15 minute read · September 22, 2023
Exploring the Architecture of Apache Iceberg, Delta Lake, and Apache Hudi
· Senior Tech Evangelist, Dremio

In the age of data-centric applications, storing, accessing, and managing data can significantly influence an organization's ability to derive value from a data lakehouse. At the heart of this conversation are data lakehouse table formats, which are metadata layers that allow tools to interact with data lake storage like a traditional database. But why do these formats matter? The answer lies in performance, efficiency, and ease of data operations. This blog post will help make the architecture of Apache Iceberg, Delta Lake, and Apache Hudi more accessible to better understand the high-level differences in their respective approaches to providing the lakehouse metadata layer.
The metadata layer these formats provide contains the details that query engines can use to plan efficient data operations. You can think of this metadata as serving a similar role to the Dewey Decimal System in a library. The Dewey Decimal System serves as an abstraction to help readers more quickly find the books they want to read without having to walk up and down the entire library. In the same manner, a table format’s metadata makes it possible for query engines to not have to scan every data file in a dataset.
If you haven’t already read our content that compares these formats, here are some links to help get you acquainted:
- Presentation About Table Formats
- General Comparison of Table Formats
- Comparison of Community and Ecosystem of Table Formats
- Comparison of Partitioning Features of Table Formats
Apache Iceberg
Originating out of Netflix and then becoming a community run Apache project, Apache Iceberg provides a data lakehouse metadata layer that many vendors support. It works off a three-tier metadata layer.
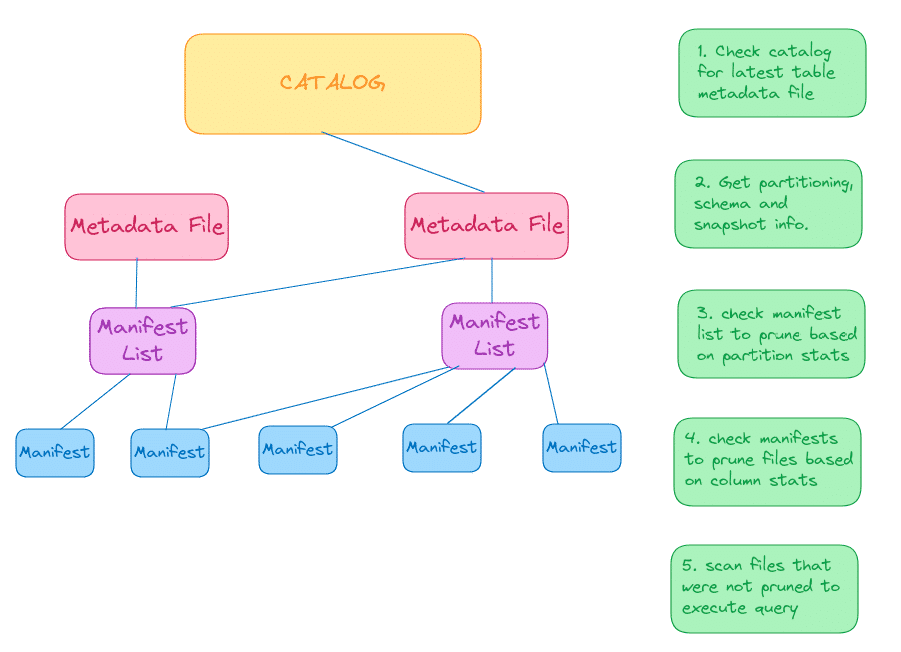
Let’s examine the three tiers.
Metadata Files
At the heart of Apache Iceberg’s metadata is the metadata.json, which defines all the table-level information such as the tables schema, partitioning scheme, current snapshot along with a historical list of schemas, partition schemes, and snapshots.
