20 minute read · June 2, 2022
Enabling a Data Mesh with an Open Lakehouse
· Principal Product Manager, Dremio
The data mesh has become a hot discussion topic among data architects and engineers, as a means to combat the pitfalls of centralized, monolithic data management practices that have grown commonplace.
In its current form, the data mesh is an organizational and architectural approach to enabling efficient data management and consumption at scale, characterized by a set of core principles. The principles are straightforward, but their interpretation and subsequent implementation have largely been left as an exercise to the reader.
In this blog, we will tackle the above exercise, and explore how companies can use an open lakehouse architecture to implement a data mesh supporting a broad range of analytical use cases.
How we got here
Data warehouses are a common system of record for data-driven organizations. However, they lead to organizations becoming overly reliant on centralized data engineering teams to manage complex data pipelines into their warehouses and make data available to downstream users and apps.
The consequences here are well-known. Data consumers can’t analyze the data they want quickly enough, and they can’t experiment and share data without help from data engineers. Data engineers spend too much time creating derived datasets and managing ETL/ELT flows, and need to work closely with data consumers to ensure they don’t lose business context when preparing datasets. It’s no surprise that a decentralized, self-service approach to analytics has emerged as the topic of the day, and an objective of everyone in the organization.
The data mesh aims to solve the issues above from both an organizational and technological standpoint, through four core principles:
- Domain-oriented, decentralized data ownership and architecture: Data is owned by domain teams who know it best, instead of centralized data engineering teams who have less business context around it.
- Data as a product: Domains are responsible for treating their data as a first-class product within the company, now that they have full ownership of it. This includes ensuring their data products meet their organization’s quality, availability, and freshness SLAs.
- Self-service data infrastructure as a platform: Domains need a platform that enables self-service data discovery, data product creation and distribution/sharing, and data consumption.
- Federated computational governance: Data teams need to ensure interoperability between decentralized teams by standardizing appropriate global components e.g., governance rules and taxonomy.
The first two core principles are grounded in organizational alignment, and prescribe a mindset where individual teams within a company think about their data as a first-class product that they own end to end. However, a solid technical foundation is critical in enabling this mindset, which drives the need for the second two core principles.
An open data lakehouse is the ideal architecture to power a data mesh, and enable self-service data engineering and analytics alongside federated computational governance. Data in an open lakehouse is stored in truly open file and table formats such as Apache Iceberg and Apache Parquet, which are developed and maintained by a large number of companies and individuals rather than a single vendor. Openness eliminates vendor lock-in and gives domains the flexibility to use the best engines to support their use cases, both today and in the future. For example, today, Iceberg is supported by the broadest set of engines, including Dremio, Amazon Athena, Amazon EMR, Snowflake, Presto, and Flink.
Dremio as the technical platform to support a data mesh
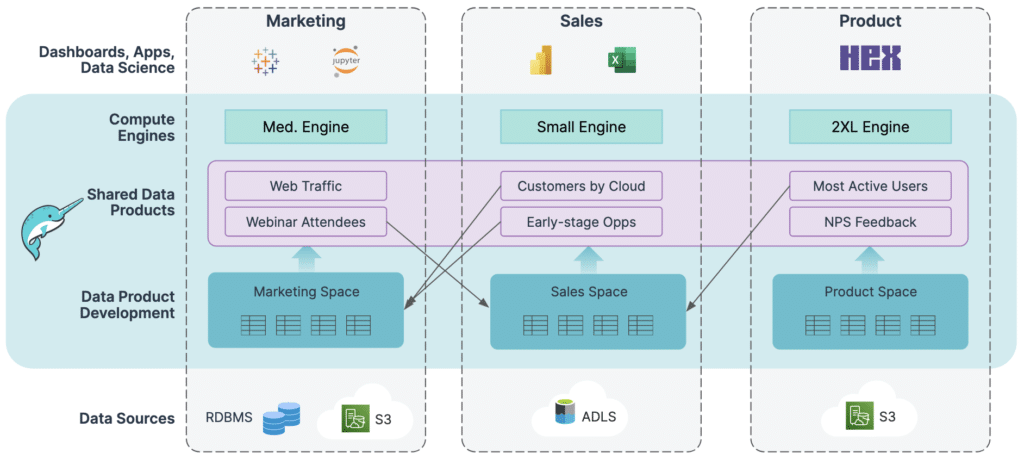
Dremio’s easy and open data lakehouse platform is the easiest way to implement a data mesh to support analytical workloads.
