20 minute read · May 12, 2023
Introducing the Apache Iceberg Catalog Migration Tool
· Developer Advocate, Dremio
· Open-Source Software Engineer

Catalogs in Apache Iceberg
In the Apache Iceberg world, a catalog is a logical namespace that contains information to fetch metadata about the tables. A catalog acts as a centralized repository that allows managing tables and their versions, facilitating operations such as creating, updating, and deleting tables. Most importantly, the catalog holds the reference to the current metadata pointer, i.e., the latest metadata file.
Regardless of whether you are performing a read or write operation, a catalog is the first point of contact for query engines. During a read operation, the engine queries the catalog to gather information about the current state of the table. This ensures that the readers always see the latest version of the table. Alternatively, if you are doing writes, the catalog is consulted to ensure the engine can adhere to the table's defined schema and partitioning scheme. A catalog in Apache Iceberg brings in the atomicity and consistency guarantees for multiple concurrent reads and writes. There are a variety of catalogs to choose from, such as Project Nessie, AWS Glue, Dremio Arctic, Hive Metastore, etc. Technically, any database or datastore can be used as a catalog as long as it is able to perform an atomic swap operation. The atomic swap is necessary to commit new versions of the table metadata.
Introducing a Catalog Migration Tool
There are a few scenarios when you want to migrate your existing Apache Iceberg tables from one particular catalog to another. For example, you may be just starting out and testing Apache Iceberg as the table format for your data lake and have used a file-system-based catalog like the Hadoop catalog backed by Hadoop Distributed File System (HDFS). Typically, the Hadoop catalog is not recommended for production usage as it has no reliable locking mechanism and would impact concurrent reads and writes. So, at this point, you would have to migrate your catalog to some production-ready options.
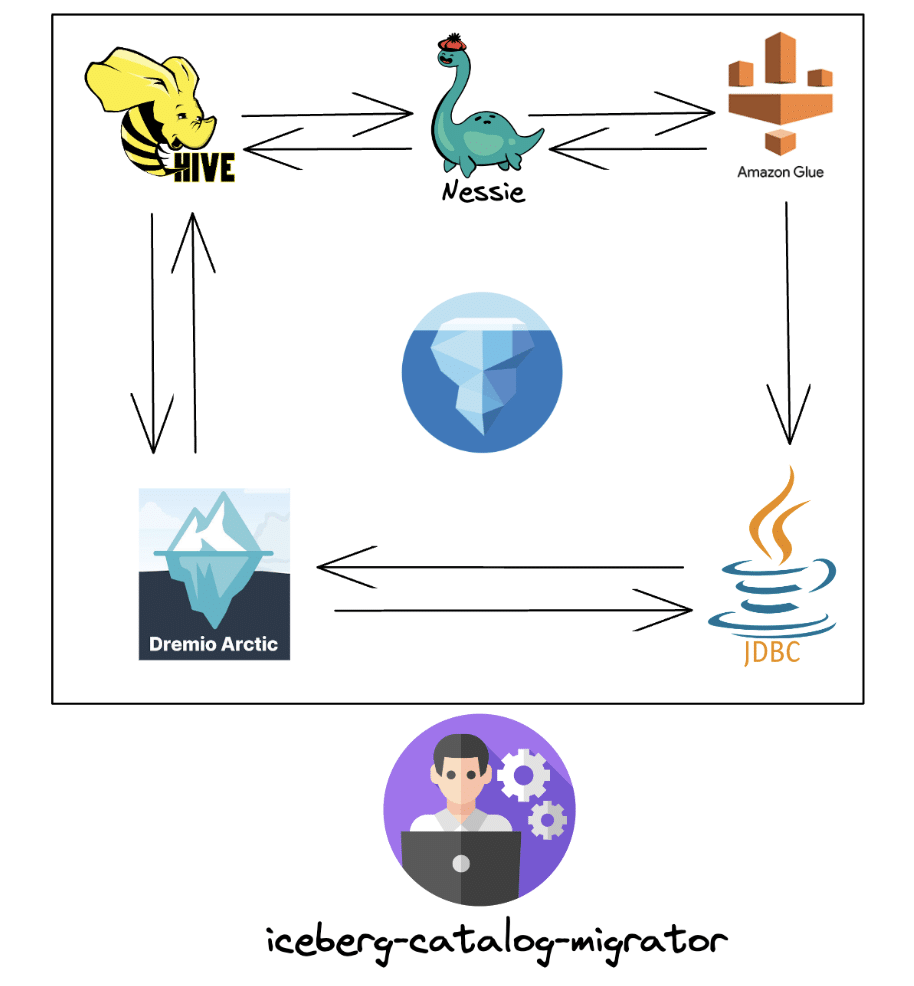
Until this point, there was just one way to achieve a migration between specific catalogs, and to do so you would have to use the Catalog.registerTable() interface from the Java API. It required pointing the metadata.json file to the new catalog. Today, we are announcing the beta release of a new command-line tool called iceberg-catalog-migrator. It enables bulk migration of Apache Iceberg tables from one catalog to another without the need to copy data. The tool supports all of the commonly used catalogs in Apache Iceberg, such as AWS Glue, Nessie, Dremio Arctic, Hadoop, Hive, REST, JDBC and any custom catalogs.
