9 minute read · December 11, 2024
The Evolution of the Modern Data Team
· Technical Evangelist, Dremio

Business data needs are quickly evolving, and technology is adapting to keep pace. Cloud data warehouses now offer elastic storage and compute. Data lakes have evolved into lakehouses, combining lakes' flexibility with warehouses' reliability. Many organizations are utilizing a hybrid on-prem + cloud data storage strategy. Transformation tools have shifted from proprietary ETL platforms to open-source frameworks that enable software engineering practices on analytics. These technological advances are fundamentally changing how organizations work with data.
Yet many data teams continue to operate as they did in the heavily centralized, transactional data era. Exclusively using traditional Extract, Transform, Load (ETL) constrains organizations from realizing the full potential of modern data platforms. Forward-thinking organizations are embracing an Extract, Load, Transform (ELT) approach that better aligns with cloud-native architectures and provides more flexible, collaborative ways of working.
This shift requires more than just adopting new tools—it demands a complete rethinking of how data teams operate. Roles are advancing, responsibilities are shifting, and new positions like Analytics Engineer have emerged to bridge gaps between data engineering and analytics. Organizations must adapt their team structures, workflows, and skillsets to keep pace with these advances.
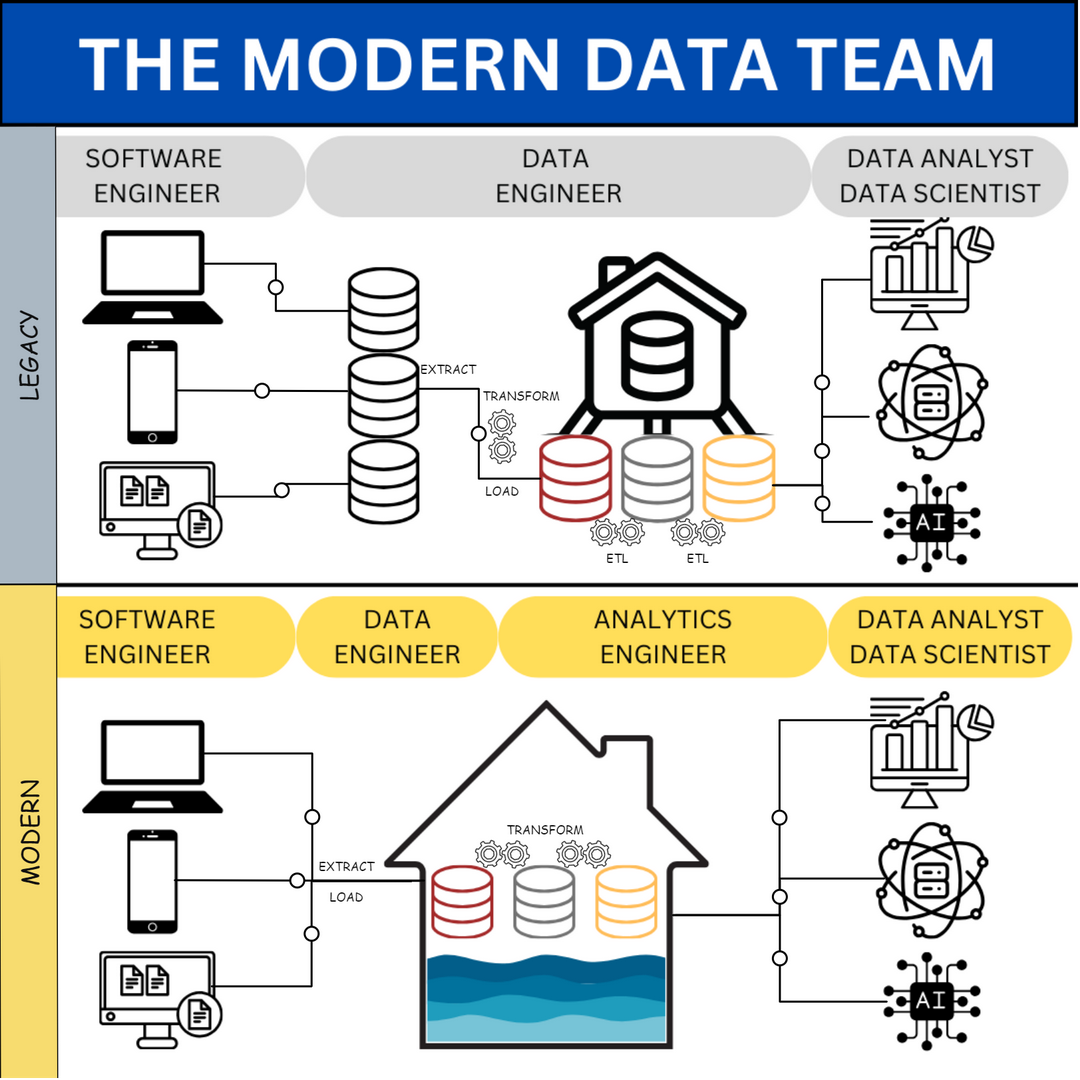
The Legacy ETL Approach
The ETL process was the backbone of data integration and preparation in traditional data warehousing. Data engineering teams operated as centralized gatekeepers of the data transformation process, handling everything from source system extraction to final data model delivery. This process began with extracting data from source systems, applying complex transformations using specialized ETL tools or custom scripts, and loading the cleaned, transformed data into the target data warehouse.
