21 minute read · October 28, 2024
Seamless Data Integration with Dremio: Joining Snowflake and HDFS/Hive On-Prem Data for a Unified Data Lakehouse
· Head of DevRel, Dremio

Organizations often have data distributed across cloud and on-premises environments, which poses significant integration challenges. Cloud-based platforms like Snowflake offer scalable, high-performance data warehousing capabilities, while on-premises systems like HDFS and Hive often store large volumes of legacy or sensitive data. Traditionally, analyzing data from these environments together would require complex data movement and transformation processes, leading to inefficiencies and higher costs.
Dremio provides a powerful solution for bridging this gap, allowing users to seamlessly join, analyze, and curate data from both Snowflake and HDFS/Hive on-prem. By connecting these environments directly in Dremio, organizations can create a unified data experience without replicating or transferring large datasets. This integration empowers data teams to build comprehensive views across diverse sources, simplifying analytics and accelerating query performance through Dremio’s unique reflection capabilities.
Benefits of Integrating Snowflake and HDFS/Hive with Dremio
Combining cloud-based and on-premises data sources in Dremio brings numerous advantages to data teams, from streamlining data access to enhancing analytics capabilities. Below are some of the key benefits of using Dremio to unify Snowflake and HDFS/Hive data.
Unified Data Access
Accessing data from Snowflake and HDFS/Hive in one environment allows users to eliminate data silos, reducing the need to duplicate data across systems. With Dremio, teams can perform comprehensive analyses by leveraging data from multiple environments in a single query. This enables more powerful reporting and insight generation. For instance, a team can join recent customer engagement data stored in Snowflake with historical purchase records in Hive, providing a holistic view of customer behavior.
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
Cost and Performance Optimization
Dremio’s powerful reflection capabilities help reduce the cost of querying across multiple environments by optimizing query performance without requiring extensive data movement. By storing optimized data representations, known as reflections, Dremio enables faster query execution and reduces the load on both Snowflake and HDFS/Hive sources.
Setting Up Snowflake and HDFS/Hive Connections in Dremio
Configuring your data sources in Dremio is the first step toward creating a seamless, cross-environment data experience. With Dremio, you can integrate Snowflake and HDFS/Hive with minimal setup, ensuring secure, optimized access to both cloud and on-prem data sources. This section outlines the steps for setting up each connection type.
Snowflake Connection Overview
To connect Snowflake to Dremio, follow these simple steps to configure access and authentication settings:
- Add Snowflake as a Source:
In Dremio’s interface, go to the Datasets page and click on the Add Source icon. Under the Databases section, choose Snowflake. - Configure General Options:
- Name: Enter a name for the Snowflake source, such as “Snowflake_CloudData” (names cannot contain special characters like “/”, “:”, “[“, or “]”).
- Host: Input the account URL in the format
https://<LOCATOR_ID>.snowflakecomputing.com. - Database and Schema: (Optional) Specify the default database and schema to use within Snowflake.
- Warehouse: (Optional) Set the warehouse to execute DML and query statements.
- Set Up Authentication:
- Choose between Login-password and Key-pair authentication.
- For login-password authentication, specify the username and choose a method to provide the password securely, whether through Dremio, an Azure Key Vault, AWS Secrets Manager, or HashiCorp Vault.
- For key-pair authentication, provide the necessary private key and passphrase, which can also be stored securely in one of the supported secrets managers.
- Define Advanced Options (Optional):
- Set idle connection and query timeout limits as needed to optimize resource utilization.
- Specify any required reflection refresh intervals and metadata handling configurations.
