16 minute read · March 29, 2023
Exploring Branch & Tags in Apache Iceberg using Spark
· Developer Advocate, Dremio

Apache Iceberg 1.2.0 release brings in a range of exciting new features and bug fixes. The release centers around changes to the core Iceberg library, compute engines together with a couple of vendor integrations, making the ecosystem of tools and technologies around the ‘open’ table format extremely robust. Amongst some of the noteworthy features is the ability to create branches and tags for Iceberg tables.
TL;DR
The branching and tagging capabilities in Apache Iceberg have opened up exciting new use cases. In terms of the benefits, we
- can now work with data without making any additional copies (copies can be expensive at scale)
- now have the ability to isolate data work without impacting production workloads
- can decide to retain or discard these named references easily with DDL commands
Tags and Branches
The concept of tags and branches is well known in the world of software engineering, particularly with version control systems like Git. Developers create their isolated local branch to let’s say add a new feature or fix a bug, commit the necessary code changes, and then, after a code review, the branch is merged to the main, which makes those new features available in production. Similarly, tags in Git refer to a specific commit and can be immensely helpful when we want to point to a particular release. Iceberg’s new branching and tagging capability borrows similar concepts from Git and applies them to the data lake and lakehouse space. It enables data engineering teams to keep track of the state or version of an Iceberg table using named references. Let’s understand this in more detail.
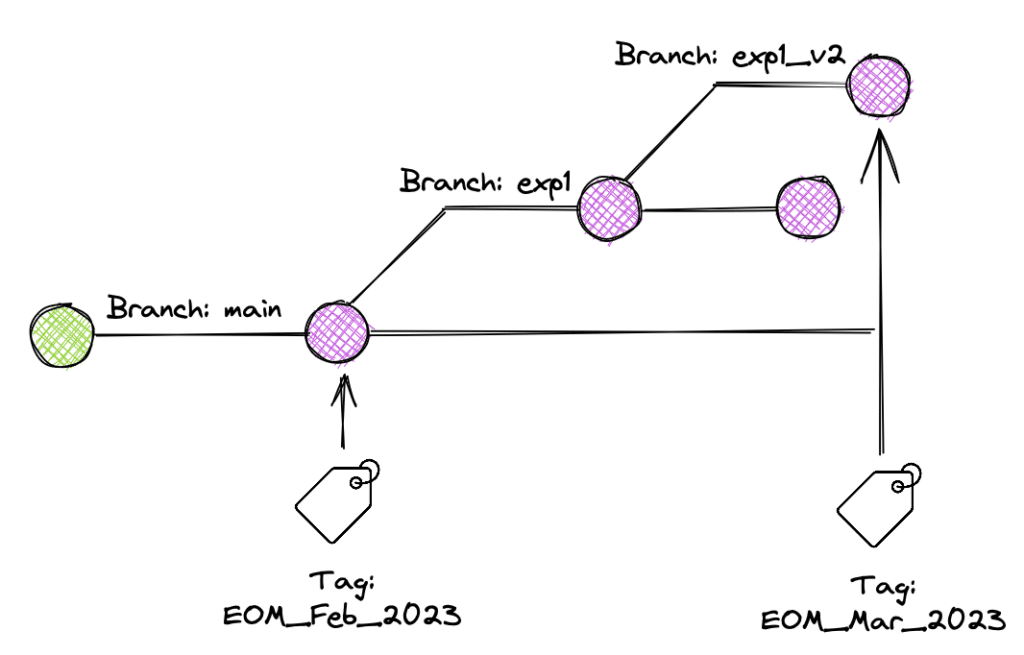
Figure-1: Branch & Tags in Apache Iceberg
Apache Iceberg maintains the state of a table at a certain point in time using a concept called snapshot. Now, everytime a write operation, such as UPDATE or DELETE, changes the current state of an Iceberg table, a new snapshot is created to track that version of the table and is then marked as the current snapshot. This ensures that readers always fetch the latest version of the table for the clients making a query request. Until now, the only available reference was the current-snapshot-id. However, with this new release, the references can now be extended to include tagging and branching of tables.
1. Iceberg Tags
1.1. What are Iceberg Tags?
Tags are immutable labels for individual snapshots, and they refer to a specific snapshot-id. For instance, let’s say you are working on an Iceberg table called employee which has data until the month of June, and you want to use this particular version of the table to train a machine learning model. This is a scenario where you can create a tag and refer to it later for your model training work. The syntax for creating a tag is shown below.
spark.sql("ALTER TABLE glue.test.employee CREATE TAG EOM_June_2023")After successful execution, Iceberg will create a named reference called EOM_June_2023 based on this version of the table. Any further changes to the main table (e.g. new data ingested) will not impact this specific version as this is maintained separately.