The tool is an open source project with Apache License under the Project Nessie. To maintain a clear emphasis on the table format specification and engine integration, the Apache Iceberg community opted to maintain a distinct codebase for the tool, separate from the Iceberg repository.
Iceberg-Catalog-Migrator
The iceberg-catalog-migrator CLI tool currently supports two commands:
Migrate: The migrate command allows you to bulk migrate Iceberg tables from the source catalog to the target without making data copies. After successful migration, table entries from the source catalog will be deleted.
Register: The register command allows you to register Iceberg tables from source to the target catalog without making data copies. This means that tables will be present in both catalogs after registering. This feature can be highly beneficial for scenarios such as pre-migration validation testing and testing out new catalogs with unique features.
Notes:
- Both of these commands migrate the entire history of the table. Therefore, we can do things like time-travel from the new catalog after migration or registering.
- Since the
registercommand doesn’t delete tables from the source catalog, we need to ensure that we don’t operate the same table from more than one catalog, as it can lead to missing updates, loss of data, and table corruption. It is therefore advised to use the migrate command to automatically delete the table from the source catalog after registering. Alternatively, avoid operating tables from the source catalog after registering if the migrate option is not used.
- Avoid using the CLI tool when there are in-progress commits for tables in the source catalog to prevent missing updates, data loss, and table corruption in the target catalog. This is because during migration, the tool captures a particular state of the table i.e. a metadata file and uses that state for registering into the target catalog. If there are in-progress commits to the source catalog table, the new commits won’t reflect on the target catalog, which could compromise the integrity of your data. A general recommendation here is that instead of migrating all tables at once, users can plan for a batch-wise migration approach using a regex expression (e.g. all tables that start with a namespace ‘foo’). Additionally, this could be a part of the regular maintenance and downtime process so users can avoid writing data during this phase and pause any automated running jobs.
Here is the CLI syntax.
$ java -jar iceberg-catalog-migrator-cli-0.2.0.jar -h
Usage: iceberg-catalog-migrator [-hV] [COMMAND]
-h, --help Show this help message and exit.
-V, --version Print version information and exit.
Commands:
migrate Bulk migrate the iceberg tables from source catalog to target catalog without data copy. Table entries from source catalog will be deleted after the successful migration to the target catalog.
register Bulk register the iceberg tables from source catalog to target catalog without data copy.Now, let’s explore a few of the CLI feature flags that may generally be involved with any migration. To learn more about all the feature flags, refer to the repository.
java -jar iceberg-catalog-migrator-cli-0.2.0.jar migrate \ --source-catalog-type GLUE \ --source-catalog-properties warehouse=s3a://bucket/gluecatalog/,io-impl=org.apache.iceberg.aws.s3.S3FileIO \ --target-catalog-type NESSIE \ --target-catalog-properties uri=http://localhost:19120/api/v1,ref=main,warehouse=s3a://bucket/nessie/,io-impl=org.apache.iceberg.aws.s3.S3FileIO \ --identifiers db1.nominees
--source-catalog-type: Parameter to specify the type of the source catalog.