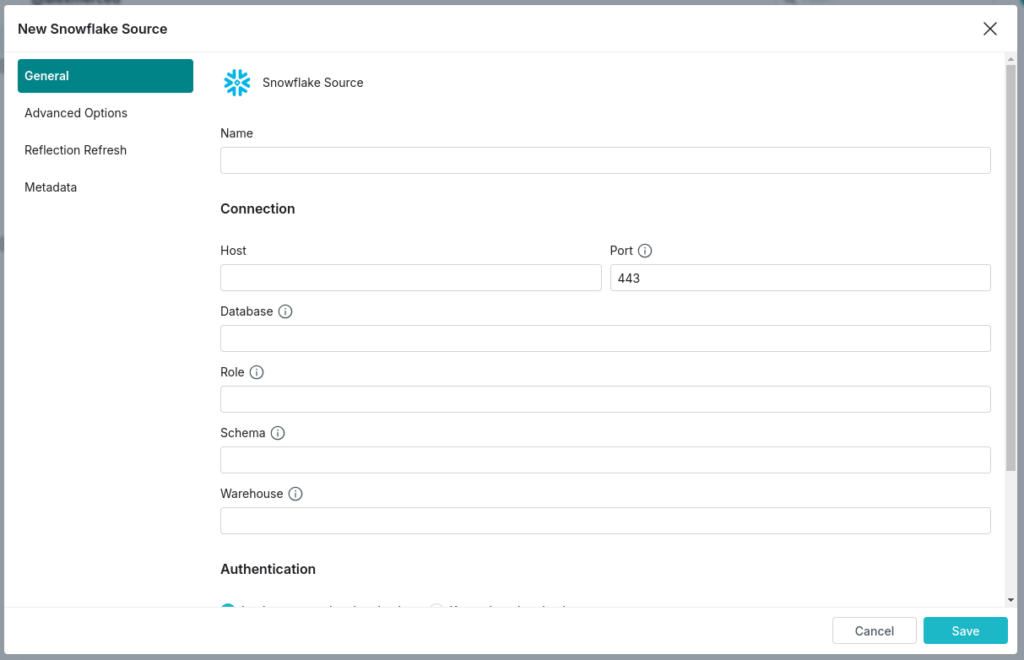
By following these steps, you can securely connect to Snowflake and begin integrating cloud-based data into your Dremio environment.
HDFS/Hive Connection Overview
Dremio’s support for HDFS/Hive allows you to incorporate on-prem data into the same environment, maintaining access to your legacy data while benefiting from Dremio’s accelerated query capabilities.
- Add HDFS or Hive as a Source:
In the Dremio interface, navigate to the Datasets page, select the Sources tab, and click on the Add Source icon. Under Object Storage, select HDFS, or under Metastores, select Hive. - Configure General Options for Hive or HDFS:
- Name: Provide a unique name for the source, like “Hive_OnPremData” or “HDFS_Storage” (again, avoid special characters).
- Connection: Enter the necessary connection parameters, such as the NameNode host and port for HDFS, or the Hive Metastore host and port for Hive.
- Enable Impersonation (Optional): Toggle impersonation to enable Dremio to query HDFS/Hive data on behalf of specific users, aligning with HDFS or Hive access controls.
- Advanced Options for Custom Configuration (Optional):
- Add specific connection properties if your setup requires custom configurations, such as multiple Hive metastores or Hadoop configuration files.
- Configure caching options, local reflection refresh policies, and dataset handling settings based on your performance and accessibility requirements.
- Set Metadata and Dataset Handling Options:
Customize metadata refresh intervals to keep source datasets up-to-date without overloading your environment with unnecessary metadata requests.
