8 minute read · June 20, 2024
The Unified Lakehouse: Performant Data Access

· Senior Tech Evangelist, Dremio


Data Mesh, Data Lakehouse, Data Fabric, Data Virtualization—there are many buzzwords describing ways to build your data platform. Regardless of the terminology, everyone seeks the same core features in their data platform:
- The ability to govern data in compliance with internal and external regulations.
- The ability to access all data seamlessly.
- The ability to query data and receive quick answers.
- The assurance that the data is up-to-date.
- Achieving all the above at minimal cost.
Many of these "Data X" concepts address different aspects of these goals. However, when you integrate solutions that cover all these needs, you often converge on a combination of a data lakehouse (treating your data lake as both a data warehouse and the primary data source) and data virtualization (connecting to multiple data sources and interacting with them through a unified interface). We’ll refer to this combination as the "Unified Apache Iceberg Lakehouse." This approach typically involves:
- Storing most of your analytics data in Apache Iceberg tables within your data lake.
- Enriching this data through data virtualization, drawing from a diverse array of databases and data warehouses.
- Using Dremio as the unified access and governance layer for all this data.
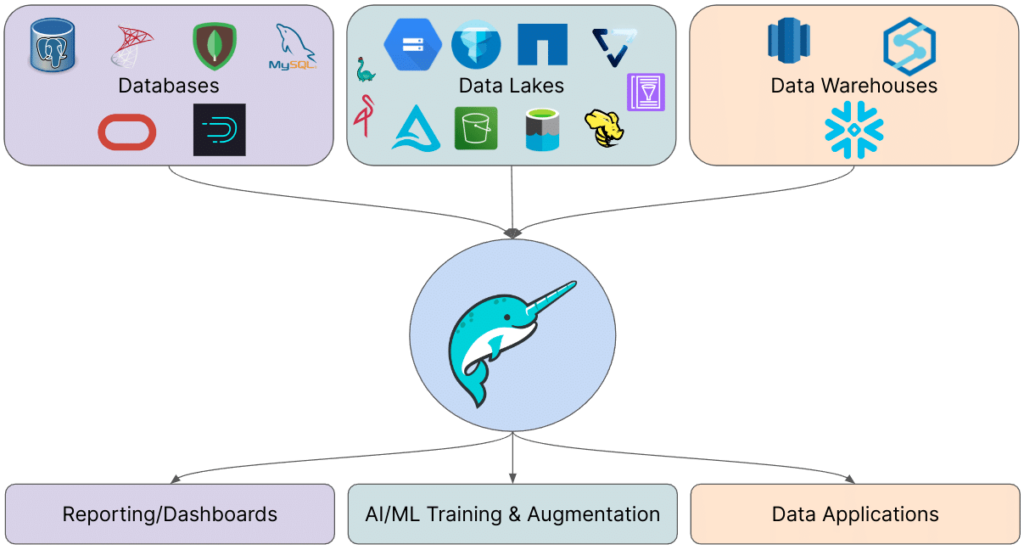
This series of blogs aims to explore the various benefits of this architecture, providing a deep dive into the value of this approach.
Getting the best Lakehouse Price/Performance
This blog will focus on the price-performance story of the Unified Apache Iceberg Lakehouse with Dremio.
Let's start by defining what is meant by "price/performance." The idea is that Dremio handles any query with high performance and does so at a lower cost. Even if faster queries aren't always necessary, Dremio maintains the same speed at a lower infrastructure footprint, resulting in lower costs than other query engines. For a detailed look at performance benchmarks, I recommend watching the keynote from the 2024 Subsurface Lakehouse Conference by Dremio CEO Sendur Sellakumar, which highlights Dremio's industry-leading price/performance.
- Apache Arrow: Dremio processes all data in Apache Arrow. When data is loaded into memory from any source, it is loaded into Apache Arrow objects, which enable high-performance processing. Additionally, the Apache Arrow Flight data transfer protocol minimizes serialization/deserialization costs as data is shuffled across nodes in a Dremio cluster instead of using JDBC/ODBC connections. With Apache Arrow and its optimizations, Dremio's raw performance is industry-leading.
- Columnar Cloud Cache (C3): Dremio's C3 cloud cache boosts performance when accessing data on object storage by caching frequently accessed data on the NVMe memory of nodes in the Dremio cluster. This not only accelerates queries but also reduces data access and egress costs, as fewer requests need to be sent to cloud storage providers thanks to the cache.
- Reflections: Dremio's data reflections provide an extra acceleration layer for raw and aggregate query workloads, eliminating the need for traditional materialized views and cubes. Reflections create an Apache Iceberg-based representation of accelerated datasets on your data lake and substitute them when the original or related datasets are queried. This design makes it easier for analysts to benefit from acceleration, reducing the chances of accidentally running longer, more expensive queries due to juggling namespaces. Additionally, since this acceleration exists within the Dremio layer, any client BI or reporting tool can take advantage of it without needing to recreate the same acceleration in multiple BI tools using tool-native extracts.
- Auto Scaling: Dremio's auto-scaling features provide cost controls on compute by allowing you to determine the size and concurrency of a cluster and set criteria for how long a cluster should be idle before it is turned off. You can also route queries to specific clusters based on set criteria to ensure low-priority queries don't use more expensive infrastructure. Dremio simplifies managing workflows for cost and performance optimization.
- Query Planner: Dremio's query planner optimizes your queries under the hood, fine-tuning them for ideal performance and cost efficiency.
By leveraging these technologies, Dremio ensures that the Unified Apache Iceberg Lakehouse provides top-notch performance while keeping costs low. This combination allows organizations to unify their data, minimize data movements, and achieve high performance without breaking the bank.
The Unified Apache Iceberg Lakehouse powered by Dremio offers a compelling price-performance story. By integrating Apache Arrow, Columnar Cloud Cache, data reflections, auto-scaling, and an intelligent query planner, Dremio delivers fast, cost-effective data analytics. This architecture not only supports efficient governance, seamless data access, and up-to-date data but also ensures that these benefits are achieved at a minimal cost, making it an ideal choice for modern data platforms.
Want to begin the transition to a Unified Apache Iceberg Lakehouse? Contact Us
Here are Some Exercises for you to See Dremio’s Features at Work on Your Laptop
- Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
- From SQLServer -> Apache Iceberg -> BI Dashboard
- From MongoDB -> Apache Iceberg -> BI Dashboard
- From Postgres -> Apache Iceberg -> BI Dashboard
- From MySQL -> Apache Iceberg -> BI Dashboard
- From Elasticsearch -> Apache Iceberg -> BI Dashboard
- From Kafka -> Apache Iceberg -> Dremio
Explore Dremio University to learn more about Data Lakehouses and Apache Iceberg and the associated Enterprise Use Cases. You can even learn how to deploy Dremio via Docker and explore these technologies hands-on.
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Dremio Blog: Product Insights,
Learn More ->

BLOG
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.
Dremio Blog: Product Insights,
Learn More ->

BLOG
Kubernetes Autoscaling in Dremio 24.3
Dremio Blog: Product Insights,
Learn More ->