Example: --source-catalog-type GLUE
--source-catalog-properties: Iceberg catalog properties for the source catalog. Things like URI, warehouse location, io-impl, etc. Example: --source-catalog-properties warehouse=s3a://bucket/gluecatalog/
--target-catalog-type: Type of the target catalog. Example: --target-catalog-type NESSIE
--target-catalog-properties: Iceberg catalog properties for the target catalog. Example: uri=http://localhost:19120/api/v1,ref=main,warehouse=s3a://bucket/nessie/,io-impl=org.apache.iceberg.aws.s3.S3FileIO
--output-dir=<outputDirPath>: Optional local output directory path to write CLI output files like `failed_identifiers.txt`, `failed_to_delete_at_source.txt`, `dry_run_identifiers.txt`. If this is not specified, it uses the present working directory. Example: --output-dir /tmp/output/
--dry-run: Optional configuration to simulate the registration without actually registering. You can learn about the list of tables that will be registered by executing this flag.
--stacktrace: Optional configuration to enable capturing stack trace in logs in case of failures.
--identifiers: Optional selective set of identifiers to register. If not specified, all the tables will be registered. Use this when there are few identifiers that need to be registered. For a large number of identifiers, use the `--identifiers-from-file` or `--identifiers-regex` option.
How to get started?
You need to have Java (recommended version JDK 11) installed on your machine to run this CLI tool. The standalone jar file can be downloaded from Github for use locally. You can also use the wget command to download the required files to a remote machine (Docker container).
wget https://github.com/projectnessie/iceberg-catalog-migrator/releases/download/catalog-migrator-0.2.0/iceberg-catalog-migrator-cli-0.2.0.jar
Note that when run locally, the tool has capabilities to list out the failed migration tables (caused by any connectivity issues) so they can be retried. However, if there is a better fault tolerant environment for organizations to execute the tool, they can choose to use such environments.
Now let’s take a look at a few scenarios where the iceberg-catalog-migrator tool could be beneficial. We will also understand how to practically migrate catalogs using the tool.
Scenario 1: Migrate to a production-ready catalog like Dremio Arctic
For the 1st scenario, let’s say an organization has been testing out Apache Iceberg as the table format for their S3 data lake. Since they were initially in an experimental phase, they used the Hadoop catalog as their catalog. The project has now received the necessary sign-offs to deploy Iceberg in production. However, the Hadoop catalog is not recommended for production use. So, in this situation, the idea would be to migrate the existing HDFS catalog to a production-ready catalog such as Dremio Arctic.
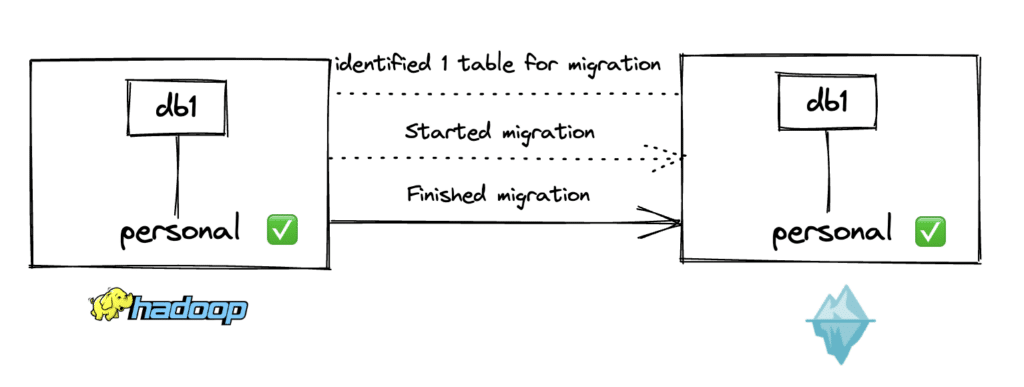
Note that if the source catalog is Hadoop, you can only register tables, not migrate. This is because the Hadoop catalog doesn’t support un-registering the tables without deleting the actual data files. This is how the Hadoop catalog interface is currently implemented in Iceberg (some details here).