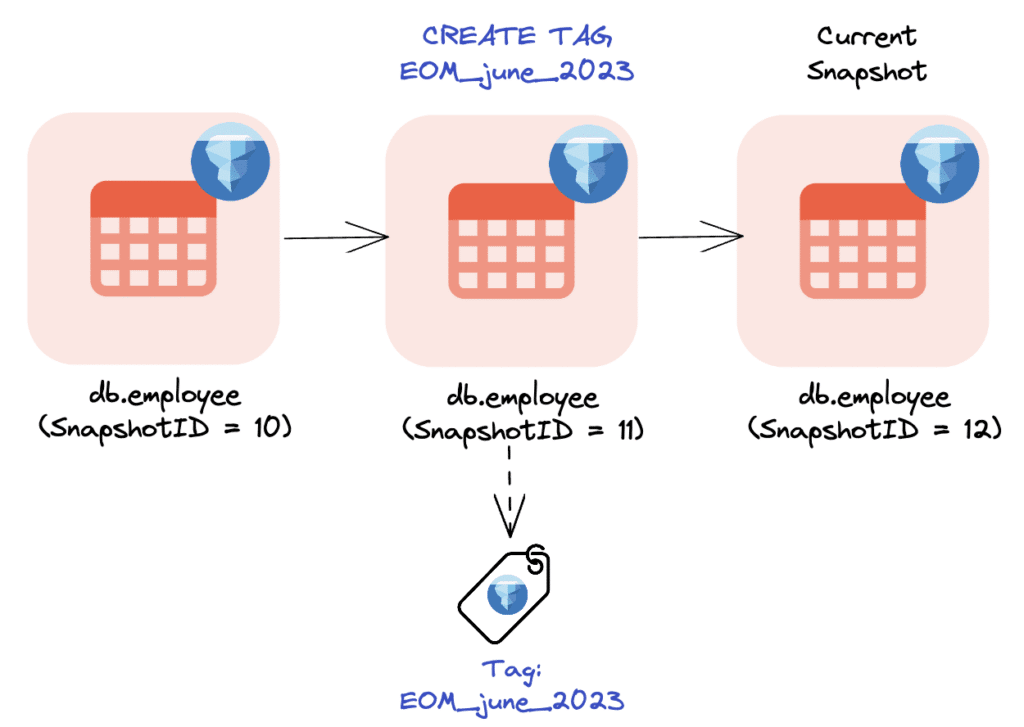
Fig-2: Creating a tag EOM_june_2023 based on SnapshotID = 11
It is important to note that in Iceberg, you have the ability to expire any unwanted snapshots to free up storage or to comply with regulatory policies. This means that if you have a specific tagged dataset that you don’t want to expire, you will have to explicitly do so. With Iceberg, you can use the RETAIN keyword in Spark to specify the number of days you want to keep these tags for. Here’s the syntax.
spark.sql("ALTER TABLE glue.test.employee CREATE TAG EOM_June_2023 RETAIN 365 DAYS ")1.2. Tags in Action
Scenario: Create tags to save a particular table state to use later for analysis.
First, let’s create an Iceberg table called employees. We will use AWS Glue as a catalog here. The code is made available here as a notebook, so feel free to download and start playing with it.
spark.sql(
"""CREATE TABLE IF NOT EXISTS glue.test.employees
(id BIGINT, name STRING, role STRING, salary double) USING iceberg"""
)Now, let’s insert two records into this table.
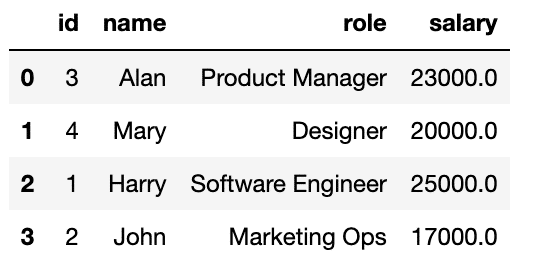
spark.sql("INSERT INTO glue.test.employees values (1, 'Harry', 'Software Engineer', 25000), (2, 'John', 'Marketing Ops', 17000)")Until this point, if we read the data, this is what we can see.
spark.sql("SELECT * FROM glue.test.employees").toPandas()
Assuming we want to save this particular version of the table using a tag for our analysis later, we will create a tag and retain it for 10 days.
spark.sql("ALTER TABLE glue.test.employees CREATE TAG june_data RETAIN 10 DAYS")Now, let’s say an ingestion job inserts a few new records to the table. Here’s how the table currently looks like.
