17 minute read · May 13, 2024
From JSON, CSV and Parquet to Dashboards with Apache Iceberg and Dremio
· Senior Tech Evangelist, Dremio

In an ideal world, all our data would seamlessly flow into Apache Iceberg tables in our data lake, which would be perfectly organized and ready for analysis. However, the reality is often more complex. We frequently encounter scenarios where systems and partners deliver data in formats like JSON, CSV, and Parquet. This diversity can pose challenges for ingestion and subsequent analysis. Fortunately, Dremio's `COPY INTO` command, and the soon-to-be-released Auto Ingest feature provide robust solutions for importing these files into Apache Iceberg tables. By leveraging Dremio, ingesting and maintaining data in Apache Iceberg becomes manageable and efficient, paving the way for performant and flexible analytics directly from your data lake. In this article, we’ll do a hand-on exercise you can do in the safety of your local environment to see these techniques at work.
Setup
Repo with Setup for This Exercise
Fork and Clone the GitHub repo above to your local environment to have everything you need to do this exercise. Also, install Docker to spin up all the required services with Docker Compose. If you ever run into “137” errors, you may need to allocate more memory to Docker for containers, which can be changed from the Docker UI settings. In this repo, you will find the following files:
├── docker-compose.yml ├── readme.md └── sampledata ├── 90s_tv_shows.csv ├── csv_dataset │ ├── 1.csv │ └── 2.csv ├── json_dataset │ ├── 1.json │ └── 2.json ├── parquet_dataset │ ├── airport_lookup.csv │ ├── carrier_lookup.csv │ ├── flight_parquet │ │ ├── part-00000-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00001-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00002-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00003-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00004-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00005-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00006-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00007-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00008-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00009-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00010-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00011-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00012-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00013-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00014-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00015-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00016-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00017-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00018-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00019-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00020-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00021-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00022-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ ├── part-00023-aefaf364-d401-4e57-92a5-82fae6fdc855-c000.snappy.parquet │ │ └── _SUCCESS │ └── MapReduce Peer Review-1.png └── pokedex.json
A few things to point out:
- The docker-compose.yml details the setup of our environment, which includes Dremio as our Lakehouse Platform, Minio as our Data Lake and Nessie as our Lakehouse catalog for tracking Apache Iceberg tables.
- The sampledata folder is set up so that when Minio starts up this folder will be added to a “sampledata” bucket.
To start up our environment, we can just run the command in the same folder as the docker-compose.yml
docker compose up -d
This will run all the services in our docker compose file in the background. These can be shut off at any time with the command “docker compose down.” When it is done spinning up, the following should be true:
- You can access the Minio dashboard at localhost:9001 in your browser with the username of admin and the password of password
- You can setup your Dremio user with the username and password of your choosing by visiting localhost:9047 in your browser.
Connecting Your Data Sources
We want to setup two sources now that we are in Dremio:
- A Nessie source so we can create Apache Iceberg tables
- An S3 source configured to our Minio sampledata bucket to access our sampledata
Nessie
Click on “add source” in the bottom left and select Nessie.
There are two sections we need to fill out, the general and storage sections:
General (Connecting to Nessie Server)
- Set the name of the source to “nessie”
- Set the endpoint URL to “http://nessie:19120/api/v2”
- Set the authentication to “none”
Storage Settings
- For your access key, set “admin” (minio username)
- For your secret key, set “password” (minio password)
- Set root path to “warehouse” (any bucket you have access too)
- Set the following connection properties:
- `fs.s3a.path.style.access` to `true`
- `fs.s3a.endpoint` to `minio:9000`
- `dremio.s3.compat` to `true`
- Uncheck “encrypt connection” (since our local Nessie instance is running on http)
SampleData
Click on “add source” and select S3
GENERAL SETTINGS
- name: sampledata
- credentials: aws access key
- accesskey: admin
- secretkey: password
- encrypt connection: false
ADVANCED OPTIONS
- enable compatibility mode: true
- root path: /sampledata
- Connection Properties
- fs.s3a.path.style.access = true
- fs.s3a.endpoint = minio:9000
Once this is all set you should be able to see the following.
