

In today’s modern data lakes, you work with a separation of data and metadata with open table formats like Apache Iceberg giving you vastly improved query performance, the ability to time-travel, evolve your table’s partitions/schema, and much more.
Open table formats rely on metadata catalogs to track where the metadata lives so engines can access the tables using these formats. Tools like AWS Glue, Hive, and JDBC/ODBC-compatible databases can be used for this purpose, but they weren’t created expressly for open table formats like Apache Iceberg.
Project Nessie is a transactional catalog built for tracking the metadata of tables created with open table formats, enabling a Git-like experience for better data collaboration, quality assurance, and multi-statement transactions on the data lake.
Let’s explore Project Nessie and show how to create an Iceberg table tracked inside of a Nessie catalog.
What Is Project Nessie?
Project Nessie provides Git-like capabilities for the data lakehouse.
In software development, you often need several developers to make different changes to a codebase using different tools simultaneously. In the early days of FTP file uploads, this would result in people overwriting each other’s work and breaking updates. In modern development, this problem is solved using Git versioning.
With Git, if you want to make changes to a codebase without affecting everyone else, you can make a branch that isolates your changes. When your changes are complete, verified in QA testing, and ready to be part of the main codebase, you can merge your branch and incorporate all the changes into the main branch at the same time, with no risk of changes being partially applied.
A Git commit is essentially an object that tracks all changes to the files since the last commit. When you create a branch, the commit chain follows a new path until you join them again by merging. Commits allow you to “time-travel” and revert your code to any previous state, and branches allow you to isolate changes to a separate path until they are ready to be merged and exposed to everyone.
Git commits and branches provide several benefits:
- If you want to work on a new feature or a bug fix you can create a new branch to isolate your changes, then merge them when they have been QA’d.
- If bad code is pushed into production, repairing the application is as simple as rolling back to the most recent working commit.
- If you need to refer to some code, you wrote that is no longer in the current state of the codebase you can inspect previous commits.
- When reviewing code to be added to the code base, you can generate a list of differences, making code review and QA much easier.
In the diagram below, each circle represents a Git commit. You can see how a new branch represents an isolated path that can later be merged, bringing all the changes from the feature branch into the main branch.
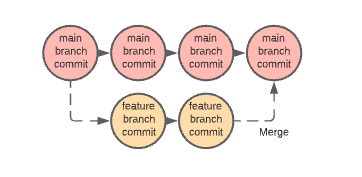
Project Nessie brings this Git-like workflow and benefits to your data stack. Nessie is a transactional metastore that tracks the state and changes of all tables in the catalog through metadata via commits and alternate isolated branches like Git. Nessie provides just as much functionality as Hive or AWS Glue as the data catalog, and so much more, for example, the ability to create branches of your entire catalog to be referenced and merged, and Git does software development.
How Would You Use Nessie?
So how would all this work? The first step is to have a Nessie server with which your engines (Spark, Flink, Hive) can send requests when they create, read, update, or delete a table (this can also be provided for you with a managed service like Dremio Arctic). The engine would then have to be configured to write to the Iceberg Table format. This is all much simpler than it sounds.
The simplest way to start a server is to use the Nessie Docker image following the instructions from the Nessie documentation. Simply run the following command and a Nessie server will be running on your machine in a few moments (you must have Docker installed):
docker run -p 19120:19120 projectnessie/nessie
You can then install the Nessie CLI using Python with the following command (must have Python installed):
pip install pynessie
That’s it, you have a Nessie server running and you can send it commands using the CLI. Keep in mind that Nessie manages the versions of the catalog (the list of tables and their metadata locations) not individual tables in the same way a Git branch does for the entire codebase, not individual files.
The CLI Commands
Let’s explore the Nessie CLI and what it allows you to do. (any <> brackets should denote placeholders)
| Command | Purpose |
nessie branch | List all branches |
nessie branch <new_branch> | Create a new branch from the main branch |
nessie branch <new_branch> <old_branch> | Create a branch from the specified branch |
nessie branch <new_branch> <hash> | Create a new branch from the specified hash |
nessie content list -r <branch> | List content in a branch |
nessie content view -r <branch> <key> | View a particular content item in a branch |
nessie content commit -m <message> -r <branch> <key> | Commit the particular content to the specified branch with the specified commit message |
You can read more at the Nessie CLI documentation.
