9 minute read · August 8, 2022
Problems with Monolithic Data Architectures & Why Data Mesh Is a Solution
· Developer Advocate, Dremio

Over the past few years, more and more enterprises have wanted to democratize their data to make it more accessible and usable for critical business decision-making throughout the entire organization. This created a significant focus on making data centrally available and led to the popularization of monolithic data architectures.
In theory, with monolithic data architectures like data warehouses and data lakes, storing and serving an organization's vast amount of operational data in one centralized location would enable various data consumers to use it for a wide range of analytical use cases, while ensuring the data is clean, correct, and formatted properly. However, in reality, this is not always the case.
While centralization strategies have bestowed initial success for organizations that generate data at a smaller scale with fairly fewer data consumers, with the increase of data sources and consumers, it can quickly fail.
For a large enterprise, a monolithic data architecture can have serious consequences. Data consumers get frustrated because they don't have a self-service experience to analyze data, and need to work with data engineers if they want to create new views of their data. In addition, data engineers need to maintain complex ETL pipelines, while tackling a lengthy backlog of data access requests from data consumers.
For example, let’s say a company wants to build some dashboards to understand the historical trends in the sale of their product. To do so with a monolithic data architecture, they would have to first move their day-to-day sales operational data to a centralized repository via a tedious ETL/ELT process that requires specialized data engineers’ expertise. This further impacts the wait time on the part of a data consumer, such as a data analyst, to build the reports based on the analytical data they requested.
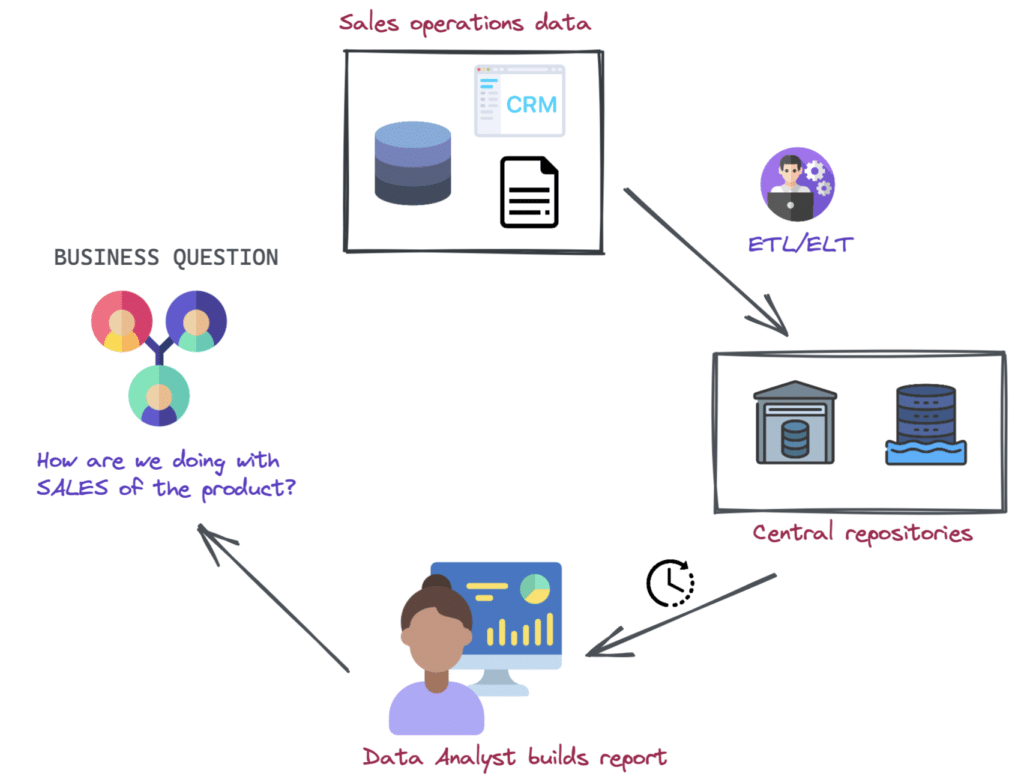
Enterprises today will commonly use data warehouses or data lakes to store their data in one central location but this leads to organizations becoming overly reliant on centralized data engineering teams to manage complex data pipelines and make data available for all the business units in an organization, which often leads to issues.
Some of the main challenges with a monolithic data architecture are listed below.
