21 minute read · June 20, 2018
Origin and History of Apache Arrow
Apache Arrow was announced as a top level Apache project on February 17, 2016. We wanted to give some context regarding the inception of the project, as well as interesting developments as the project has evolved. Arrow has grown from a specification for columnar data to include sophisticated, hardware-aware processing libraries, as well as bindings in many of the most popular programming languages. This is an exciting project that spans many other open source projects, and has grown very rapidly in the past two and a half years.
Background
The idea of columnar data has been around for many years, both in academic research and in commercial products like Sybase IQ. Columnar formats provide advantages at the storage layer in terms of compression and scan efficiency. But for in-memory processing most of these systems performed row-oriented operations. As hardware trends evolved to include more cores as well as SIMD and superscalar processing, as well as GPUs, the idea of columnar data for in-memory processing gained academic interest.
In 2005 the MonetDB/X100 paper presented research on a new query engine for MonetDB
“The second part of the paper describes the architecture of our new X100 query engine for the MonetDB system … On the surface, it resembles a classical Volcano-style engine, but the crucial difference to base all execution on the concept of vector processing makes it highly CPU efficient. We evaluate the power of MonetDB/X100 on the 100GB version of TPC-H, showing its raw execution power to be between one and two orders of magnitude higher than previous technology.”
MonetDB already stored data on disk in a columnar format. The X100 engine added columnar execution of in-memory data to improve performance by 100x. “Small (e.g. 1000 values) vertical chunks of cache-resident data items, called ‘vectors’ are the unit of operation for X100 execution primitives.” By organizing data in small “chunks” of contiguous values, the X100 engine was made to make processing significantly more efficient by taking advantage of superscalar and SIMD CPUs. A group of values could be processed together in a single instruction, rather than one value per instruction.
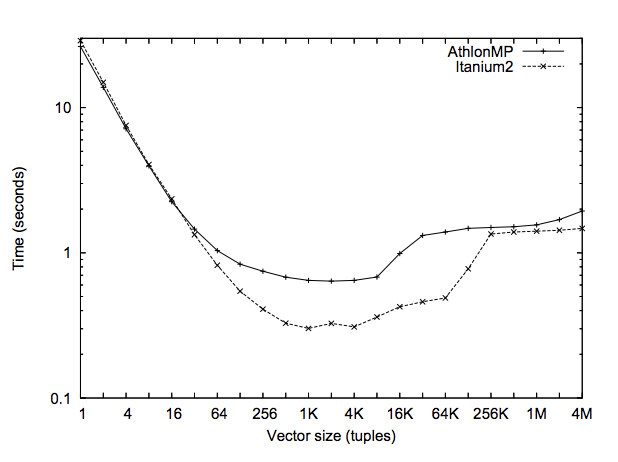
The advantages are clear as the number of values in the vector increases, up to a limit:
“With increasing vector size, the execution time quickly improves. For this query and these platforms, the optimal vector size seems to be 1000, but all values between 128 and 8K actually work well. Performance starts to deteriorate when intermediate results do not fit in the cache anymore.”
Columnar and Big Data
In the Big Data world, we didn’t see much talk about columnar data until Google’s Dremel paper in 2010, which included a distributed SQL execution engine, decoupled storage, and a columnar file format to represent flat and nested data structures. This paper influenced Hadoop projects for SQL engines and those for columnar data, like Apache Parquet (originally called Red Elm, an anagram for Dremel) and Apache ORC, which came a few years later and significantly improved the efficiency of data processing in Hadoop.
The X100 paper talks about the need to “fight bottlenecks throughout the entire computer architecture” to reach new levels of performance. In Big Data we could see this happening throughout the stack, with columnar file formats, scheduling optimizations, as well as new projects for SQL on Hadoop. But there was no emerging standard for in-memory columnar processing.
Parquet and ORC are file formats and are independent of different programs that read and process this data. Impala, for example, can read these columnar formats, but its processing is row-oriented. At Dremio we wanted to build on the lessons of the MonetDB/X100 paper to take advantage of columnar in-memory processing in a distributed environment.
As we were building a columnar processing model into early versions of Dremio, we started to hear about other projects who were interested in columnar in-memory processing. During 2015 we discussed the idea of building an independent project that could be used by other relevant projects. Since late 2014, Wes had been researching ways to improve Python’s interoperability with big data systems like Apache Impala and Spark. One of the biggest issues was efficient columnar data interchange between these systems.
Building a common solution for the problem made more sense than two custom solutions. We met with leaders of other projects, such as Hive, Impala, and Spark/Tungsten. These conversations naturally led to other conversations with similar projects, such as R, Cassandra, Calcite, Phoenix, Drill and others who were interested.
Over the course of many conversations, it became clear a new project made sense. The depth of experience and diverse perspectives helped to shape our early ideas. For example, at the end of September 2015, Wes, Marcel Kornacker, and I met with a few other interested developers at Strata NYC to discuss details of the design. One topic of non-trivial disagreement was whether we needed both named and unnamed union types. This discussion informed how we ultimately implemented sparse and dense union types in Arrow, which turn out to be very useful in how users manage nested data structures efficiently for vectorized processing.