Here is the CLI syntax to bulk register 100+ tables existing in the Hadoop catalog.
java -jar iceberg-catalog-migrator-cli-0.2.0.jar register \ --source-catalog-type HADOOP \ --source-catalog-properties warehouse=/tmp/warehouse/,type=hadoop \ --target-catalog-type NESSIE \ --target-catalog-properties warehouse=/tmp/arctic/,uri=https://nessie.dremio.cloud/v1/repositories/d74738b9-2855-4110-92b4-ad0ceae2ab80,ref=main,authentication.type=BEARER,authentication.token=$PAT \ --stacktrace
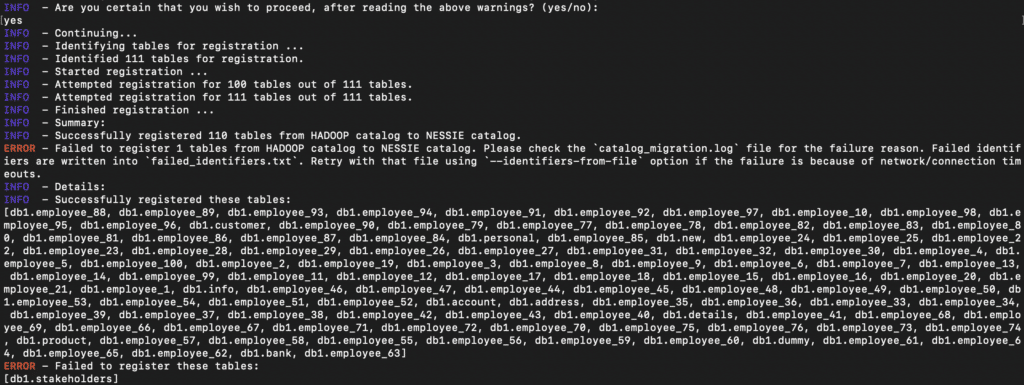
As you can see in the output, 110 tables from the Hadoop catalog are now registered to the Arctic catalog. So, if someone queries any of these tables in the Arctic catalog, they should be able to access the data now. One of the tables failed to migrate as that table was already present in the Arctic catalog.
Suppose the organization has other tables within the Hadoop catalog that they want to migrate particularly. In that case, they can list them out using the identifiers property. Note that, by default, the engine will register all the tables from the Hadoop catalog’s configured namespace if you don't specify any identifiers.
Using the catalog migration tool, organizations can now ensure a hassle-free migration of their catalogs and finally be able to deploy Iceberg to production.
Scenario 2: Migrate to an AWS-specific catalog like Glue
In this scenario, we will see how to migrate an Iceberg table from the Hadoop catalog to AWS Glue. Organizations might want their Iceberg catalog to be a part of their already existing AWS stack so they can integrate and interoperate better with other technologies within AWS. When a Glue catalog is used, an Iceberg namespace is stored as a Glue Database, and an Iceberg table is stored as a Glue Table. More information around Iceberg-AWS integration can be found here.