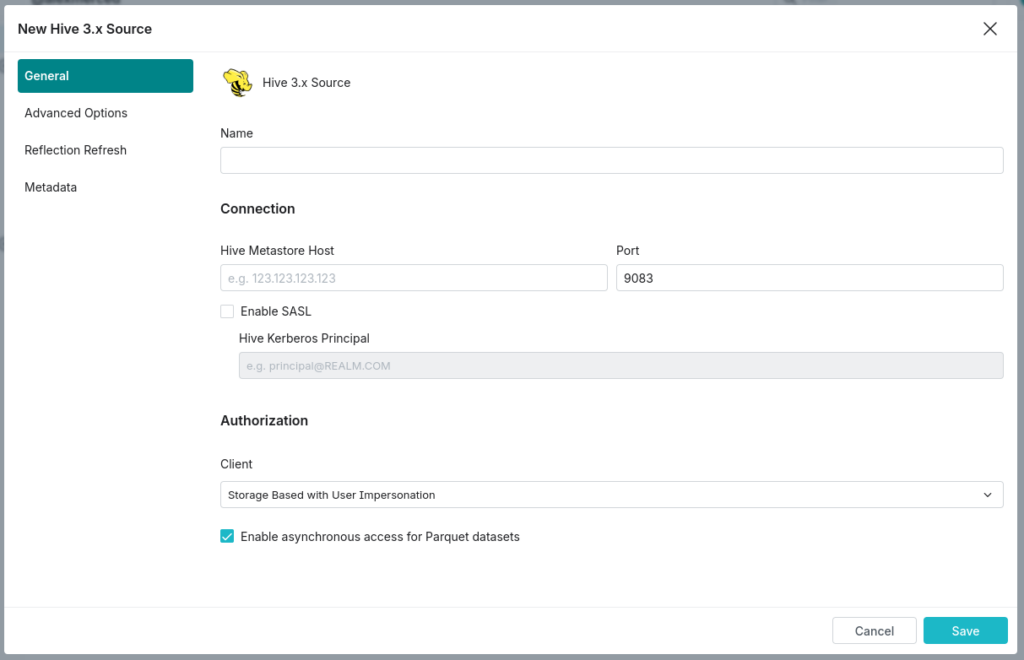
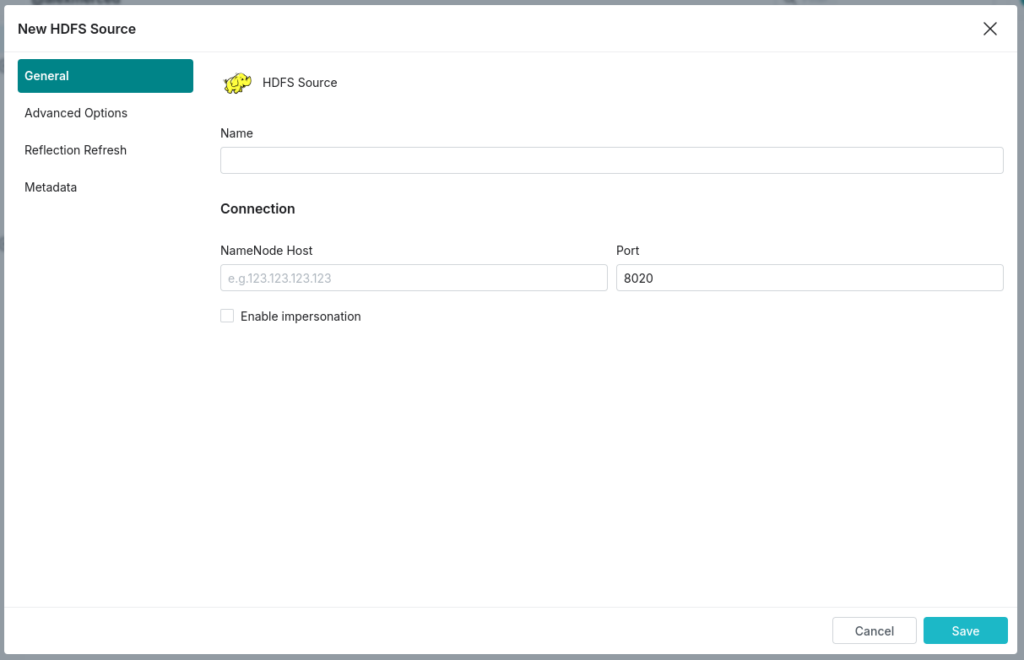
Following these steps will establish secure connections to your HDFS or Hive data sources, allowing you to query and integrate on-prem data into Dremio alongside your Snowflake datasets. With your sources configured, you're ready to create cross-environment views and take full advantage of Dremio’s powerful query acceleration.
