This article has been revised and updated from its original version published in 2022 to reflect the latest Apache Iceberg developments, including V3 deletion vectors and optimistic concurrency improvements.
When you execute INSERT INTO orders VALUES (...) or MERGE INTO orders USING staged_orders ON ..., Apache Iceberg orchestrates a careful sequence of operations to maintain ACID guarantees on object storage. This guide walks through every step of the write path, from data file creation to atomic commit, and explains how Iceberg handles concurrent writes safely.
Understanding the write path is critical for designing performant ingestion pipelines. It explains why compaction matters, how Copy-on-Write and Merge-on-Read differ, and what happens when two writers conflict.
Types of Write Operations
Iceberg supports four types of write operations, each with different characteristics: For official documentation, refer to the Iceberg specification.
Operation
What It Does
Files Created
Complexity
INSERT / INSERT OVERWRITE
Adds new data or replaces partitions
New data files only
Simple
DELETE
Removes rows matching a condition
Delete files or rewritten data files
Medium
UPDATE
Modifies rows in place
Delete files + new data files (or rewritten files)
Medium
MERGE INTO
Upsert: insert/update/delete in one operation
Mix of all file types
Complex
The first type appends new files only. The last three involve row-level modifications, which trigger one of two strategies.
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
Step 1: Plan the Write
Before writing any files, the engine plans the operation:
Parse the SQL and determine which partitions will be affected
Read the current metadata to understand the schema, partition spec, sort order, and table properties
Choose the write mode: Copy-on-Write or Merge-on-Read (set via table properties write.delete.mode, write.update.mode, write.merge.mode)
For row-level operations: Identify which existing data files contain rows that match the condition
Write Mode Selection
The mode determines how row-level changes are applied:
Copy-on-Write (COW)
Reads affected data files entirely
Applies changes in memory
Writes completely new data files with the changes applied
Deletes the old files from the manifest
Best for: Read-heavy tables with infrequent updates
Merge-on-Read (MOR)
Does NOT rewrite existing data files
Writes small delete files (positional or equality) that mark rows as deleted
Writes new data files for inserted/updated rows
At read time, the engine merges data files with delete files
Best for: Write-heavy tables, streaming ingestion, frequent updates
V3 Deletion Vectors
Evolution of MOR: stores row deletion marks as bitmaps within the manifest, not separate files
Faster writes (no separate file) AND faster reads (bitmap lookup vs. file join)
The engine serializes rows into data files (typically Parquet) and uploads them to object storage.
Parquet File Construction
Each data file is written with:
Row groups of 64-128MB each
Column-level statistics (min/max, null count, distinct count) embedded in the Parquet footer
Encoding and compression (typically Snappy or ZSTD)
Page-level bloom filters (optional, for equality predicates)
File Size Targeting
The engine targets a configurable file size (default 512MB for most engines, configurable via write.target-file-size-bytes). This is important because:
Too-small files create metadata overhead and reduce read-path pruning effectiveness
Too-large files increase the blast radius of rewrites and slow down individual file reads
When small files accumulate from streaming ingestion, compaction consolidates them.
Sort Order
If the table has a defined sort order, the engine sorts data within each file by the specified columns. This creates tight min/max bounds that dramatically improve partition and file pruning. For multi-column filter patterns, Z-ordering interleaves sort dimensions.
Partitioned Writes
If the table is partitioned (e.g., month(order_date)), the engine evaluates the partition transform for each row and routes it to the appropriate partition. Each partition gets its own data file(s).
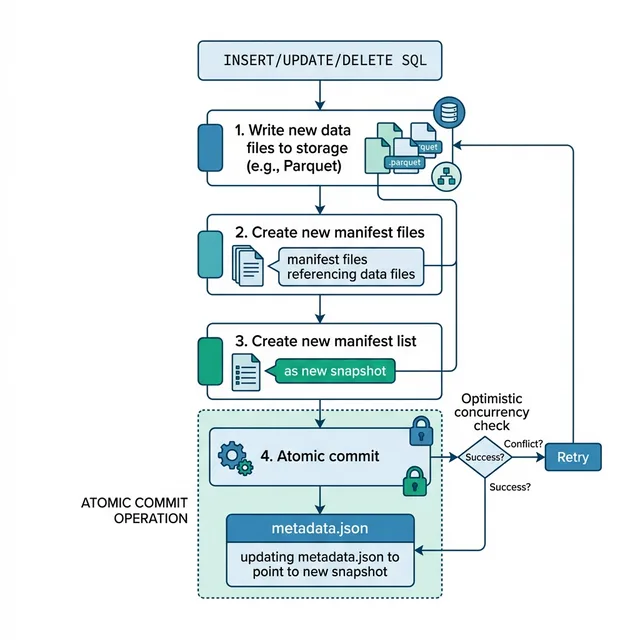
Step 3: Create New Manifest Files
After data files are written, the engine creates new manifest files (Avro format) that describe them:
Snapshot ID: Which snapshot this manifest was created for
Sequence number: Ordering for conflict resolution
Partition summaries: Aggregated partition bounds across all entries
Manifest Reuse
Iceberg reuses manifests from previous snapshots for files that haven't changed. If a write adds 5 new files to a table with 10,000 existing files, only the new files get a new manifest. The other 10,000 files are referenced through existing manifests. This is why Iceberg commits are O(number of changed files), not O(total files).
