Cloud data warehouser Snowflake is supporting the Apache Iceberg open table format alongside its own native data table formats.
Iceberg is an open source table format for large-scale datasets in data lakes, layered above storage systems like Parquet, ORC, and Avro, and cloud object stores such as AWS S3, Azure Blob, and the Google Cloud Store. It provides database-like features to data lakes, such as ACID support, partitioning, time travel, and schema evolution, and enables SQL querying of data lake contents.
Christian Kleinerman, Snowflake’s EVP of Product, stated: “The future of data is open, but it also needs to be easy.”
“Customers shouldn’t have to choose between open formats and best-in-class performance or business continuity. With Snowflake’s latest Iceberg tables innovations, customers can work with their open data exactly as they would with data stored in the Snowflake platform, all while removing complexity and preserving Snowflake’s enterprise-grade performance and security.”
Snowflake says that, until now, organizations have either relied on integrated platforms, like Snowflake, to manage their data or use open, interoperable data formats like Parquet. It says its Iceberg support means that “customers now gain the best of both worlds. Users can store, manage, and analyze their data in an open, interoperable format, while still benefiting from Snowflake’s easy, connected, and trusted platform.”
Snowflake with Iceberg accelerates lakehouse analytics, applying its compute engine to Iceberg tables with two go-faster features coming soon: a Search Optimization service and a Query Acceleration Service. It is extending its data replication and syncing to Iceberg tables; now in private preview, so that customers can restore their data in the event of a system failure, cyberattack, or other disaster.
Snowflake says it’s working with the Apache Iceberg community to launch support for VARIANT data types. It’s also focused on working with other open source projects.
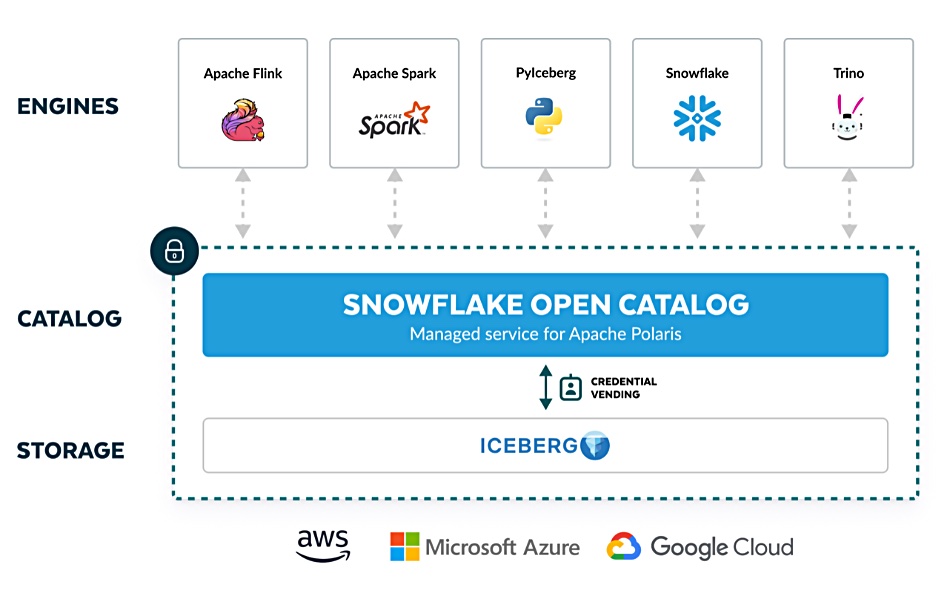
In June last year Snowflake announced its Polaris Catalog, a managed service for Apache Polaris and a vendor-neutral, open catalog implementation for Apache Iceberg. Apache Polaris is an open-source catalog for Apache Iceberg, implementing Iceberg’s REST API, enabling multi-engine interoperability across a range of platforms, including an Apache trio: Doris, Flink, and Spark, plus Dremio, StarRocks, and Trino. Now Snowflake is getting even closer to Iceberg.
Other Snowflake open source activities include four recent acquisitions:
- Apache NiFi: Datavolo (acquired by Snowflake in 2024) and built on NiFi, simplifies ingestion, transformation, and real-time pipeline management.
- Modin: Snowflake accelerates pandas workloads with Modin (acquired by Snowflake in 2023), enabling seamless scaling without code change.
- Streamlit: Snowflake’s integration with Streamlit (acquired by Snowflake in 2022) allows users to build and share interactive web applications, data dashboards, and visualizations with ease.
- TruEra: TruEra (acquired by Snowflake in 2024) boosts AI explainability and model performance monitoring for bias detection, compliance, and performance insights.
Competitor Databricks acquired Tabular, and its data management software layer based on Iceberg tables, last year. Iceberg and Databricks’ Delta Lake are both based on Apache Parquet. Snowflake has now, like Databricks, recognized Iceberg is beginning to dominate.