More specifically, Dremio provides four fundamental capabilities required to support a data mesh:
- A semantic layer that enables organizations to model a domain-based organizational structure, and enforce standard, fine-grained access policies.
- An intuitive UX that gives domains a self-service experience to create, manage, document, and share data products, and discover and consume other domains’ data products.
- A lightning-fast query engine that supports all SQL-based workloads, including mission-critical, low-latency BI dashboards, ad-hoc queries, data ingestion, and data transformations.
- A metastore service that brings a full software development lifecycle experience to data products, and ensures data engineers meet stringent availability, quality, and freshness SLAs for their data products.
Below, we’ll see how organizations can use these capabilities together to implement a data mesh.
Creating the foundation for a domain-oriented architecture
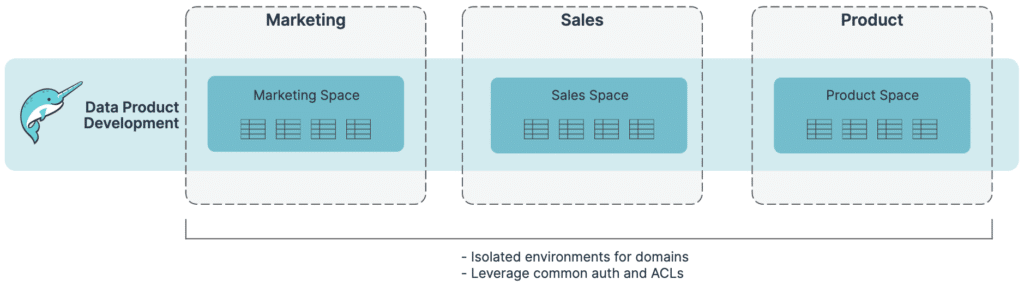
Domain modeling: Data teams can easily use Dremio’s semantic layer to model a domain-based organizational structure. Specifically, data teams can create individual spaces for domains to manage their own data products in isolation, independent of other domains.
Unified governance: Data teams can use Dremio as a single layer to implement common business logic and access policies for their environment, which simplifies governance and ensures interoperability between domains. This encompasses user and role management (including data access and masking policies), and even applies to non-SQL workloads operating against Dremio (e.g., a data scientist using Python or Spark to access Dremio via Arrow Flight).
Developing and managing data products
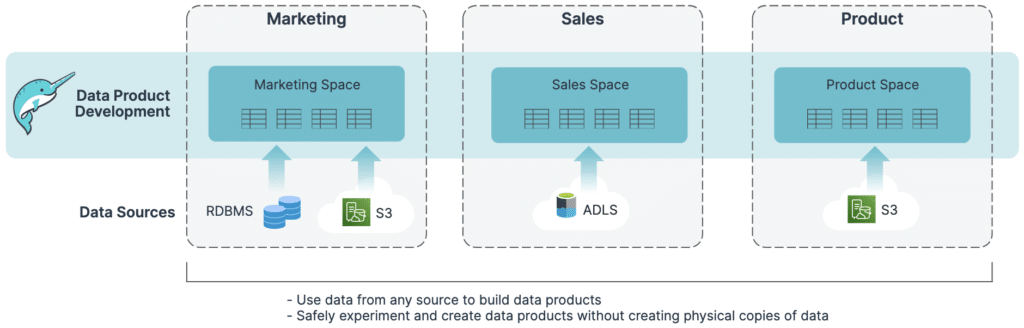
Self-service experience: Once data teams have built a well-governed foundation, technical and non-technical users in a domain can use their space to create, manage, and share data products, without needing help from data engineering.