Adding Tables to the Catalog
With the Nessie catalog you can work with the Nessie server to create catalog-level commits and branches; this doesn’t do much for you if there aren’t any tables in the catalog. You can make Iceberg tables using Dremio Sonar, Spark, Flink, or Hive. Let’s create a few tables in your Nessie catalog using Spark.
Shut down the Docker container you currently have running with Nessie and create an empty folder on your computer and create a docker-compose.yml file with the following contents:
#### Nessie + Iceberg Playground Environment
services:
spark-iceberg:
image: alexmerced/nessie-sandbox-072722
ports:
- "8080:8080"
- "7077:7077"
- "8081:8081"
nessie:
image: projectnessie/nessie
ports:
- "19120:19120"After creating the docker-compose.yml, in the terminal from that directory, you can spin it up by running this command:
docker-compose up
Then you will want to open up the terminal inside the Spark container with the following command:
docker-compose run spark-iceberg /bin/bash
Once inside your Docker container, you can run the following command:
source nessie-init2.bash
This command will open SparkSQL configured for Iceberg tables using a Nessie catalog. The underlying command and the configurations it will run are below:
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.2_2.12:0.14.0,org.projectnessie:nessie-spark-3.2-extensions:0.40.1 --conf spark.sql.extensions="org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,org.projectnessie.spark.extensions.NessieSpark32SessionExtensions" --conf spark.sql.catalog.nessie.uri="http://nessie:19120/api/v1" --conf spark.sql.catalog.nessie.ref=main --conf spark.sql.catalog.nessie.authentication.type=NONE --conf spark.sql.catalog.nessie.catalog-impl=org.apache.iceberg.nessie.NessieCatalog --conf spark.sql.catalog.nessie=org.apache.iceberg.spark.SparkCatalog --conf spark.sql.catalog.nessie.warehouse=$PWD/warehouse
The configuration flags being passed are doing the following:
- Making sure Spark uses the Nessie and Iceberg packages
- Enabling the Nessie and Iceberg extensions
- Setting the URL of the Nessie server
- Setting the default branch for SQL commands
- Setting the authentication type to NONE
- Creating a Spark catalog and setting it to a Nessie implementation
- Identifying where the files will be warehoused
Now let’s create a table:
CREATE TABLE nessie.db.table (name STRING) USING iceberg;
Now let’s create some data:
INSERT INTO nessie.db.table (name) VALUES ('Bob'), ('Steve');Let’s create a branch using Nessie:
CREATE BRANCH IF NOT EXISTS my_branch IN nessie;
You can see a list of all branches by running:
LIST REFERENCES IN nessie;
Let’s add records on the branch:
INSERT INTO nessie.db.`table@my_branch` VALUES ('Adam'),('James');Let’s query the table’s “main” branch and “my_branch” branch:
SELECT * FROM nessie.db.table;
SELECT * FROM nessie.db.`table@my_branch`;
In both queries, you can see Bob and Steve, but only in the query of “my_branch” do you see Adam and James. This illustrates that your changes are being isolated on the branch. This allows you to update, delete, and insert new data without interrupting queries on the main branch.
Eventually, you may want to merge your changes to all tables within your branch into the main branch which can simply be done by following this command:
MERGE BRANCH my_branch INTO main IN nessie;
So now if you query the main branch again you’ll see all four names:
SELECT * FROM nessie.db.table;
This branching strategy allows data engineers to isolate many transactions across several tables and, when ready, merge them as one multi-table transaction into the main branch.
Data consumers don’t need to be aware or impeded by ETL processes since they happen on a branch where quality control of the data can be managed and merged.
Conclusion
Project Nessie brings some truly new possibilities to working with data in a way that maximizes the efficiency and integrity of the data. With Iceberg tables in a Nessie catalog branch, multi-table transactions, partition/schema evolution, time-travel, and version rollback become part of how you can work with your data on the lake. Below are some additional resources on working with Project Nessie and Dremio Arctic, which provides a Nessie catalog as a service along with many other features:
- Blog: A Notebook for Getting Started with Project Nessie, Apache Iceberg, and Apache Spark
- Blog: Managing Data as Code with Dremio Arctic – Easily Ensure Data Quality in Your Data Lakehouse
- Video: Setting Up and Using a Dremio Arctic Catalog
- Video: Data Lakehouse using Apache Iceberg, Project Nessie and Apache Spark
- Video: Accessing a Dremio Arctic Catalog from Spark