{
"format-version": 2,
"table-uuid": "f47ac10b-58cc-4372-a567-0e02b2c3d479",
"location": "/data/animals/",
"last-sequence-number": 1002,
"last-updated-ms": 1677619248000,
"last-column-id": 3,
"schemas": [
{
"schema-id": 1,
"fields": [
{
"id": 1,
"name": "id",
"type": "int"
},
{
"id": 2,
"name": "category",
"type": "string"
},
{
"id": 3,
"name": "name",
"type": "string"
}
]
}
],
"current-schema-id": 1,
"partition-specs": [
{
"spec-id": 1,
"fields": [
{
"source-id": 2,
"transform": "identity",
"field-id": 1001
}
]
}
],
"default-spec-id": 1,
"last-partition-id": 1001,
"sort-orders": [
{
"order-id": 1,
"fields": [
{
"source-id": 1,
"direction": "asc",
"null-order": "nulls-first"
}
]
}
],
"default-sort-order-id": 1
}Manifest Lists
Each snapshot listed in the metadata.json points to a “Manifest List” which lists all file manifests that make up that particular snapshot along with manifest-level stats that can be used to filter manifests based on things like partition values.
{
"manifests": [
{
"manifest_path": "s3://bucket/path/to/manifest1.avro",
"manifest_length": 1024,
"partition_spec_id": 1,
"content": 0,
"sequence_number": 1000,
"min_sequence_number": 999,
"added_snapshot_id": 12345,
"added_files_count": 10,
"existing_files_count": 8,
"deleted_files_count": 2,
"added_rows_count": 100,
"existing_rows_count": 80,
"deleted_rows_count": 20,
"partitions": [
{
"contains_null": false,
"lower_bound": "encoded_value",
"upper_bound": "encoded_value"
},
{
"contains_null": true,
"contains_nan": false,
"lower_bound": "another_encoded_value",
"upper_bound": "another_encoded_value"
}
]
},
{
"manifest_path": "s3://bucket/path/to/manifest2.avro",
"manifest_length": 2048,
"partition_spec_id": 2,
"content": 1,
"sequence_number": 1001,
"min_sequence_number": 1000,
"added_snapshot_id": 12346,
"added_files_count": 5,
"existing_files_count": 7,
"deleted_files_count": 3,
"added_rows_count": 50,
"existing_rows_count": 70,
"deleted_rows_count": 30,
"partitions": [
{
"contains_null": false,
"lower_bound": "yet_another_encoded_value",
"upper_bound": "yet_another_encoded_value"
}
]
}
]
}Manifests
Each file manifest that is listed on the snapshot “Manifest List” has a listing of the individual files that contain data along with stats on each file to help skip data files based on each file's column stats.
{
"metadata": {
"schema": "{\"type\":\"record\",\"name\":\"table_schema\",\"fields\":[{\"name\":\"id\",\"type\":\"long\"},{\"name\":\"name\",\"type\":\"string\"},{\"name\":\"age\",\"type\":\"int\"}]}",
"schema-id": "1",
"partition-spec": "{\"fields\":[{\"name\":\"age\",\"transform\":\"identity\",\"fieldId\":1,\"sourceId\":1}]}",
"partition-spec-id": "1",
"format-version": "2",
"content": "data"
},
"entries": [
{
"status": 1,
"snapshot_id": 101,
"data_file": {
"content": 0,
"file_path": "s3://mybucket/data/datafile1.parquet",
"file_format": "parquet",
"partition": {
"age": 30
},
"record_count": 5000,
"file_size_in_bytes": 1000000,
"column_sizes": {
"1": 200000,
"2": 300000,
"3": 500000
},
"value_counts": {
"1": 5000,
"2": 4500,
"3": 4000
},
"null_value_counts": {
"1": 0,
"2": 500,
"3": 1000
}
}
},
{
"status": 1,
"snapshot_id": 102,
"data_file": {
"content": 0,
"file_path": "s3://mybucket/data/datafile2.parquet",
"file_format": "parquet",
"partition": {
"age": 40
},
"record_count": 6000,
"file_size_in_bytes": 1200000,
"column_sizes": {
"1": 240000,
"2": 360000,
"3": 600000
},
"value_counts": {
"1": 6000,
"2": 5400,
"3": 4800
},
"null_value_counts": {
"1": 0,
"2": 600,
"3": 1200
}
}
}
]
}Delta Lake
Developed by Databricks, Delta Lake provides a data lakehouse metadata layer that benefits from many features primarily available on the Databricks platform, along with those built into its own specification. Two types of files handle most of the work with Delta Lake: log files and checkpoint files.