Any data, anywhere: Domain teams can create data products using data that lives anywhere — in object storage (S3, ADLS, GCS, etc.) and relational databases, both on the public cloud as well as on-premises.
SQL for everyone: Domain teams can use SQL or leverage Dremio’s visual interface to safely experiment with data and develop data products, without making physical copies of data. Query acceleration enables sub-second response times for all analytics workloads, even on massive datasets, while capabilities such as DML and dbt integration make data transformations easy.
Manage data products like code: Data engineers can use Dremio Arctic, powered by the open source Nessie project, to bring a full software development lifecycle experience to data products, by creating isolated dev/test/prod branches for data products and adding versioning to data products. With the ability to safely transform data in isolation, surface all QA'd updates to datasets at the same time, and instantly rollback changes if an issue is found, data engineers within a domain can ensure their data products can meet stringent availability, quality, and staleness SLAs that may be enforced as part of the data mesh. Data engineers can also integrate these processes with CI/CD pipelines and other programmatic workflows (e.g., Apache Airflow).
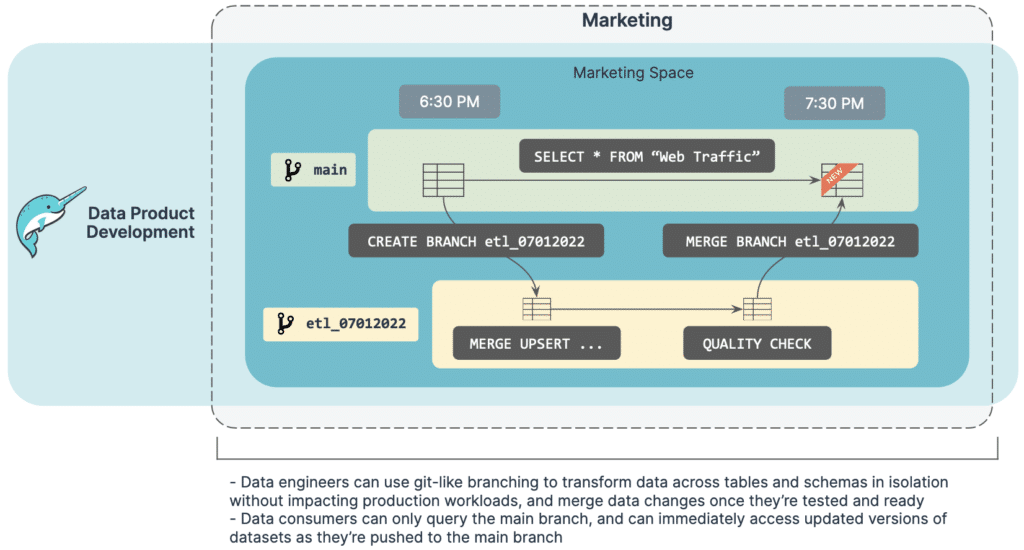
Sharing data products
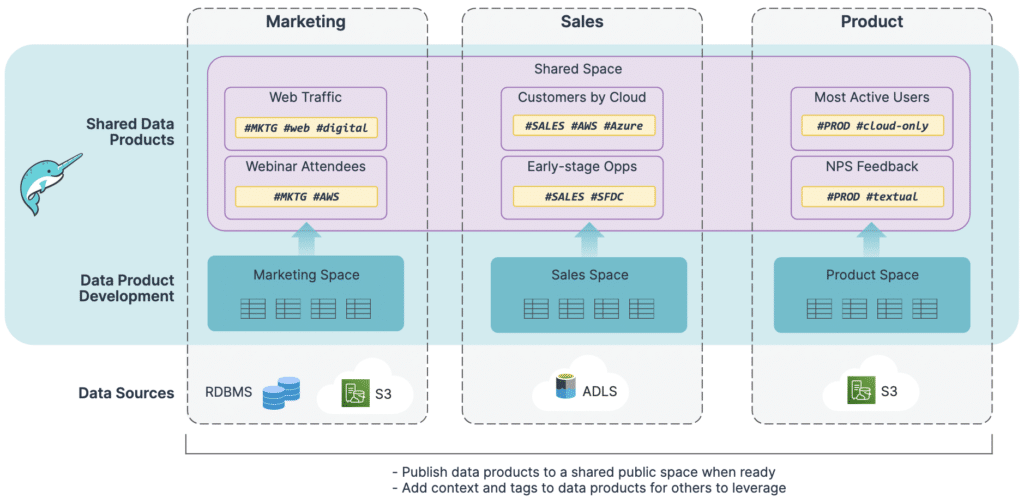
Retain business context: Domain teams can use Dremio’s built-in governance features to add context and tags to data products for others to leverage. In addition, data consumers can trace which datasets comprise each data product through built-in lineage graphs.