Building and Curating Cross-Environment Views
Once Snowflake and HDFS/Hive sources are connected, Dremio allows you to create unified views that combine data across these environments. These virtual datasets streamline data analysis by centralizing access to relevant information, supporting agile data exploration, and providing a foundation for optimized reporting layers.
Virtual Datasets and Views in Dremio
Dremio’s virtual datasets allow you to build logical views across different data sources without physically moving data. These datasets are especially powerful when combining data from both Snowflake and HDFS/Hive, as they provide real-time access to on-premises and cloud data within a single query.
- Creating Cross-Environment Views:
To create a virtual dataset that joins Snowflake and HDFS/Hive data, simply use SQL queries within Dremio’s SQL editor. You can use standard SQL JOIN operations to combine tables from each source into a unified view. For example, you might create a view that joins recent transactional data from Snowflake with legacy customer data from Hive, allowing analysis of current and historical trends together. - View Flexibility:
Virtual datasets are flexible and can be easily modified to add or remove fields as data needs evolve. They also provide a layer of abstraction, so underlying data sources can be changed without affecting the analytical logic in downstream applications and reports.
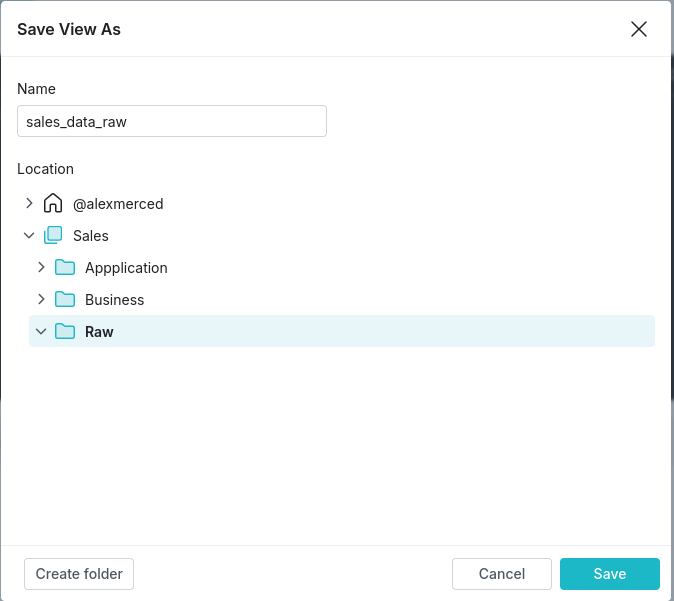
Data Curation Strategies
Data curation within Dremio can involve organizing data into layers, often following a three-tiered structure: raw/bronze, clean/business/silver, and gold/application. These layers are especially valuable when working across Snowflake and HDFS/Hive environments, as they help standardize and simplify access to complex datasets.
- Raw/Bronze Layer:
The raw layer represents the initial data directly pulled from each source. This layer is generally unprocessed and serves as a foundation for all subsequent transformations. Storing data in this format makes it easier to revisit or transform the data if new requirements arise. - Clean/Business/Silver Layer:
In the clean layer, data is transformed, cleaned, and standardized. Here, you can handle any necessary data transformations to harmonize fields across Snowflake and HDFS/Hive. For example, this might involve formatting date fields consistently or standardizing units of measure to create a unified dataset. - Gold/Application Layer:
The gold layer represents the curated, business-ready views that are optimized for analysis and reporting. This layer can be further accelerated by Dremio’s reflections, which materialize data and provide significant query performance improvements. Gold views often combine data from multiple sources, presenting a “single source of truth” for end users.
By curating your data in Dremio across these layers, you simplify data management and optimize data access for analysts and data consumers. This approach helps ensure that the right data is easily accessible and ready for quick insights without requiring repeated transformations or heavy queries.
With the established virtual views and curated layers, Dremio’s reflections can take your performance to the next level, ensuring that the gold layer remains high-performing and query-ready.
