10 minute read · December 19, 2024
Hadoop Modernization on AWS with Dremio: The Path to Faster, Scalable, and Cost-Efficient Data Analytics
· Principal Product Marketing Manager

As businesses generate increasing volumes of data, the need for efficient, flexible, and cost-effective data management solutions has never been greater. Legacy Hadoop environments, though groundbreaking when first introduced, often struggle to keep up with the demands of modern data and analytic workloads. From high costs associated with licensing to the complexity of managing Hadoop clusters, these challenges have driven many organizations to seek new solutions. AWS and Dremio offer a powerful pathway for Hadoop modernization, enabling businesses to achieve seamless data access, enhanced performance, and significant cost savings.
In this blog, we’ll explore how Dremio, combined with AWS services like Amazon S3 and AWS Direct Connect, facilitates the transition from Hadoop to a modern data lakehouse architecture, supporting flexible and scalable analytics without the limitations of traditional Hadoop environments.
Why Modernize Hadoop on AWS?
For organizations relying on Hadoop to manage and process data, modernization is about more than just keeping up with the latest technology trends. It’s about enhancing data accessibility, reducing IT dependency, and enabling a more agile data strategy. Here are a few key drivers behind Hadoop modernization:
- Cost Reduction: Maintaining Hadoop infrastructure can be costly. Organizations need to invest in expensive hardware, manage high operational costs, and navigate limited scalability.
- Scalability and Flexibility: Hadoop clusters have scalability limitations and require substantial effort for upgrades and expansions.
- Enhanced Performance and Accessibility: Modernization helps eliminate data silos, enabling faster and easier access to data across the organization.
- Reduced IT Dependence: By enabling business users to access and analyze data independently, modernization minimizes reliance on IT teams, freeing them to focus on higher-value tasks.
By moving to a modern Dremio/AWS hybrid lakehouse environment based on Apache Iceberg, businesses can migrate from Hadoop to a more flexible, cloud-based architecture that supports these goals.
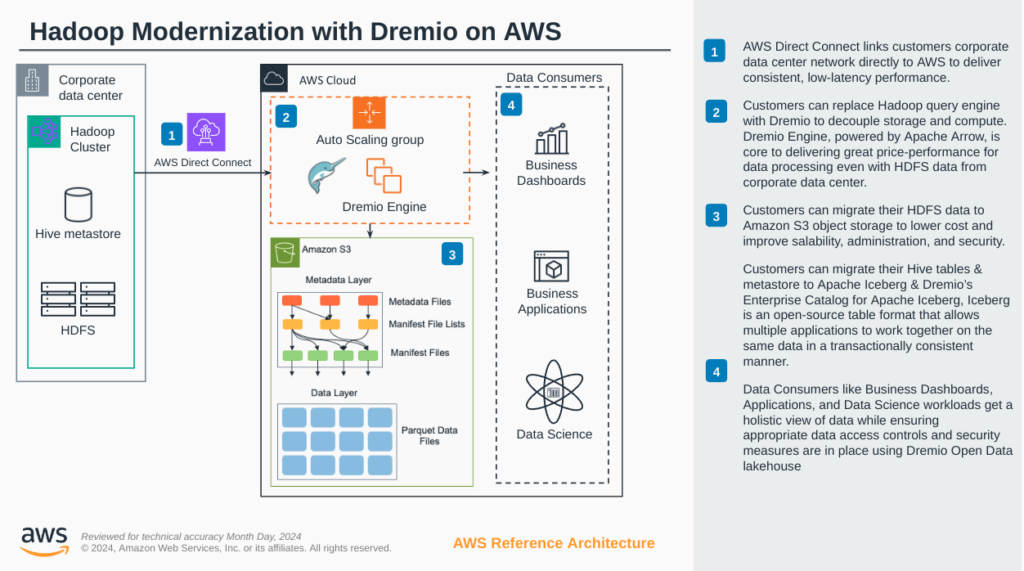
Step 1: Leveraging AWS Direct Connect for Low-Latency Data Access
One of the foundational elements of modernizing Hadoop on AWS is ensuring that data access remains fast and reliable. AWS Direct Connect provides a direct, dedicated connection from a customer’s on-premises data center to AWS, which is crucial for consistent, low-latency performance. This is particularly important for organizations with a large amount of HDFS data that they want to connect or and/or move to the cloud.
By using AWS Direct Connect, businesses can seamlessly integrate their on-premises data with AWS cloud services without compromising performance. This reliable connectivity improves data access speeds and lays the groundwork for efficient data migration and real-time analytics.
Step 2: Decoupling Storage and Compute with Dremio
Traditional Hadoop environments tightly couple storage and compute, meaning that scaling one often requires scaling the other. This model can lead to inefficiencies and high costs. Dremio addresses this by allowing organizations to decouple their storage and compute. By leveraging Dremio with AWS server instances and S3 storage, organizations can separate compute and storage in their new hybrid lakehouse environment. Decoupling storage and compute allows businesses to optimize resource allocation based on workload needs, reducing costs and improving performance.
Dremio’s query engine, with its unified analytics capabilities, offers a bridge between the organizations' legacy Hadoop environment and its new modern hybrid lakehouse in AWS. Dremio offers robust performance for processing existing data in HDFS and data as it moves to the new AWS cloud environment. By replacing a legacy Hadoop query engine like Hive, Impala or Drill with Dremio, organizations gain a more flexible, scalable solution that can act as a seamless bridge between legacy and the new modern iceberg lakehouse, while providing excellent price-performance for data processing.
Step 3: Migrating HDFS Data to Amazon S3
Another step in Hadoop modernization is migrating HDFS data to Amazon S3. S3 offers a highly scalable, durable, and secure object storage solution ideal for handling large volumes of data. By transferring data from HDFS to S3, businesses can lower storage costs, improve data scalability, and benefit from enhanced data security and ease of administration.
Amazon S3 also supports native integration with many AWS services, making it easier for data to be accessed, analyzed, and transformed as needed. Dremio’s ability to seamlessly query data in S3 further enhances the value of this migration, enabling data consumers to analyze data stored in S3 without requiring complex ETL processes.
With data in Amazon S3, companies can achieve a more flexible and agile data architecture that supports both current and future analytics needs.
Step 4: Transitioning from Hive to Apache Iceberg
Migrating the Hive table format to Apache Iceberg is crucial in modernizing a Hadoop environment. Apache Iceberg is an open-source table format that brings powerful features for data management, including versioning, schema evolution, and time travel. It allows multiple applications to work together on the same data transactionally consistently.
By transitioning to Iceberg, businesses can handle large datasets more effectively. Iceberg supports high-performance query execution while simplifying data management across multiple sources. Dremio’s native support for Iceberg enables seamless integration with this modern table format, allowing data teams to manage, access, and analyze data flexibly and consistently.
Dremio’s Enterprise Catalog for Apache Iceberg, included in the Dremio solution, provides advanced data lakehouse management capabilities to support large-scale datasets for high-performance analytics and business intelligence. The catalog streamlines numerous tedious lakehouse management tasks that companies previously managed manually in Hadoop. Dremio’s Enterprise Catalog simplifies and enhances data management, optimizing query performance and reducing storage costs by automating data management by automating compaction and table clean-up.
Step 5: Enabling Self-Service Analytics with Dremio Hybrid Lakehouse
One of the most significant benefits of Hadoop modernization on AWS with Dremio is the shift to a self-service analytics model. The Dremio Hybrid Lakehouse for the Business provides business users, data scientists, and application teams with a holistic view of data across the organization, empowering them to derive insights independently. This model reduces dependency on IT, allowing teams to focus on analysis and decision-making rather than waiting for data access and preparation.
Dremio’s Hybrid Lakehouse supports secure data access controls, ensuring that appropriate governance and compliance measures are in place. Through a robust semantic layer, business dashboards, applications, and data science workloads can access a unified view of data across the lakehouse, fostering data democratization while maintaining security and control.
The Benefits of Hadoop Modernization on AWS with Dremio
Modernizing a Hadoop environment on AWS with Dremio offers a range of benefits for organizations looking to enhance their data infrastructure:
- Reduced Costs: Migrating data to Amazon S3 and decoupling storage and compute significantly lowers infrastructure costs compared to maintaining on-premises Hadoop clusters.
- Improved Performance: Dremio’s high-performance query engine, powered by Apache Arrow, ensures fast query execution, even with large datasets.
- Scalability and Flexibility: With data in Amazon S3 and workloads managed through Dremio, organizations can scale resources up or down based on demand, avoiding the rigid scaling limitations of traditional Hadoop environments.
- Enhanced Data Access and Self-Service: Dremio’s Hybrid Lakehouse empowers business users and data teams to access data directly, minimizing dependence on IT for data access and preparation.
- Advanced Data Management with Apache Iceberg: By migrating from Hive to Iceberg, and the Hive Metastore to Dremio’s Enterprise Catalog for Apache Iceberg businesses can leverage and manage a modern table format that supports versioning and transactionally consistent data access across application
Unlocking the Full Potential of Your Data with Dremio and AWS
Hadoop modernization on AWS with Dremio represents a significant leap forward for organizations looking to leverage their data more effectively. By migrating to a cloud-native architecture, decoupling storage and compute, and enabling self-service data access, businesses can unlock the full potential of their data while minimizing costs and operational complexity.
With AWS and Dremio, organizations can leave behind the limitations of Hadoop and embrace a modern data lakehouse approach that supports agile, data-driven decision-making across the enterprise. From reducing costs to empowering business teams with direct data access, the path to modernization is clear—and the benefits are compelling. Ready to explore Hadoop modernization with Dremio on AWS? Book a meeting with us to discuss
Additional Resources