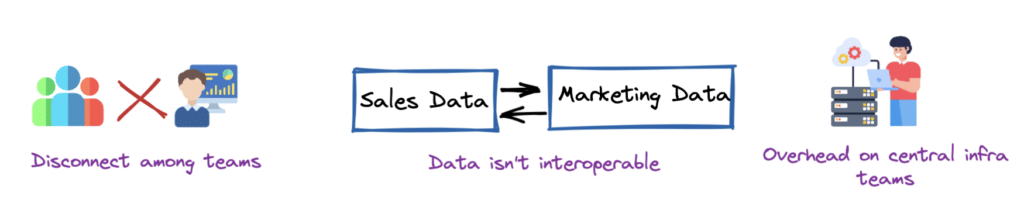
1. Teams Can Easily Lose Business Context
- It’s difficult for data teams (engineers, consumers) to acquire the domain knowledge that a business unit possesses.
- The “disconnect” ultimately makes data distant from the business domains and leads to data consumers being unaware of the actual meaning of the data.
- For example, a data engineer’s focus is to make data available to its consumers for various analytical needs. However, since engineers today have no ownership of the data and are disconnected from the source domain, they have much less understanding of what the data actually means in a business context. Hence, they are left just to move the data and do transformations based on the business need.
2. Data Isn’t Interoperable
- With the current approach, there is limited focus on making the data usable by other units within the organization. This could also lead to various data teams duplicating their efforts.
- For example, your “customer operations” team generates product usage data. But a data scientist working in the “product” team has no way to use the generated data and will need to curate and build their dataset, increasing cost and potentially resulting in the two teams obtaining different results, a nightmare for decision-making.
3. Data Engineers & Consumers Are Bottlenecked
- The infrastructure team primarily consists of data engineers. Data consumers rely on data engineers to make the data available to them from a centralized source such as a warehouse or lake. However, the rate at which data is generated only increases as you mature and scale as an organization.
- With the increase in data production, businesses would like to leverage the data to make analytical decisions. Therefore, the number of data consumers also increases. This impacts the overall central infrastructure teams, who are expected to support this ever-increasing number of producers and consumers via the platform.
All of the above challenges have a common theme — these are not technical challenges but organizational. There needs to be a paradigm shift — having an efficient strategy to manage and use data while bridging the gap between data producers and consumers is paramount for today’s enterprises. This is where data mesh comes in.
The Data Mesh Solution
Data mesh is a decentralized approach to data architecture that focuses on domain ownership, treating data as a product, self-service analytics, and federated computational governance. This new approach was created in response to the challenges of monolithic data architectures.
Since each domain owns its data from start to finish with a data mesh, data consumers no longer have to go through the bottleneck of a single, central data warehouse or data lake. This results in easier and faster access to data, more flexibility, and business agility.
A data mesh is generally best suited for larger enterprises that have a high number of data sources and domains. For smaller and mid-sized organizations, a monolithic data architecture could still work since there are fewer domains. As an enterprise gets bigger and bigger, this is when a monolithic data architecture starts to break down and a data mesh is needed.
A good comparison is looking at software engineering. Applications used to be built using a monolithic approach. This would be fine for a small application but once you started working on a large application, it would get exponentially harder to understand and make changes as the product scaled. To overcome these complexities, software engineers began to decompose applications into a set of smaller, independently deployable services called microservices, which could be managed, scaled, and maintained more easily. The same principle is true for data mesh.
Like microservices in software engineering, data mesh advocates for individual domains to host data and efficiently make their data available for consumption. So, in a way, shared data products bring to data architectures what APIs brought to a microservices architecture.
Conclusion
Monolithic data architecture was created so everyone could have central data access. However, in practice, this approach quickly creates problems for growing organizations. Data consumers become overly dependent on a centralized team of data engineers to get access to data which can lead to delays and additionally creates a disconnect from the data producers. At the same time, a lot of pressure is put on data engineers to manage a wide range of complex data pipelines for the whole organization, which can lead to issues.
An organizational mindset change to effectively manage and democratize data isn’t something you develop in a brief period of time. It requires a significant effort from the management, and every stakeholder has to be on the same page to embrace a culture of federated ownership. A data mesh approach can help deal with the issues seen with centralized data architectures, but it can be challenging to implement. In fact, there is no templated strategy to implement data mesh that is company-agnostic.
Organizations should look at how they can evolve this strategy over time to adhere to their requirements. Learn how you can use Dremio’s open lakehouse platform to implement a data mesh.
Learn More
Ready to Learn More?
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->