Accelerating Queries with Dremio Reflections
Dremio’s reflections feature provides a powerful way to optimize query performance, especially when working with cross-environment data. By creating materialized representations of frequently accessed data, reflections enable faster queries without compromising the accuracy or integrity of the sources. In a setup where data from Snowflake and HDFS/Hive is joined in Dremio, reflections can be a game-changer for achieving low-latency analytics.
Reflection Types and Use Cases
Dremio offers two main types of reflections — raw and aggregation — each designed to optimize different types of queries:
- Raw Reflections:
Raw reflections store a physical copy of the underlying data from one or more fields in the view. These are particularly useful when working with large datasets or when queries often filter on specific columns. For example, if your gold layer combines Snowflake’s customer data and HDFS/Hive’s transactional data, a raw reflection can speed up queries that repeatedly access only a subset of columns. - Aggregation Reflections:
Aggregation reflections precompute summary metrics across specific fields, such as sums or averages. These reflections are ideal for BI-style queries that involve GROUP BY and aggregation functions. An aggregation reflection could store the precomputed monthly revenue figures in a cross-environment view that calculates monthly revenue from transactional data, significantly reducing query times.
Implementing Reflections for the “Gold” Layer
Reflections are particularly effective when applied to the curated gold layer. This is where data consumers access clean, business-ready datasets, making query speed a top priority. By materializing these views with reflections, Dremio can optimize frequently used queries, ensuring quick access to insights.
- Setting Up a Reflection:
To set up a reflection in Dremio, go to the Reflections tab from details view of that dataset. Choose between a raw or aggregation reflection, depending on your query needs, and configure fields and filters as required. - Example Use Case:
Suppose you have a gold-layer view that joins customer data from Snowflake with sales data from Hive. Queries on this view might frequently aggregate sales by customer segment. By creating an aggregation reflection with “customer segment” as a dimension and “sales amount” as a measure, you enable Dremio to bypass expensive aggregations at query time, serving up results from the precomputed reflection instead.
Using Incremental and Live Reflection Refresh Policies
Maintaining up-to-date reflections is crucial when dealing with dynamic data. Dremio’s incremental and live refresh policies allow you to automatically update reflections, ensuring that data in the gold layer remains accurate and performance-ready (these are enabled for Apache Iceberg tables, so you'd maybe want to transform your silver layer into Iceberg tables to build your gold layer on to leverage these advanced Iceberg features).
- Incremental Refresh:
Incremental refreshes update only the new or modified data, reducing the resource load on your system. This is beneficial when data is appended regularly to either Snowflake or Hive tables, such as daily transactions. - Live Refresh:
With live refresh, reflections are kept in sync with the source data in real-time, ideal for use cases that require the latest data at all times. For example, a dashboard tracking sales metrics would benefit from a live refresh to reflect the most current data without requiring manual updates.
By leveraging reflections, Dremio helps ensure that the gold layer remains both high-performing and accurate, facilitating quick insights across combined Snowflake and HDFS/Hive datasets. Reflections enhance performance and reduce load on your underlying systems, enabling more efficient data operations across cloud and on-prem environments.
With reflections in place, users can query cross-environment datasets easily, accelerating the time to insight and making Dremio a valuable asset in hybrid data architectures.
Practical Use Case Scenarios
To illustrate the power of combining Snowflake and HDFS/Hive data in Dremio, let’s explore a few practical scenarios. These examples showcase how Dremio’s cross-environment capabilities and reflections optimize data analytics workflows, delivering meaningful insights across cloud and on-premises environments.
Example Scenario 1: Comprehensive Sales and Customer Analysis
In a typical e-commerce setup, customer engagement data is stored in Snowflake, while historical transactional data reside on-prem in Hive. By creating a virtual dataset in Dremio, you can join these sources to analyze customer behavior across both recent and historical data:
- Objective:
Track how customer engagement metrics correlate with past purchase behaviors, creating a 360-degree view of customer interactions. - Solution with Dremio:
Using Dremio’s SQL editor, create a view that joins Snowflake’s customer engagement data with transactional records in Hive based on customer ID. This view can then be further curated to show only relevant fields, like total purchases and recent engagement activity. - Benefit of Reflections:
To accelerate analysis, apply a raw reflection on this view, focusing on commonly queried fields such as “customer_id,” “total_purchases,” and “last_engagement_date.” This will enable faster access for data consumers and BI tools, allowing analysts to explore engagement and sales trends without querying the full source data each time.