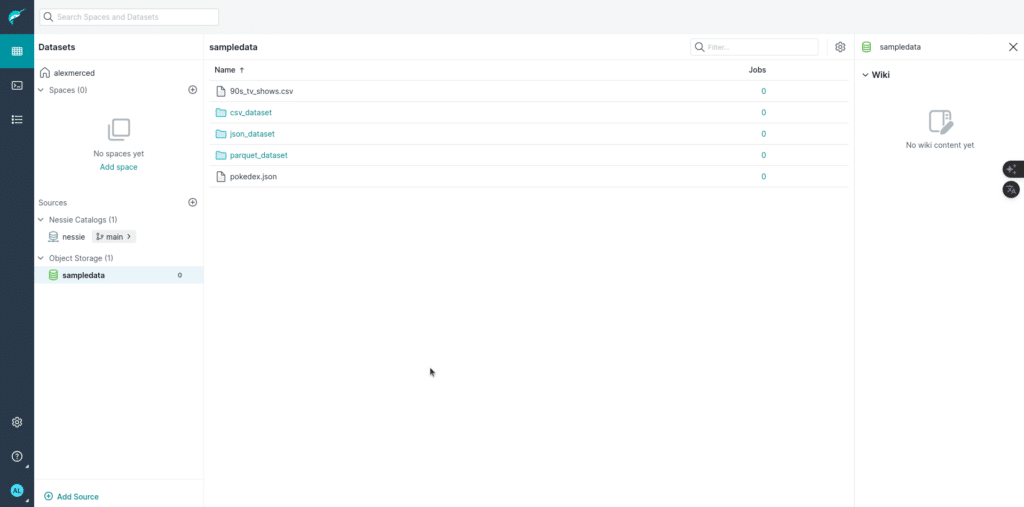
Creating Our Destination Tables
With Dremio, executing analytics directly on CSV, JSON, and Parquet files stored in object storage is feasible. However, as the scale of data operations grows, several compelling benefits emerge from transitioning this data into Apache Iceberg tables:
- Portability Across Tools: Once data is in Apache Iceberg, it becomes accessible to any tool that can interact with your Apache Iceberg catalog. This flexibility allows for broader integration across different platforms and tools within your data ecosystem.
- Efficient Data Management: Dremio can more effectively access the latest version of your data, as metadata is immediately updated upon write operations. This efficiency ensures that analytics are always performed on the most current dataset.
- Data Time Travel: Apache Iceberg supports time travel capabilities, allowing users to query and analyze historical versions of data. This feature is invaluable for auditing changes, understanding data evolution, and rolling back to previous data states if necessary.
- Branching and Isolation with Nessie: Integrating Nessie, a "Git for data" solution, with your Apache Iceberg tables, enables sophisticated data change management and isolation. This setup allows you to validate changes in isolated environments before merging and making them visible to other users or processes. This approach enhances data integrity and testing before deployment.
By leveraging Apache Iceberg in conjunction with Dremio, you gain scalability and performance improvements and enhance your data governance and version control capabilities, significantly boosting the robustness of your data architecture.
In the past, to do this, we’d have to promote our files into datasets within Dremio, which, depending on the filetype, may not have the desired schema requiring us to do some preparation before ingesting into Apache Iceberg. With the COPY INTO command, we can just direct Dremio to the location of the data. Dremio will add the data to the Apache Iceberg table and enforce the table’s schema on the incoming data, making this process much more manageable. We can already orchestrate Dremio by sending Dremio SQL via it’s REST API, JDBC/ODBC or Apache Arrow flight using Orchestration tools like Airflow. Still, soon Dremio will be adding an auto-ingest feature that will allow us to trigger ingestion when new files appear on your object storage allowing for immediate action as data comes in.
So let’s create the Apache Iceberg tables that our sample data will need with the following SQL.
-- Table for the CSV dataset CREATE TABLE nessie.csv_dataset (id INT, first_name VARCHAR, last_name VARCHAR, email VARCHAR); -- Table for the JSON dataset CREATE TABLE nessie.json_dataset (id INT, first_name VARCHAR, last_name VARCHAR, email VARCHAR, age INT); -- Table for the Parquet Dataset (Not every column) CREATE TABLE nessie.flights ( "Year" INT, Quarter INT, "Month" INT, DayodMonth INT, DayOfWeek INT, FlightDate DATE, Reporting_Airline VARCHAR, DOT_ID_REPORTING_AIRLINE INT, IATA_CODE_Reporting_Airline VARCHAR, Tail_Number VARCHAR, Flight_Number_Reporting_Airline INT, OriginAirportID INT );
Run these queries, which will create these tables which should also be visible in the “warehouse” bucket in minio.
Ingesting Our Data into Those Tables
Next, we will create a branch in our catalog to isolate all our new records before publishing them.