Step 4: Create a New Manifest List (Snapshot)
The engine writes a new manifest list (also Avro) that references all manifests, both new ones and reused ones from the previous snapshot:
Manifest List:
snapshot_id: 987654322
parent_snapshot_id: 987654321
manifests:
- manifest-001.avro (EXISTING, from previous snapshot)
- manifest-002.avro (EXISTING, from previous snapshot)
- manifest-new.avro (ADDED, for this commit)
This manifest list IS the new snapshot. It's a complete description of the table at this point in time, every data file and delete file. This immutability is what makes time travel and rollback possible.
Step 5: Atomic Commit via Optimistic Concurrency
This is the critical step that provides ACID guarantees. The engine must atomically update the metadata pointer from the old snapshot to the new one.
The Commit Protocol
Read the current metadata file version
Build the new metadata file referencing the new snapshot
Attempt an atomic swap:
Object storage: Atomic rename of the metadata file (v42.metadata.json → v43.metadata.json)
Catalog: Compare-and-swap API call (REST Catalog, Glue, Nessie)
If successful: Commit is done. Readers immediately see the new snapshot.
If failed (someone else committed first): Retry from step 1
Conflict Detection and Retry
When two writers commit concurrently, the second writer's atomic swap fails. Iceberg then:
Reads the other writer's new metadata
Checks for conflicts:
No conflict if the changes don't overlap (e.g., writing to different partitions)
Conflict if both writers modified the same files
If no conflict, rebases the changes and retries the commit
If conflict, fails the operation
This is optimistic concurrency, it assumes conflicts are rare and only checks at commit time. For independent partitions (e.g., two ETL jobs writing to different dates), both succeed without coordination.
Multi-Table Transactions with Nessie
Project Nessie extends this model to support atomic commits across multiple Iceberg tables. A single Git-like commit can create a new snapshot for several tables simultaneously, essential for maintaining referential integrity in star schemas.
Write Path by Operation Type
INSERT
The simplest path, writes new data files, new manifest, new manifest list, atomic commit. No reading of existing files required.
DELETE (Merge-on-Read)
Identify data files that might contain matching rows (using manifest statistics)
Read those files and find the matching row positions
Commit with both existing data files and new delete files
DELETE (Copy-on-Write)
Identify and read affected data files
Filter out deleted rows
Write new data files WITHOUT the deleted rows
Commit: new manifest replaces old file entries with new file entries
MERGE INTO
The most complex operation, combines DELETE + INSERT + UPDATE in a single transaction:
Join the source data (staged_orders) with the target (orders) on the match condition
For matched rows: apply UPDATE or DELETE
For unmatched rows: apply INSERT
Write all resulting files (data + delete files)
Single atomic commit for the entire operation
Performance Tuning the Write Path
Target File Size
Set write.target-file-size-bytes to 256MB-512MB for batch workloads. For streaming, smaller initial files are acceptable if you run compaction regularly.
Choose the Right Write Mode
Workload
Recommended Mode
Nightly batch with dashboards
Copy-on-Write
Streaming ingestion with frequent queries
Merge-on-Read + scheduled compaction
GDPR deletion requests
MOR for immediate compliance, COW compaction for permanent erasure
CDC from databases
MOR with Deletion Vectors (V3)
Minimize Small Files
Each commit creates at least one new file. High-frequency micro-batch commits (every few seconds) can create thousands of small files per hour. Mitigate by:
Batching writes into larger intervals
Using Flink with checkpoint intervals of 1-5 minutes
Running automated compaction
Dremio Write Optimizations
Dremio's write path includes:
Automatic sort by partition + sort order
Automatic compaction for managed tables
Concurrent write support with cross-engine coordination through the catalog
The difference is most visible during failures. In a traditional data lake, a failed write mid-execution leaves partial files on storage, corrupting the table until someone manually cleans up. In Iceberg, the atomic commit never fires, so the table remains in its previous consistent state. No cleanup required.
