads and users throughout the organization, further increasing the business value from your data and business agility.
Take the Next Step
No matter where you are in your enterprise data architecture journey, getting started with Dremio is easy.

Data Modernization Consultation
Talk to a data analytics and BI expert about modernizing your data architecture with a cloud data lake and lakehouse platform.
Learn MoreHow can Dremio help?
Dremio is the SQL Lakehouse company, enabling companies to leverage open data architectures to drive more value from their data for BI and analytics.

