8 minute read · June 18, 2024
The Unified Apache Iceberg Lakehouse: Unified Analytics
· Senior Tech Evangelist, Dremio

Data Mesh, Data Lakehouse, Data Fabric, Data Virtualization—there are many buzzwords describing ways to build your data platform. Regardless of the terminology, everyone seeks the same core features in their data platform:
- The ability to govern data in compliance with internal and external regulations.
- The ability to access all data seamlessly.
- The ability to query data and receive quick answers.
- The assurance that the data is up-to-date.
- Achieving all the above at minimal cost.
Many of these "Data X" concepts address different aspects of these goals. However, when you integrate solutions that cover all these needs, you often converge on a combination of a data lakehouse (treating your data lake as both a data warehouse and the primary data source) and data virtualization (connecting to multiple data sources and interacting with them through a unified interface). We’ll refer to this combination as the "Unified Apache Iceberg Lakehouse." This approach typically involves:
- Storing most of your analytics data in Apache Iceberg tables within your data lake.
- Enriching this data through data virtualization, drawing from a diverse array of databases and data warehouses.
- Using Dremio as the unified access and governance layer for all this data.
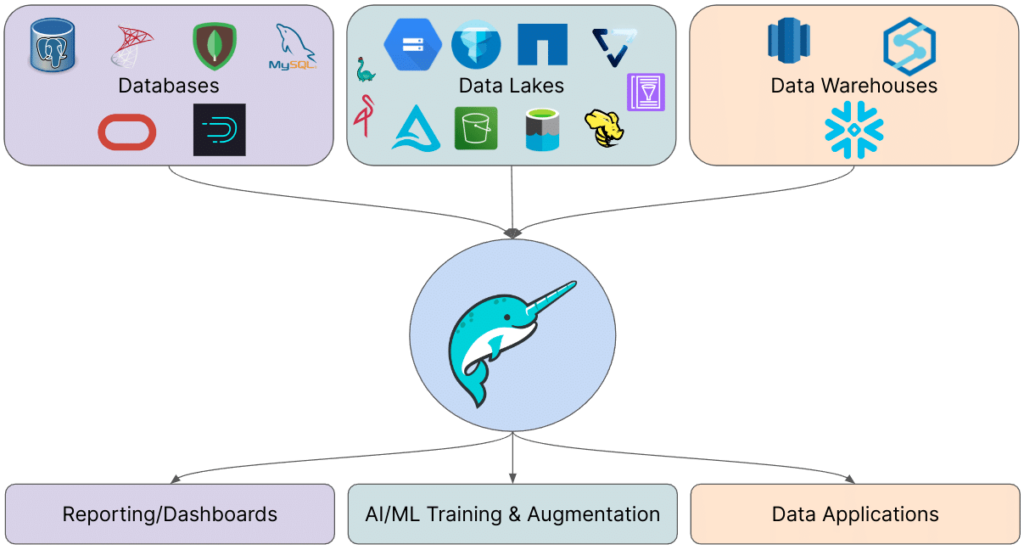
This series of blogs aims to explore the various benefits of this architecture, providing a deep dive into the value of this approach.
Unified Analytics for the Unified Lakehouse
This particular blog will focus on the unified analytics aspect of the story, highlighting how Dremio can connect to a wide variety of data sources, including:
- Databases: Postgres, Oracle, Apache Druid, MySQL, SQLServer, MongoDB, ElasticSearch, and more.
- Data Warehouses: Snowflake, Redshift, Synapse, and more.
- Data Lakes: Both cloud-based (AWS, GCP, Azure) and on-premises (Vast Data, NetApp, Hadoop, MinIO).
The Benefits of Comprehensive Connectivity
By leveraging Dremio's ability to connect to such a diverse array of data sources, you can significantly reduce the need to move data around. This reduction in data movement has several key benefits:
- Efficient Business Metrics Creation: With Dremio, you can create business metrics for reporting and dashboards directly from your data sources. This minimizes the time and effort spent on data ETL (Extract, Transform, Load) processes, allowing you to generate insights more quickly and efficiently.
- Accelerated AI Model Training: Feeding data into AI model training becomes faster and more streamlined. Less data movement means you can rapidly access and use data from various sources, leading to quicker iterations and more accurate models.
- In-Place Data Enrichment: Dremio enables in-place data enrichment, making it easier to integrate data from data marketplaces like Snowflake and AWS. This ability to enhance datasets on the fly without extensive data transfers is a game-changer for maintaining data freshness and accuracy.
Performance and Speed with Dremio
Dremio doesn't just connect all these data sources; it does so with exceptional speed and efficiency. Thanks to its Apache Arrow processing engine, Dremio delivers blazing-fast query performance. Key features that contribute to this performance include:
- Apache Arrow Processing: This high-performance, columnar in-memory format allows for efficient data processing and analytics, significantly boosting query performance.
- Columnar Cloud Cache (C3): This feature enables rapid access to frequently used data by caching the data on NVME memory on Dremio nodes, reducing query times and enhancing overall performance.
- Reflections Acceleration: Dremio's Reflections feature eliminates the need for materialized views and cubes of your data, further accelerating query performance by pre-computing and storing intermediate results in an intelligently used Apache Iceberg representation.
These features collectively offer industry-leading raw performance, ensuring that your analytics tasks are completed swiftly and efficiently. Moreover, Dremio provides room for further acceleration, making it an ideal choice for organizations looking to optimize their data analytics workflows.
Conclusion
The Unified Apache Iceberg Lakehouse, powered by Dremio, offers a compelling solution for unified analytics. By connecting to a wide range of data sources and minimizing data movement, you can achieve faster, more efficient analytics, improve AI model training, and enhance data enrichment processes. Dremio's advanced processing capabilities and performance features make it a standout choice for any organization looking to unify and accelerate their data analytics platform.
In this series, we will continue to explore the various benefits of this architecture, providing deeper insights into how the Unified Apache Iceberg Lakehouse can transform your data platform strategy.
Want to begin the transition to a Unified Apache Iceberg Lakehouse? Contact Us
Here are Some Exercises for you to See Dremio’s Features at Work on Your Laptop
- Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
- From SQLServer -> Apache Iceberg -> BI Dashboard
- From MongoDB -> Apache Iceberg -> BI Dashboard
- From Postgres -> Apache Iceberg -> BI Dashboard
- From MySQL -> Apache Iceberg -> BI Dashboard
- From Elasticsearch -> Apache Iceberg -> BI Dashboard
- From Kafka -> Apache Iceberg -> Dremio
Explore Dremio University to learn more about Data Lakehouses and Apache Iceberg and the associated Enterprise Use Cases. You can even learn how to deploy Dremio via Docker and explore these technologies hands-on.
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Dremio Blog: Product Insights,
Learn More ->

BLOG
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.
Dremio Blog: Product Insights,
Learn More ->

BLOG
Kubernetes Autoscaling in Dremio 24.3
Dremio Blog: Product Insights,
Learn More ->