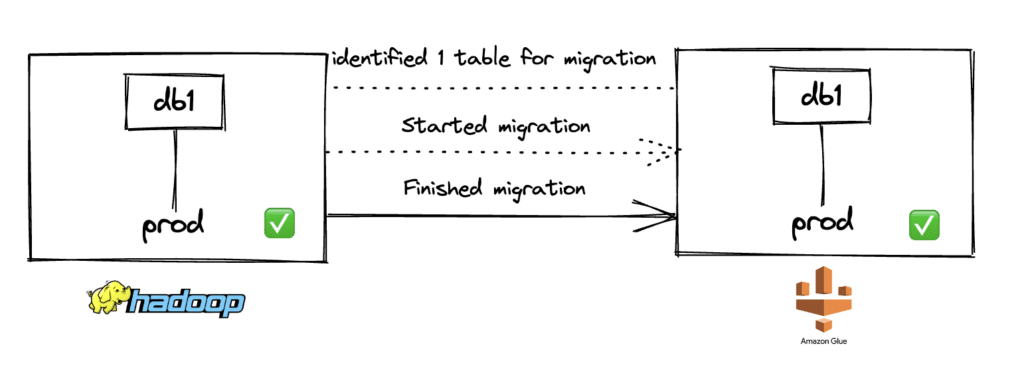
Here is the CLI command:
java -jar iceberg-catalog-migrator-cli-0.2.0.jar register \ --source-catalog-type HADOOP \ --source-catalog-properties warehouse=s3a://dm-iceberg/hadoopcatalog/,type=hadoop,io-impl=org.apache.iceberg.aws.s3.S3FileIO \ --target-catalog-type GLUE \ --target-catalog-properties warehouse=s3a://dm-iceberg/gluecatalog/,io-impl=org.apache.iceberg.aws.s3.S3FileIO \ --source-catalog-hadoop-conf fs.s3a.secret.key=$AWS_SECRET_ACCESS_KEY,fs.s3a.access.key=$AWS_ACCESS_KEY_ID \ --identifiers db1.prod \ --stacktrace
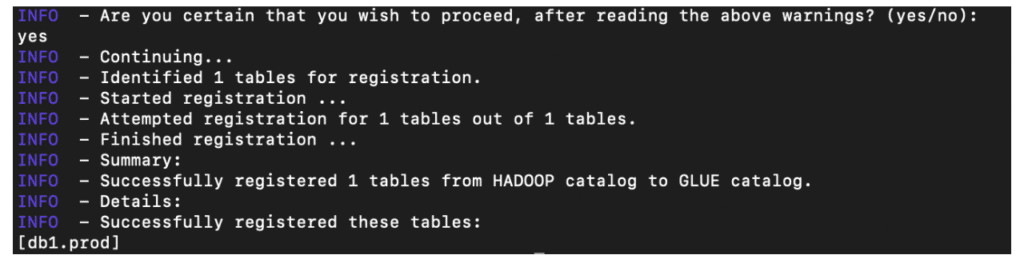
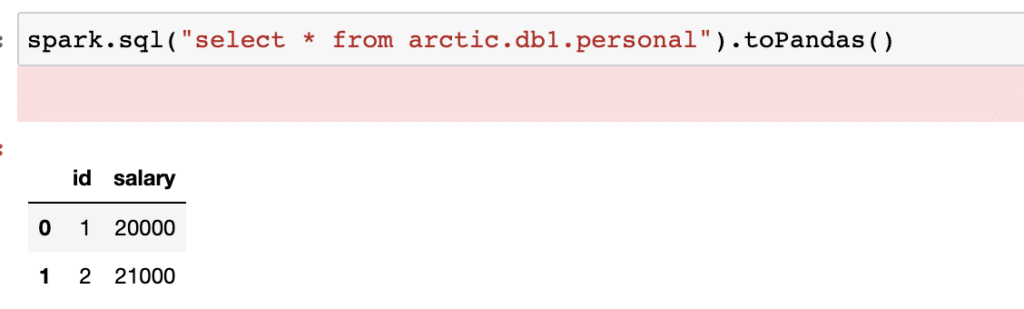
As seen below, the table prod is now available to be queried from the Glue catalog.

Scenario 3: Migrate to Nessie to take advantage of data-as-code
Let’s say an organization uses AWS Glue as the catalog for their Apache Iceberg tables. Now they have a new use case within their data organization where they would like to have different isolated working environments for their data scientists to experiment with new features so they can build robust ML models. This way, they don’t have to worry about any impacts on the production Iceberg tables or creating unmanageable data copies.
The organization has been hearing about Project Nessie and the data-as-code approach that brings a Git-like experience to the world of data lakes. Specifically, they are interested in using Nessie's branching, tagging, and commits capability to work with isolated data environments.
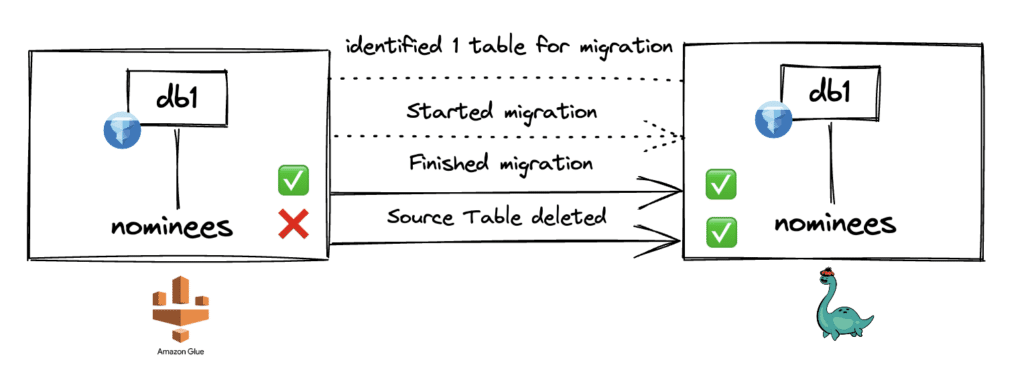
To start the migration of table nominees from Glue to Nessie, they use the following syntax.