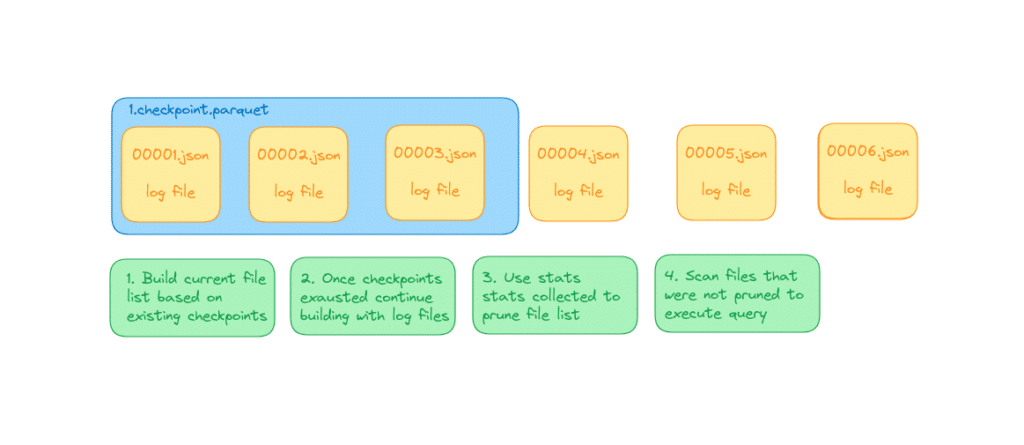
Delta Logs
Delta Logs are very similar to Git commits mechanically. In Git, each commit captures the lines of code that are added and removed since the last commit, whereas Delta Logs capture files added and removed from the table since the last commit.
For instance, a diary page (00000000000000000001.json) might read:
{
"protocol": {
"minReaderVersion": 1,
"minWriterVersion": 2
},
"commitInfo": {
"timestamp": 1629292910020,
"operation": "WRITE",
"operationParameters": {
"mode": "Overwrite",
"partitionBy": "['date']"
},
"isBlindAppend": false
},
"add": {
"path": "data/partition=date/parquetfile.parquet",
"partitionValues": {
"date": "2023-08-18"
},
"modificationTime": 1629292910020,
"size": 84123
}
}Checkpoint Files
An engine can re-create the state of a table by going through each Delta Log file and constructing the list of files in the table. However, after many commits, this process can begin to introduce some latency. To deal with this, there are checkpoint files that summarize a group of log files so each individual log file doesn’t have to be read to construct the list of files in the dataset.
| path | partitionValues | modificationTime | size |
|---------------------------------------------|-----------------|--------------------|---------|
| data/partition=date1/parquetfile1.parquet | {date: date1} | 1629291000010 | 84123 |
| data/partition=date2/parquetfile2.parquet | {date: date2} | 1629291500020 | 76234 |
Apache Hudi
Apache Hudi is another table format that originated at Uber. Hudi’s approach revolves around capturing the timestamp and type of different operations and creating a timeline.