-- Create a Branch CREATE BRANCH ingest IN nessie;
Then we can use the COPY INTO command to copy the data from all the different files into our tables:
-- RUN FOLLOW QUERIES IN BRANCH USE BRANCH ingest IN nessie; -- Ingest Data from CSV Files COPY INTO nessie."csv_dataset" FROM '@sampledata/csv_dataset/' FILE_FORMAT 'csv'; -- Ingest Data from JSON Files COPY INTO nessie."json_dataset" FROM '@sampledata/json_dataset/' FILE_FORMAT 'json'; -- Ingest Data from Parquet Files COPY INTO nessie.flights FROM '@sampledata/parquet_dataset/flight_parquet/' FILE_FORMAT 'parquet';
To verify the data changes have been isolated to our branch let’s run the following queries:
SELECT * FROM nessie."csv_dataset" AT BRANCH "main"; SELECT * FROM nessie."csv_dataset" AT BRANCH "ingest"; SELECT * FROM nessie."json_dataset" AT BRANCH "main"; SELECT * FROM nessie."json_dataset" AT BRANCH "ingest"; SELECT * FROM nessie.flights AT BRANCH "main"; SELECT * FROM nessie.flights AT BRANCH "ingest";
By inspecting the results, you’ll see that the new data is only visible when querying the branch. This allows us the peace of mind to know production queries aren’t seeing this data before we can inspect and validate it. After running our desired validations, we can publish those changes with a merge.
MERGE BRANCH ingest INTO main IN nessie;
Now if we go back and run those previous queries, we’ll see all the data is available on both branches, the data is now available in production for our consumers to train AI models and build BI dashboards with.
Building Our BI Dashboards
Dremio can be used with most existing BI tools, with one-click integrations in the user interface for tools like Tableau and Power BI. We will use an open-source option in Apache Superset for this exercise, but any BI tool would have a similar experience. We then need to initialize Superset, so open another terminal and run this command:
docker exec -it superset superset init
This may take a few minutes to finish initializing, but once it is done, you can head over to localhost:8088 and log in to Superset with the username “admin” and password “admin”. Once you are in, click on “Settings” and select “Database Connections”.
- Add a New Database
- Select “Other”
- Use the following connection string (make sure to include Dremio username and password in URL): dremio+flight://USERNAME:PASSWORD@dremio:32010/?UseEncryption=false
- Test connection
- Save connection
The next step is to add a dataset by clicking on the + icon in the upper right corner and selecting “create dataset”. From here, select the table you want to add to Superset, which is, in this case, either csv, json or parquet datasets we ingested into Apache Iceberg.
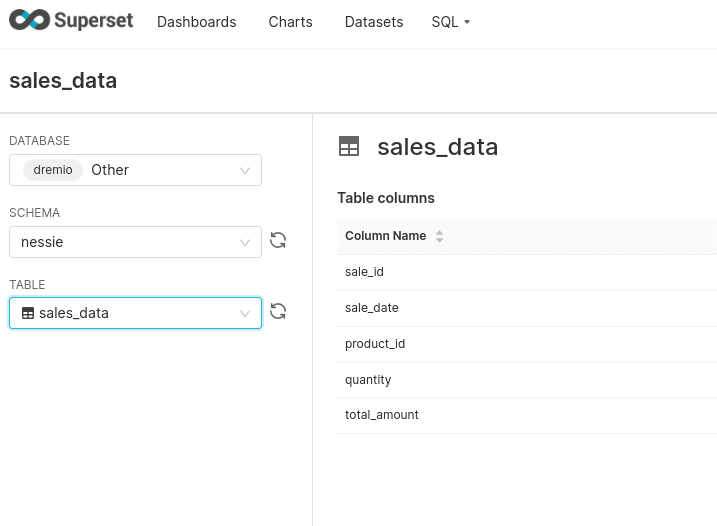
We can then click the + to add charts based on the datasets we’ve added. Once we create the charts we want, we can add them to a dashboard, and that’s it! You’ve now taken data from an operational database, ingested it into your data lake, and served a BI dashboard using the data.
Consider deploying Dremio into production to make delivering data for analytics easier for your data engineering team.
Sign up for AI Ready Data content
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Dremio Blog: Product Insights,
Learn More ->

BLOG
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.
Dremio Blog: Product Insights,
Learn More ->

BLOG
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights, Dremio Blog: Product Insights,
Learn More ->