Common Write Path Anti-Patterns
Anti-Pattern 1: Frequent Micro-Commits
Committing every few seconds creates thousands of small files and snapshots. Each commit has fixed overhead (manifest creation, atomic swap), so amortizing that cost over larger batches is always more efficient.
Fix: Batch writes into larger intervals. For Flink, set checkpoint intervals to 1-5 minutes. For Spark Structured Streaming, use trigger intervals of at least 30 seconds.
Anti-Pattern 2: Using COW for High-Update Tables
Copy-on-Write rewrites entire data files for every UPDATE or DELETE. On a table with frequent row-level changes (CDC ingestion, GDPR deletions), this means rewriting gigabytes of data for a few changed rows.
Fix: Switch to Merge-on-Read or V3 deletion vectors. Run periodic compaction to resolve accumulated delete files.
Fix: Define a sort order on the table and ensure it's applied during writes or compaction.
Anti-Pattern 4: Skipping Partition Strategy
Writing to an unpartitioned table forces the engine to manage all data in a single partition group. This creates massive manifest files, prevents partition pruning, and makes every query a full table scan at the manifest level.
Fix: Add hidden partitions based on your most common query filter columns.
Failure Recovery and Idempotency
What Happens When a Write Fails?
Engine crashes during data file writes: Partially written files become orphans on storage. The table is unaffected because no commit happened. Clean up with remove_orphan_files.
Engine crashes after data files written, before commit: Same as above. Data files exist but no manifest references them. Table remains consistent.
Commit fails due to conflict: The engine retries the commit with a rebased metadata file. If the conflict is unresolvable (same files modified by both writers), the operation fails and the user must retry.
Object storage outage during commit: The atomic swap fails, and the table stays at the previous snapshot. Data files become orphans.
In all cases, the table never enters an inconsistent state. This is fundamentally different from traditional data lakes where any of these failures can corrupt the table.
Frequently Asked Questions
What happens when two writers try to commit at the same time?
Iceberg uses optimistic concurrency control. Both writers prepare their changes independently, then attempt to commit by updating the metadata pointer. The first writer succeeds. The second writer detects a conflict, re-reads the updated metadata, validates whether its changes are still compatible (no overlapping files modified), and retries if possible. If the changes conflict, the second writer raises an error.
Does every write create a new snapshot?
Yes. Every commit (insert, delete, update, compaction) produces a new snapshot with a unique snapshot ID. This is what enables time travel and rollback. Over time, snapshots accumulate and should be periodically expired to reclaim metadata space.
How does Iceberg ensure data consistency during writes?
Consistency comes from atomic metadata pointer swaps. The catalog maintains a single pointer to the current metadata file. A writer creates all new data files and metadata first, then atomically updates this pointer to reference the new metadata. If the write fails partway through, the pointer is never updated, so readers never see partial data. Orphaned files from failed writes are cleaned up later.
Apache Iceberg is an open data lakehouse table format that provides your data lake with critical features like time travel, ACID transaction, partition evolution, schema evolution, and more. You can read this article or watch this video to learn more about the architecture of Apache Iceberg. In this article, we’d like to explain how write queries work for Apache Iceberg.
In order to understand how write queries work we first need to understand the metadata structure of Apache Iceberg, and then examine step by step how that structure is used by query engines to plan and execute the query.
Apache Iceberg 101
Apache Iceberg has a tiered metadata structure and it’s key to how Iceberg provides high-speed queries for both reads and writes. Let’s summarize the structure of Apache Iceberg to see how this works. If you are already familiar with Iceberg’s architecture then feel free to skip ahead to the section titled “How a Query Engine Processes the Query.”
Data Layer
Starting from the bottom of the diagram, the data layer holds the actual data in the table. It’s made up of two types of files:
Data files – store the data in file formats such as Parquet or ORC.
Delete files – track records that still exist in the data files, but that should be considered as deleted.
Metadata Layer
Apache Iceberg uses three tiers of metadata files which cover three different scopes.
Manifest files– A subset of the snapshot. These files track the individual files in the data layer in that subset along with metadata for further pruning.
Manifest lists– Defines a snapshot of the table and lists all the manifest files that make up that snapshot with metadata on those manifest files for pruning.
Metadata files– Defines the table, and tracks manifest lists, current and previous snapshots, schemas, and partition schemes.
The Catalog
Tracks a reference/pointer to the current metadata file. This is usually some store that can provide some transactional guarantees like a relational database (Postgres, etc.) or metastore (Hive, Project Nessie, Glue).