Share data with others: Once domains develop their data products, they can easily publish them for others to consume. Organizations can make data sharing simple and secure by defining user identities and roles in a central Identity Provider, such as Azure AD, Okta or Google.
Consuming data products
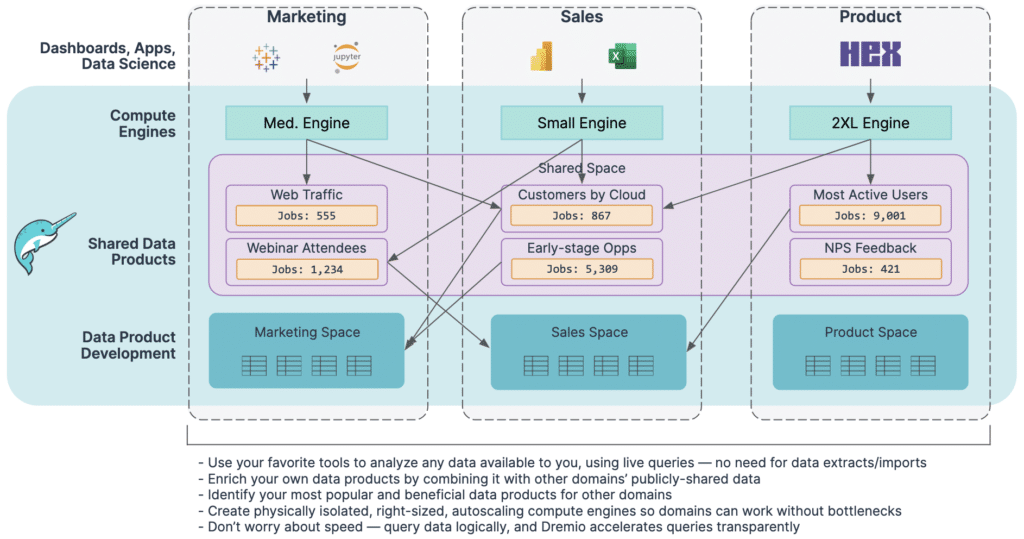
Any tool, any language: Data consumers can use their favorite tool to analyze any data available to them. Data analysts can use SQL via Dremio’s built-in SQL editor or any other SQL-based tool. Business users can visualize data using tools like Tableau, Power BI, and Hex, and power dashboards using live queries rather than stale, restrictive extracts. And, data scientists can use Python and Spark to access data with high throughput, thanks to Dremio’s native Arrow Flight interface. Many client tools are also implementing their own Arrow Flight SQL interface, which makes the benefits of Arrow Flight's high-speed data transfer more accessible than ever. An open source, industry-standard way to move data between systems is especially important in a data mesh, as each domain is free to choose their preferred tools to consume data.
Enrich data products with shared data: Domains can enrich their data products by joining other domains’ shared data with their own data, without needing help from data engineers, and without making physical copies of data.
Transparent performance: Dremio makes life easy for analysts. Unlike with other platforms, analysts don’t have to know about specific indexes, aggregate tables, materialized views, cubes, or extracts to query in order to make their reports run quickly. Analysts can query data logically (using live query mode), and Dremio accelerates the queries behind the scenes to ensure optimal performance.