This workflow led to what many organizations called the "medallion architecture." Data existed in its raw form at the bronze layer. The silver layer contained, cleaned, and standardized data with business rules applied. Finally, the gold layer presented fully transformed, analysis-ready data models that business users and analysts could consume.
Challenges of Traditional ETL
While the traditional ETL approach provided control and consistency, it created several challenges. The centralized nature of ETL meant that data engineers became bottlenecks in the data delivery process. Business teams often waited weeks or months for new data models or changes to existing ones, as every transformation had to flow through the engineering team. This created friction between technical and business teams, with analysts frustrated by their inability to iterate on data models to meet changing business needs quickly.
The transformation-first approach meant raw data was often lost or inaccessible. If business requirements changed or errors were discovered in transformation logic, teams frequently needed to re-extract data from source systems, leading to inefficiencies and potential data loss. The rigid nature of traditional ETL tools also made adapting to changing data volumes and varieties difficult.
The Emergence of ELT
The rise of cloud computing and modern data lakes fundamentally changed this dynamic. Rather than transforming data before loading it into the warehouse, organizations began adopting an Extract, Load, Transform (ELT) approach. In this paradigm, raw data is loaded directly into the data lake, with transformations performed afterward.
Several technological advances enabled this shift. Modern transformation tools like dbt brought software engineering best practices to analytics, allowing for version-controlled, tested, and documented transformations. These advances made it possible to store raw data indefinitely and transform it on demand.
The Benefits of ELT
The modern ELT approach offers several fundamental advantages over legacy ETL. It preserves raw data in its original form, creating an immutable record that can be transformed differently depending on the specific purpose. Preserving raw data allows teams to reprocess historical data when business rules change without needing to re-extract from source systems.
ELT also improves processing efficiency by leveraging the powerful parallel processing capabilities of modern data storage systems. Transformations can be scaled up or down based on need, and multiple transformations can run simultaneously on the same dataset. This flexibility allows organizations to optimize their resource usage and control costs.
The separation of loading and transformation creates adaptability. Teams can modify transformation logic without touching data pipelines, experiment with different transformations safely, and support new use cases without additional data extraction. This separation of concerns leads to faster development cycles and more agile data teams.
New Roles and Responsibilities
The shift to ELT has led to a redistribution of responsibilities across the data team. Data engineers now focus primarily on the bronze layer, building and maintaining reliable data pipelines that bring data into the warehouse. They manage the data infrastructure, ensure data quality at ingestion, and maintain the platforms that enable self-service analytics.
Analytics engineers, a new role that has emerged with this transition, own the silver layer. They create and maintain core data models, implement business logic in tools like dbt, and ensure data quality in transformed datasets. Analytics engineers bridge the gap between data engineering and analytics to bring customized pipelines for specific business use cases.
Data analysts have evolved from pure consumers to active participants in the data modeling process. They often own the gold layer, creating final, business-specific data models and implementing metrics definitions. This ownership allows analysts to iterate quickly on business requirements and closely align with stakeholder needs.
Implementing Modern ELT with Dremio, Spark, and dbt
A powerful modern ELT architecture can be built using Dremio as a central lakehouse platform, Apache Spark for data movement, and dbt for transformations. This combination provides a robust foundation for scalable, flexible data processing.
Dremio serves as the central platform, providing a semantic layer over the data lake and enabling direct querying of data lake storage. Its data virtualization capabilities allow unified access to multiple data sources while minimizing data movement and copying. This centralized access point simplifies governance and ensures consistent metric definitions across the organization.
Apache Spark handles the extract and load portions of the ELT pipeline, providing powerful capabilities for parallel processing of source systems and optimized writes to data lake storage. Spark's support for various data formats and built-in error handling make it ideal for reliable data movement at scale.
dbt completes the architecture by providing a transformation layer that works directly with data in the lakehouse. It brings software engineering practices to analytics, enabling version-controlled, modular transformations with automated testing and documentation. Combining SQL-first transformations and clear dependency management makes it easier for teams to collaborate on data transformations.
Conclusion
The evolution from ETL to ELT represents more than a technical shift—it's a fundamental change in how organizations work with data. By embracing modern tools like Dremio, Spark, and dbt, organizations can build more flexible, efficient, and collaborative data environments. Success in this new paradigm requires understanding how these tools complement each other and how to leverage their strengths effectively.
The key to successful implementation is embracing the technical and organizational changes required. Teams must adapt to new roles and responsibilities while learning to leverage modern tools effectively. Organizations that successfully navigate this transition can create data environments that are both powerful and adaptable, capable of meeting current needs while being prepared for future challenges.
Sign up for AI Ready Data content
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Product Insights from the Dremio Blog,
Learn More ->

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->