One of the key ideas of Arrow was that rather than each project re-inventing the wheel, one canonical representation for columnar in-memory data could serve the diverse needs of many projects. More importantly, a single standard could also dramatically improve the efficiency of data interchange between different processes, such as Java and Python. It was also clear there was an emerging interest in using GPUs for analytical workloads, and so we wanted to design Arrow for where we all felt hardware was headed.
Wes and I started to recruit other folks to form the basis of a PMC for a new Apache project. Several of us had been involved with a number of different Apache projects and believed that building this effort as an Apache project made sense. We approached the foundation and suggested that given the nature of people involved (5 Apache Members; 6 PMC Chairs; and people involved in dozens of PMC and committer roles across more than a dozen projects), we should directly start the new project as a new top-level Apache project. They agreed.
At Dremio we started the project as codename RootZero. As discussions expanded to include many others, we had been operating under the “ValueVectors Initiative”, named after some of the early code several of us had written for the Apache Drill project. When we finally recommended the project to the ASF board, it became clear that a formal name was required. As a group we drew up a short list of name candidates (for fun, here are the candidates and voting results). After a vote among people involved in the formation of the new project, Arrow was selected, and that is how Apache Arrow began.
Arrow and Python
Dremio is written in Java, and so engineers contributing at Dremio were primarily focused on the Java implementation of Arrow. Wes took the lead in development of the C++ and Python implementations of Arrow. Wes was interested in improving the speed of accessing data from Python-based processes, and in improving the interoperability between Python and other systems such as R.
While R and Python have similar dataframe concepts, the internal implementations are very different. One of the first things Wes did was to work with Hadley Wickham to use Arrow in a project called Feather, a binary on-disk format for storing dataframes for both Python and R. Without Feather the main way Python and R exchange data is through CSV! (Feather was ultimately merged back into Arrow and still exists today.)
Wes also started to work Arrow into pandas, one of the most popular libraries in Python. He details his thinking and experiences in an excellent blog: Apache Arrow and 10 Things I Hate About pandas. More recently he announced the creation of Ursa Labs to “accelerate the work of data scientists through more efficient and scalable in-memory computing.” Much of this work is based on Arrow as well.
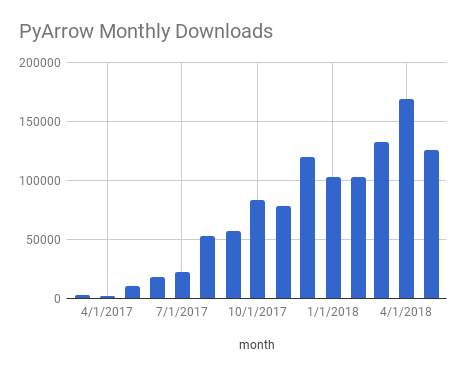
Uwe Korn and Wes have developed an efficient way for Python users to read and write Parquet and have made this code available as part of the Arrow and Parquet codebases in a library called pyarrow. This library has become remarkably popular is a short time, as can be seen in the number of downloads below:
Arrow and Spark
Arrow aims to bridge different worlds of processing. One place the need for such a bridge is most clearly apparent is between JVM and non-JVM processing environments, such as Python. Traditionally, these two worlds don’t play very well together. And so one of the things that we have focused on is trying to make sure that exchanging data between something like pandas and the JVM is a lot easier and more efficient.
One way to distribute Python-based processing across many machines is through Spark and the PySpark project. In the past users have had to decide between more efficient processing via Scala, which is native to the JVM, vs use of Python which has much broader use among data scientists but was far less efficient to run on the JVM. With Arrow Python-based processing on the JVM can be dramatically faster.
Bryan Cutler, Li Jin, and others from Two Sigma and the team at IBM did a lot of work to PySpark to incorporate Arrow. There’s a great blog on this work explaining their approach, with sample code. Another good post on the Databricks blog from Li can be found here which describes an Arrow-based vectorized UDF execution path inside PySpark.
You can easily toggle between having Arrow enabled or disabled and see the differences side by side:
There’s an interesting discussion in this Spark pull request https://github.com/apache/spark/pull/15821 where Bryan shows a 53x speedup by using Arrow in a simple test. As Bryan says in his blog, “it is clear there is a huge performance boost and using Arrow took something that was excruciatingly slow and speeds it up to be barely noticeable.” Bryan recently spoke at an Arrow meetup, and you can watch that presentation and read the transcript here.
Arrow and Dremio
In Dremio we make extensive use of Arrow. As Dremio reads data from different file formats (Parquet, JSON, CSV, Excel, etc) and different sources (RDBMS, Elasticsearch, MongoDB, HDFS, S3, etc), data is read into native Arrow buffers directly for all processing. Our vectorized Parquet reader makes reading into Arrow especially fast, and so we use Parquet to persist our Data Reflections for accelerating queries, then read them into memory as Arrow for processing.