How a Query Engine Processes the Query
So let’s run an INSERT, DELETE, and MERGE INTO against a table called orders to see the behavior.
Running an Insert Query
INSERT INTO orders VALUES (...);
1. Sending the query to the engine
The query is submitted to the query engine that parses the query. The engine now needs the table data to begin planning the query.
2. Checking the catalog and planning
The engine first reaches out to the catalog to find the current metadata file’s path and reads that metadata file. Even though it’s just appending data to the table, it does this to determine two things:
The table's schema to make sure the data it’s going to write fits that schema, as well as which fields can versus can’t have null values.
The partitioning of the table to determine how to organize the data to be written.
3. Writing the data files
Since no existing data files will be affected because it’s an INSERT, we can begin writing new data files. At this point, all new records will be written into files based on the partitioning scheme of the table. If the table has a configured sort order and the engine writing the data supports it, then the records will be sorted prior to writing the records to data files.
4. Writing the metadata files
Now that data files have been written, we will group these files into manifest files. For each manifest file, we’ll include the file paths to the data files it tracks and statistics about each data file, such as minimum and maximum values for each column in the data file. We’ll then write these manifest files out to the data lake.
Then, we will include all new or existing manifests associated with this snapshot in a new manifest list. In the manifest list, we’ll include the file paths to the manifest files and statistics about the write operation, such as how many data files it added, and information about the data referenced by the manifest files, such as the lower and upper bounds of their values for partition columns. We’ll then write this manifest list out to the data lake.
Finally, we will create a new metadata file to summarize the table as it stands based on the metadata file that was current before our INSERT, including the file path and details of the manifest list we just wrote as well as a reference to note that this manifest list is now the current manifest list/snapshot.
Now we just need to commit this to the catalog.
5. Committing the changes
The engine goes to the catalog again to ensure that no new snapshots appeared while the files were being written. This check prevents concurrent writers from overwriting each other’s changes. Writes will always be safe when done concurrently, as the writer that completes first gets committed and any other writes that conflict with the first writer’s changes will go back to step 3 or 4 and reattempt until successful or quit retrying and decide to fail.
Readers will always plan based on the current metadata file, so they won’t be affected by concurrent writes that have not yet committed.
Running a Delete Query
DELETE FROM orders
WHERE order_ts BETWEEN '2022-05-01 10:00:00' AND '2022-05-31 10:00:00';
1. Sending the query to the engine
The query is submitted to the query engine that parses the query, and the engine now needs the table data to begin planning the query.
2. Checking the catalog and planning
The engine first reaches out to the catalog to find the current metadata file. It does this to determine a few things:
The partitioning of the table to determine how to organize the data to be written.
The current sequence ID of the table and what its transaction’s sequence ID will be. It is assumed that no other writes that conflict with this INSERT will be complete before this job is done since Iceberg leverages optimistic concurrency control (assume everything is good till it isn’t).
If the table is set to copy-on-write, it will go through the following process:
Use the metadata to identify which files contain the data to be deleted.
Read these files in their entirety to determine what is deleted.
Write a new file to replace this file in the new snapshot, where this new file doesn’t have the data requested to be deleted.
If the table is set to merge-on-read, the process avoids rewriting data files to speed up the write, but the specific steps it will go through depends on the type of delete file the table is configured to use to track deleted records.
Position deletes
It will scan the metadata to determine which data files have records that will be deleted.
It will scan the data files to determine the positions of the deleted records.
It will write a delete file for the partition that lists which records by position are deleted from which files.
Equality deletes
It will not need to read any files, it will just skip to writing a delete file listing the values that specify which rows are to be deleted.
During reads, the reader will have to reconcile the delete file against all records in the partition which may be expensive.
Which type of delete file will be written based on the table settings? The original data file will still be used in the snapshot, and the engine will reconcile the delete file in future reads of that snapshot. Read this article on COW vs. MOR to understand what situations fit each strategy best.
4. Writing the metadata files
Now that data files/delete files have been written, we will group these files into manifest files. For each manifest file, we’ll include the file paths to the data files it tracks and statistics about each data file, such as minimum and maximum values for each column in the data file. We’ll then write these manifest files out to the data lake.
Then, we will include all new or existing manifests associated with this snapshot into a new manifest list. In the manifest list, we’ll include the file paths to the manifest files and statistics about the write operation, such as how many data files it added, and about the data referenced by the manifest files, such as the lower and upper bounds of their values for partition columns. We’ll then write this manifest list out to the data lake.