Example Scenario 2: Real-Time Revenue Analysis
For companies that need to monitor sales performance in near real-time, combining Snowflake’s recent sales data with historical data in Hive offers a streamlined approach to accurate, cross-environment analytics:
- Objective:
Generate a near-real-time revenue dashboard that combines current and historical sales, segmented by region, product, and other business dimensions. - Solution with Dremio:
Create a gold-layer view in Dremio that aggregates sales data by region and product category. By joining recent Snowflake data with historical Hive data, the view can provide a complete picture of sales trends across time periods. - Benefit of Reflections:
An aggregation reflection on this view with “region” and “product category” as dimensions and “sales_amount” as a measure enables Dremio to precompute revenue summaries, drastically reducing query times. Configuring a live refresh policy on the reflection ensures the dashboard remains current, enabling real-time visibility into revenue trends as new data flows into Snowflake and Hive.
Example Scenario 3: Product Inventory and Demand Forecasting
Manufacturing and retail companies often need to manage inventory data stored on-prem (in Hive or HDFS) while relying on cloud data for predictive models and demand forecasts:
- Objective:
Forecast product demand by combining historical inventory data in Hive with real-time sales trends from Snowflake. - Solution with Dremio:
Create a virtual dataset that joins inventory history in Hive with recent sales in Snowflake, grouped by product category. This allows analysts to compare current inventory levels with predicted demand based on sales trends. - Benefit of Reflections:
Applying a raw reflection on this view, with partitions on “product_id” and “date,” enables faster queries for demand forecasting across multiple products. Using an incremental refresh policy ensures the reflection includes the latest sales data without requiring a full refresh, optimizing resource use and keeping forecasts up-to-date.
These scenarios highlight the value of Dremio’s cross-environment views and reflections for building efficient, data-driven solutions. By combining data from Snowflake and HDFS/Hive, Dremio not only streamlines data integration but also empowers teams to achieve performance gains and real-time insights across complex data environments.
6. Conclusion
Dremio’s unique ability to support cross-environment queries and accelerate them with reflections enables businesses to leverage a true lakehouse architecture, where data can be stored in the most suitable environment — whether on-premises or in the cloud — and accessed seamlessly through Dremio. This integration ultimately empowers teams to deliver insights faster and at lower cost, supporting strategic decision-making with a unified, high-performance data platform.
With Dremio, the complexity of hybrid data environments becomes manageable, allowing organizations to focus on what matters most: extracting actionable insights from their data.
Additional Resources

BLOG
Hadoop Modernization on AWS with Dremio: The Path to Faster, Scalable, and Cost-Efficient Data Analytics
Hadoop modernization on AWS with Dremio represents a significant leap forward for organizations looking to leverage their data more effectively. By migrating to a cloud-native architecture, decoupling storage and compute, and enabling self-service data access, businesses can unlock the full potential of their data while minimizing costs and operational complexity.
Dremio Blog: Partnerships Unveiled,
Learn More ->

BLOG
What is ADLS Gen2 and Why it Matters
Described by Microsoft as a “no-compromise data lake”, ADLS Gen 2 extends the capabilities of Azure Blob Storage and is optimized for large scale analytics workloads.
Dremio Blog: Partnerships Unveiled,
Learn More ->

BLOG
Using Dremio, lakeFS & Python for Multimodal Data Management
With lakeFS, you version everything: Iceberg tables, images, models, logs. With Dremio, you query and analyze it all, structured or not, at scale. Together, they bring Git-style control and interactive querying to your data lake, so you can build more intelligent, version-aware workflows without sacrificing flexibility or performance.
Dremio Blog: Partnerships Unveiled,
Learn More ->