BLOG
Enhancing your Snowflake Data Warehouse with the Dremio Lakehouse Platform
Integrating Snowflake with the Dremio Lakehouse Platform offers a powerful combination that addresses some of the most pressing challenges in data management today. By unifying siloed data, optimizing analytics costs, enabling self-service capabilities, and avoiding vendor lock-in, Dremio complements and extends the value of your Snowflake data warehouse.
Dremio Blog: Partnerships Unveiled,
Learn More ->

BLOG
Why Modernize Your Hadoop Data Lake with Dremio and MinIO?
Modernizing a Hadoop data lake with Dremio and MinIO brings substantial advantages to organizations seeking to enhance their data infrastructure. This transformation not only resolves the performance, scalability, and cost challenges associated with traditional Hadoop environments but also empowers businesses to achieve greater agility and efficiency. By leveraging Dremio's advanced analytics capabilities and MinIO's scalable storage, companies can modernize their data lakes to meet the demands of today's fast-paced, data-driven world. The result is a robust, flexible, and cost-effective data environment that accelerates time to market and drives business innovation.
Dremio Blog: Partnerships Unveiled,
Learn More ->

BLOG
Privacera integration with Dremio: A Seamless Data Governance Solution
Dremio Blog: Partnerships Unveiled,
Learn More ->