Compute isolation: Organizations can create dedicated engines (i.e., compute clusters) for each domain, so when users from an individual domain use Dremio to run queries, their workloads are never bottlenecked by other domains’ workloads. All queries on a specific engine are logged for auditability, and domains can use their own billing methods for flexibility.
Build your feedback flywheel: To close the feedback loop between data producers and consumers, Dremio makes it easy for domains to identify their most frequently-used data products, and better understand how other domains use their data products.
Simple management
Zero management required: Dremio’s fully-managed lakehouse platform makes it easy to implement all of the scenarios above, while eliminating the need to worry about infrastructure, software upgrades, system uptime, and scaling. In addition, Dremio automatically optimizes data in the background so that data teams and domains don’t have to worry about how the data is stored (too many small files, wrong partitioning, etc.). The data remains in open formats such as Apache Iceberg, so any engine (Dremio, AWS Athena, AWS EMR, Snowflake, etc.) benefits from Dremio’s automatic data optimization.
Simple data model: Dremio’s semantic layer makes it easy for data teams to manage and expose a more logical view of data for end users, and eliminates the need for precomputed, pre-aggregated/joined physical tables that users have to navigate through.
Batteries included: You don’t need to configure various system parameters or connect external catalogs if you want to use Dremio to implement a data mesh. Everything we’ve discussed above is enabled by default!
Where the open lakehouse comes in
Until now, we’ve discussed how Dremio makes it easy for organizations to implement and operationalize their data mesh. However, one open question is where the data that comprises these data products should live.
Recall the data mesh gives domains the flexibility to choose their preferred technologies to support their use cases. And, as discussed above, domains can use Dremio to build their data products using data that lives anywhere, including object storage and relational databases.
That being said, we believe that an open lakehouse, supported by cloud object storage (Amazon S3, ADLS, GCS), is an ideal architecture for domains to support their analytics use cases. Specifically:
- A lakehouse enables domains to use all of their preferred tools directly on data as it lives in object storage. Domains can use Dremio to connect to one or many object storage sources to support mission-critical BI, and use engines like Spark for ETL/batch processing on that same data.
- A lakehouse eliminates the need for data teams to build and maintain convoluted pipelines into data warehouses.
- When a new engine emerges, it’s easy to use that new engine directly on lakehouse data, because it’s stored in open formats on object storage.
Dremio makes it easy for domains to build and operate their lakehouse architectures:
- Dremio Sonar is a lakehouse query engine that enables data warehouse functionality and performance directly on the lakehouse, with full SQL DML support. In addition, Sonar enables teams to blend data from multiple external sources to create their data products.
- Dremio Arctic is a lakehouse catalog and optimization service that automates all file maintenance operations (e.g., compaction, indexing) for the lakehouse, and eliminates the need for data engineers to worry about tedious file maintenance operations.
How companies are using Dremio to implement their data mesh
Many companies have already gotten a head start in using Dremio as the foundation for their data mesh, and have shared their successes! Here are a couple of presentations you can check out from past Subsurface LIVE conferences:
We also highly recommend this upcoming webinar, scheduled for Thursday, June 9th, 2022 at 11 AM CET:
And of course, we have to share the love from our friends at Renaissance Reinsurance:

What’s next?
In this blog, we’ve walked through how organizations can use an open lakehouse architecture to implement a data mesh supporting a broad range of analytical use cases.
Specifically:
- How organizations can use Dremio’s easy and open data lakehouse platform to implement a data mesh to support analytical workloads
- Why an open lakehouse, supported by cloud object storage, is an ideal architecture for domains to support their analytics use cases as part of their organization’s data mesh
If you’d like to explore an open lakehouse architecture and start implementing your data mesh with Dremio, you can get started on your own for free today! We’d also love to help you along the way, and our data mesh experts will be happy to help you architect your data mesh. Feel free to reach out here to start the conversation.
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->