For client applications interacting with Dremio, today we serialize the data into a common structure. For example, for applications such as Tableau that query Dremio via ODBC, we process the query and stream the results all the way to the ODBC client before serializing to a cell-based protocol that ODBC expects. The same is true for all JDBC applications.
Recently we proposed Apache Arrow Flight, a new way for applications to interact with Arrow. Now that we have an established way for representing data between systems, Flight is an RPC protocol for exchanging that data between systems much more efficiently. You can think of this as a much faster alternative to ODBC/JDBC for in-memory analytics.
If REST is the primary protocol for microservices, we hope Flight can be the primary protocol for data microservices. This is essentially the ability to stitch different dataset together in a non-monolithic way.
As soon as Arrow Flight is generally available, applications that implement Arrow can consume the Arrow buffers directly, in a dramatically more efficient manner. In our internal tests we observe from 10x-100x efficiency improvements with this approach compared to ODBC/JDBC interfaces.
Arrow and GPUs
GPUs have become popular for running analytical workloads because they can process parallelizable workloads much more efficiently than CPUs. We designed Arrow with GPUs in mind. Arrow’s columnar format is especially useful in this context where GPU RAM is much more scarce than main memory.
In 2017 a group of companies including NVIDIA, MapD, Graphistry, H20.ai and others announced the GPU Open Analytics Initiative. Part of this work is what the group calls a “GPU dataframe” which uses the Arrow columnar format. This work makes it far more efficient for data science environments, GPU databases, and other systems to interoperate on data far more efficiently, making the best use of GPU and GPU RAM for analytical workloads.
Arrow and RISELab
Apache Spark was created by the AMPLab at UC Berkeley, and several of the original contributors went on to found Databricks. Berkeley runs these projects as 5 year lab exercises, and AMPLab closed down in 2016. The successor is the RISELab, a new effort recognizing (from their project page):
- Sensors are everywhere. We carry them in our pockets, we embed them in our homes, we pass them on the street. Our world will be quantified, in fine detail, in real time.
- AI is for real. Big data and cheap compute finally made some of the big ideas of AI a practical reality. There’s a ton more to be done, but learning and prediction are now practical tools in the computing toolbox.
- The world is programmable. Our vehicles, houses, workplaces and medical devices are increasingly networked and programmable. The effects of computation are extending to include our homes, cities, airspace, and bloodstreams.
One of the interesting projects that has come out of RISELab is Ray, a “high-performance distributed execution framework targeted at large-scale machine learning and reinforcement learning applications,” which many have called a successor to Spark.
Plasma was developed as part of the Ray project to “hold immutable objects in shared memory so that they can be accessed efficiently by many clients across process boundaries.” Last year the RISELab team donated this code to Apache Arrow and have continued developing it. There’s a good blog on their motivations here.
The Gandiva Initiative
Recently the team at Dremio open sourced The Gandiva Initiative for Apache Arrow. This is a new execution kernel for Arrow that is based on LLVM. Gandiva provides very significant performance improvements for low-level operations on Arrow buffers. Ravindra has put together an in-depth blog for a discussion on the design and some of the performance tests.
Gandiva is a mythical bow from the Indian epic The Mahabharata used by the hero Arjuna. According to the story Gandiva is indestructible, and it makes the arrows it fires 1000x more powerful.
Arrow and New Language Bindings
In addition to Java, C++, and Python, new language bindings have been created by the Arrow community.
- C. One day a new member showed up and quietly opened ARROW-631 with a first pull request including over 18k lines of code. Kouhei Sutou had hand-built C bindings for Arrow based on GLib!!
- Ruby. Kouhei also contributed Red Arrow, his Ruby bindings based on the C bindings he built. Kouhei also does a lot to support Arrow in Japan.
- JavaScript. Two different projects for JavaScript bindings developed in parallel before the teams joined forces to produce a single high quality library. Brian Hulette at CCRi had been working on the Geomesa project, and he joined up with the folks at Graphistry, who cover their work in an article on KDNuggets, and there’s a cool video of their work (jump to 19:00). This JavaScript work also opens up Arrow to the world of node applications in exciting ways as well.
- Rust. Andy Grove has been working on a Rust-based data processing platform similar to Spark that uses Arrow as its internal memory format. He wrote about this work in a blog here.
- Go. Influxdata has started to use Arrow in their popular time series database, InfluxDB, and contributed Go bindings along the way. They shared some of of the interesting details of their implementation in a blog post.
What’s Next for Apache Arrow?
The Arrow community has grown very rapidly. In a little over two years, it has had more code contributions than many very popular projects that are 2 or 3 times its age. While it started with a format specification, it has grown both in breadth (bindings and languages) and depth (functionality and scope). Arrow is now so much more, and it has a very bright future.
It’s been exciting to see so much activity by so many different groups of users, each with different needs, but with so very much in common. The Arrow community will continue to work together to chart its own course, and I encourage you to join the mailing list to ask questions and to contribute your work to the project. Whether you’re a developer, can provide feedback on usage, help test, add documentation, or just talk about your use cases and workload, all types of help are valuable and appreciated.
Learn More
Ready to Learn More?
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->