java -jar iceberg-catalog-migrator-cli-0.2.0.jar migrate \ --source-catalog-type GLUE \ --source-catalog-properties warehouse=s3a://bucket/gluecatalog/,io-impl=org.apache.iceberg.aws.s3.S3FileIO \ --target-catalog-type NESSIE \ --target-catalog-properties uri=http://localhost:19120/api/v1,ref=main,warehouse=s3a://bucket/nessie/,io-impl=org.apache.iceberg.aws.s3.S3FileIO \ --identifiers db1.nominees
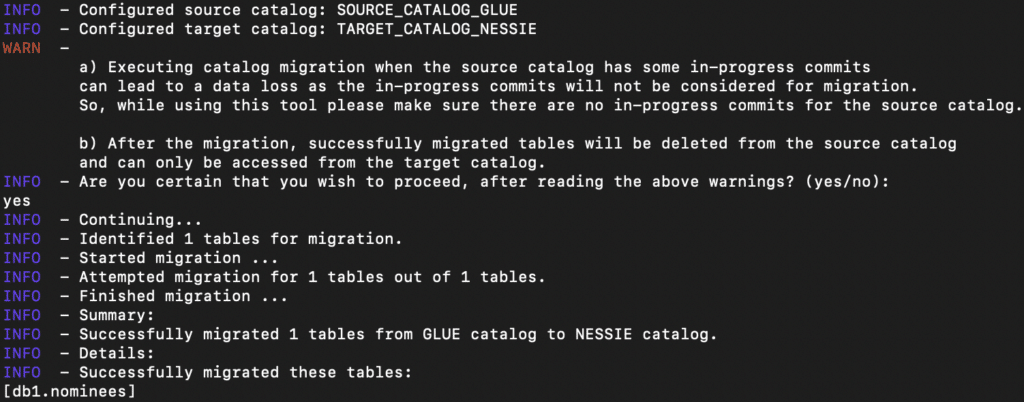
As seen, the migration was completed successfully, and the table should be available in the Nessie catalog. Users (such as data scientists) can now create local branches using the Nessie catalog and continue their experimental feature engineering work without impacting production tables.
Failures and Inspecting Logs
There can be situations when the catalog migration fails due to a variety of reasons such as - not having right access (AWS credentials), invalid warehouse locations, network issues (e.g. connecting to Nessie endpoint), etc. The catalog migration tool writes out all these errors in a log file called catalog_migration.log. The verbosity level of these logs can be changed by adding a feature flag called --stacktrace. This allows us to have some more context around the error.
Here is a scenario where the migration fails as seen in the snippet below.

This was the CLI syntax.
$ java -jar iceberg-catalog-migrator-cli-0.2.0.jar register \ --source-catalog-type HADOOP \ --source-catalog-properties warehouse=/tmp/warehouse/,type=hadoop \ --target-catalog-type NESSIE \ --target-catalog-properties warehouse=/tmp/arctic/,uri=https://nessie.dremio.cloud/v1/repositories/d74738b9-2855-4110-92b4-ad0ceae2ab80,ref=main \ --identifiers db1.personal \ --stacktrace
If we now check the catalog_migration.log file now, we should see the details of the error (--stacktrace parameter in the command increases verbosity)
Catalog_migration.log
2023-05-09 19:55:20,254 [main] ERROR o.p.t.c.m.api.CatalogMigrator - Unable to register the table db1.personal : Unauthorized (HTTP/401):
org.apache.iceberg.shaded.com.fasterxml.jackson.databind.exc.MismatchedInputException: Cannot deserialize value of type `org.projectnessie.error.ImmutableNessieError` from [Unavailable value] (token `JsonToken.NOT_AVAILABLE`)
at [Source: UNKNOWN; byte offset: #UNKNOWN]This implies that we have no access to the target Arctic catalog. The reason for that is because we haven’t passed the personal access token for Dremio Arctic in the command. Additionally, any table-level failures are logged in the failed_identifiers.txt file. Users can use this file to identify failed tables and search for them in the main log file. Having access to the logs can be extremely beneficial for debugging errors like this.
Conclusion
The iceberg-catalog-migrator tool provides an easy and quick way to migrate Iceberg tables stored in one catalog to another. In this blog, we introduced the tool and went over a few common scenarios where the migration tool can be beneficial and how to practically run such migrations. The tool is part of the Nessie project, so if you want to learn more or contribute, here is the repo.
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->