Finally, we will create a new metadata file to summarize the table as it stands based on the metadata file that was current before our DELETE, including the file path and details of the manifest list we just wrote as well as a reference to note that this manifest list is now the current manifest list/snapshot.
Now we just need to commit this to the catalog.
5. Committing the changes
The engine goes to the catalog again to ensure that no new snapshots appeared while the files were being written. This check prevents concurrent writers from overwriting each other’s changes. Writes will always be safe when done concurrently, as the writer that completes first gets committed and any other writes that conflict with the first writer’s changes will reattempt until successful or quit retrying and decide to fail.
Readers will always plan based on the current metadata file, so they won’t be affected by concurrent writes that have not yet committed.
Running an Upsert/Merge Query
MERGE INTO orders o
USING (SELECT * FROM orders_staging) s
ON o.id = s.id
WHEN MATCHED …
WHEN NOT MATCHED
1. Sending the query to the engine
The query is sent to the query engine that parses the query, so the engine now needs the table data for both the target and staging table to begin planning the query.
2. Checking the catalog and planning
The engine first reaches out to the catalog to find the current metadata file. It does this to determine a few things:
The table's schema to make sure the data it’s going to write fits that schema, as well as which fields can versus can’t have null values.
The partitioning of the table to determine how to organize the data to be written.
The current sequence ID of the table and what its transaction’s sequence ID will be. It is assumed that no other writes that conflict with this INSERT will be complete before this job is done since Iceberg leverages optimistic concurrency control (assume everything is good till it isn’t).
3. Writing the files
At this point, the engine will scan and load the relevant data from both the target and stage tables into memory and begin the matching and updating process. It will go through each row in the staging table to see if there is a match in the target table (via the id field matching, since that’s what we specified). What will be tracked in memory as it identifies matches will be based on the configured writing mode for table merges, copy-on-write or merge-on-read.
If copy-on-write, any data files where at least one record was updated will be rewritten to include updates and new records in the same partition. This means as updated files are read, the entire file must be saved to memory for the eventual writing of a new file.
If merge-on-read, delete files will be generated so the older versions of records will be ignored on future reads, then new data files will be written with only the newly updated or inserted records. Only the records to be updated will be tracked in memory which can be a lot less memory intensive over the entire transaction.
If there is a match, it will carry out any instructions inside the WHEN MATCHED clause typically to update certain fields.
If no match is found, it will carry out any instructions inside the WHEN NOT MATCHED clause, typically to insert the record from the stage table into the target table.
4. Writing the metadata files
Now that data files/delete files have been written, we will group these files into manifest files. For each manifest file, we’ll include the file paths to the data files it tracks and statistics about each data file, such as minimum and maximum values for each column in the data file. We’ll then write these manifest files out to the data lake.
Then, we will include all new or existing manifests associated with this snapshot into a new manifest list. In the manifest list, we’ll include the file paths to the manifest files and statistics about the write operation, such as how many data files it added, and information about the data referenced by the manifest files, such as the lower and upper bounds of their values for partition columns. We’ll then write this manifest list out to the data lake.
Finally, we will create a new metadata file to summarize the table as it stands based on the metadata file that was current before our MERGE, including the file path and details of the manifest list we just wrote as well as a reference to note that this manifest list is now the current manifest list/snapshot.
Now we just need to commit this to the catalog.
5. Committing the changes
The engine goes to the catalog again to ensure that no new snapshots appeared while the files were being written. This check prevents concurrent writers from overwriting each other’s changes. Writes will always be safe when done concurrently, as the writer that completes first gets committed and any other writes that conflict with the first writer’s changes will reattempt until successful or quit retrying and decide to fail.
Readers will always plan based on the current metadata file, so they won’t be affected by concurrent writes that have not yet committed.
Conclusion
Apache Iceberg using optimistic concurrency and snapshot isolation can ensure ACID guarantees so you can write data to a table without affecting concurrent readers or writers. If you are considering adopting Apache Iceberg into your data lakehouse, check out this tutorial on how to create Apache Iceberg tables using AWS Glue and Dremio.
Try Dremio Cloud free for 30 days
Deploy agentic analytics directly on Apache Iceberg data with no pipelines and no added overhead.
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Sep 22, 2023·Dremio Blog: Open Data Insights
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
We're always looking for ways to better handle and save money on our data. That's why the "data lakehouse" is becoming so popular. It offers a mix of the flexibility of data lakes and the ease of use and performance of data warehouses. The goal? Make data handling easier and cheaper. So, how do we […]
Oct 12, 2023·Product Insights from the Dremio Blog
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.