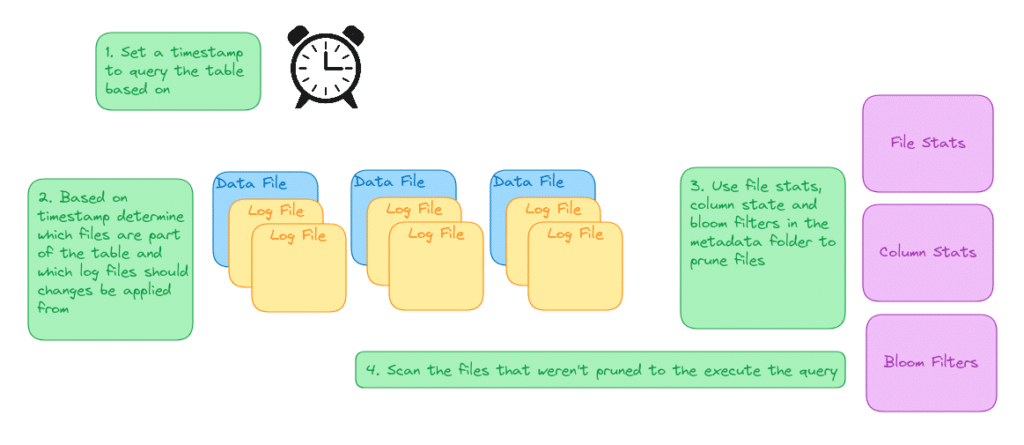
Directory Structure
Each Hudi table has several directories it uses to organize the metadata it uses to track the table.
- /voter_data/: This is the folder of the table that will house partition folders with data files and the.hoodie folder that houses all the metadata.
- /.hoodie/: This is the folder that holds all the table metadata tracking table properties and file metadata.
- /hoodie.properties: List of properties on how the table is structured.
- /metadata/: This is where the metadata is saved, including transactions, bloom filters, and more.
- /.hoodie/: This is the folder that holds all the table metadata tracking table properties and file metadata.
Hudi Metadata
The metadata folder in Hudi contains the metadata table which holds several indexes for improving transaction performance via data skipping and other optimizations.
- Files Index: Stores file details like name, size, and status.
- Column Stats Index: Contains statistics of specific columns, aiding in data skipping and speeding up queries.
- Bloom Filter Index: Houses bloom filters of data files for more efficient data lookups.
- Record Index: Maps record keys to locations for rapid retrieval, introduced in Hudi 0.14.0.
Hudi uses HFile, a format related to HBase, to maintain records of this metadata.
Base and Log Files: The Core Content
In Hudi’s world, there are two main types of data files:
- Base Files: These are the original data files written in Parquet or ORC.
- Log Files: These are files that track changes to the data in the base file to be reconciled on read.
Naming Conventions
The way Hudi names these files is:
- Base Files: It’s like [ID]_[Writing Version]_[Creation Time].[Type]
- Log Notes: More detailed as [Base File ID]_[Base Creation Time].[Note Type].[Note Version]_[Writing Version]
The Timeline Mechanics
Hudi loves order. Every action or change made to a table is recorded in a timeline, allowing you to see the entire history. This timeline also ensures that multiple changes don’t clash.
Actions on this timeline go through stages like:
- Planning (requested)
- Doing (inflight)
- Done (commit)
These steps are captured in the hoodie folder through files with the naming convention of [timestamp].[transaction state(requested/inflight/commit)], and this is how Hudi is able to identify and reconcile concurrent transactions. If two transactions come in at the same timestamp, one of the two transactions will see the pending transaction and adjust accordingly.
Hudi Table Fields
Each table comes with some additional fields that assists in Hudi’s data lookup:
- User Labels: These are the fields of the table the user specified when they created the table or updated the schema.
Hudi’s Own Labels: Fields created by Hudi to optimize operations which include _hoodie_commit_time, _hoodie_commit_seqno, _hoodie_record_key, _hoodie_partition_path, _hoodie_file_name.
Conclusion
| Apache Iceberg | Delta Lake | Apache Hudi | |
| Metadata Approach | 3-Tier Metadata Tree | Logs & Checkpoints | Timeline |
| Data Skipping | Based on Manifest and File Stats | File Stats from Log Files | Based on Column Stats Indexes in Metadata Table |
| File Types | Metadata.json, Manifest Lists, Manifests | Log Files and Checkpoints | Log Files, Metadata Table, Requested - Inflight - Commit Files |
Each format takes a very different approach to maintain metadata for enabling ACID transactions, time travel, and schema evolution in the data lakehouse. Hopefully, this helps you better understand the internal structures of these data lakehouse table formats.
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->