At this stage, we would like to use our saved tag june_data and not the current table state to do our downstream analytical work. To use the tag, here is the syntax.
spark.sql("SELECT * FROM glue.test.employees VERSION AS OF 'june_data'").toPandas()As expected, we can see the records from that particular named reference & it allows us to run workloads on this specific version of the table.

2. Iceberg Branches
2.1. What are Iceberg Branches?
Branches are mutable named references that can be updated by committing a new snapshot as the branch’s referenced snapshot. These commits adhere to Apache Iceberg’s commit conflict resolution and retry principle. Branches open up a whole new avenue for some interesting use cases, such as:
- Implementing Write-Audit-Publish (WAP): Write-Audit-Publish is an important pattern implemented in data engineering workflows to ensure data quality checks. With Iceberg’s branching capability, you can now create branches to write new data and do the necessary audits before advancing the latest table version.
- Isolated data experiments: Branches can be extremely beneficial for isolated data work. For example, experimentation is a huge aspect in the machine learning space that helps engineers and researchers build robust models. In such workflows, you can create an isolated branch based on an existing table, carry out your experiments, and then decide to drop it if you don’t need it anymore. This capability guarantees your experiments have no interference with the production data or workloads.
Here’s how you can create a branch in Spark. Note that, similar to tags, branches can also be retained.
spark.sql("ALTER TABLE glue.test.employee CREATE BRANCH ML_exp")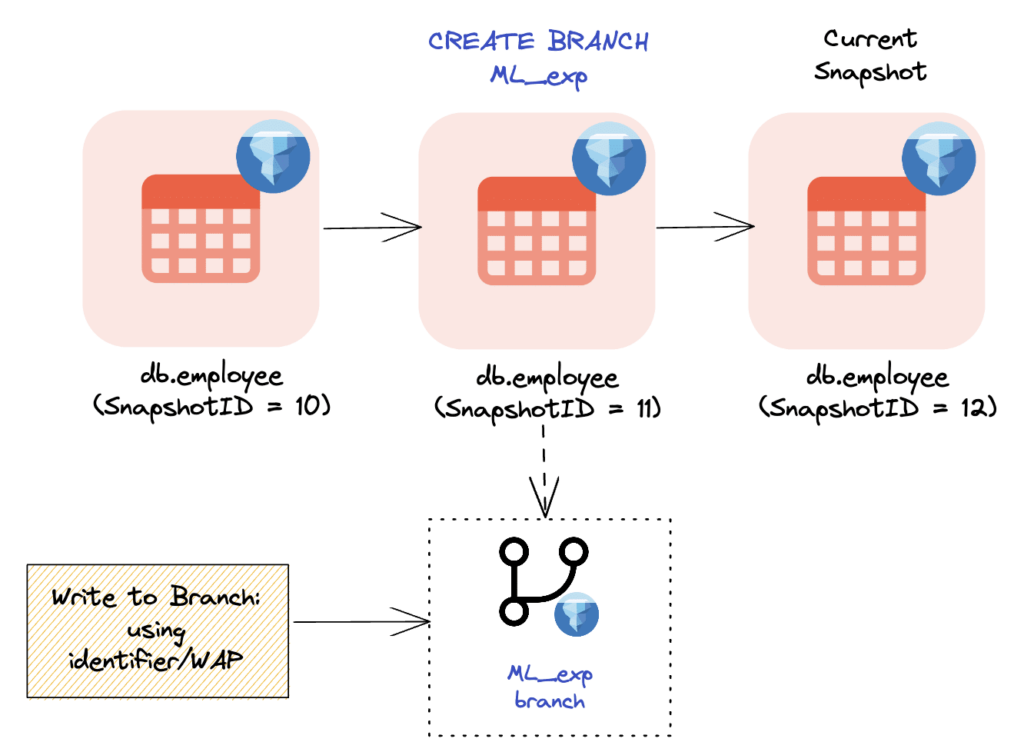
Fig-3: Creating an isolated branch ML_exp based on the SnapshotID=11
2.2. Branches in Action
Scenario: Create an isolated branch of a table for data experiments.
Now, imagine that you are part of a data science team and as part of that you want to do some experimentation work using the existing dataset employees. Your goal here is to have the freedom to insert additional training data to build robust models. However, you want to make sure you don’t impact the current table state in any way as downstream analytical workloads run on top of it.
To cater to this requirement, you first create a fork or branch from the existing table, called ML_exp.
spark.sql("ALTER TABLE glue.test.employees CREATE BRANCH ML_exp")This is what the table’s content in this new branch looks like currently.
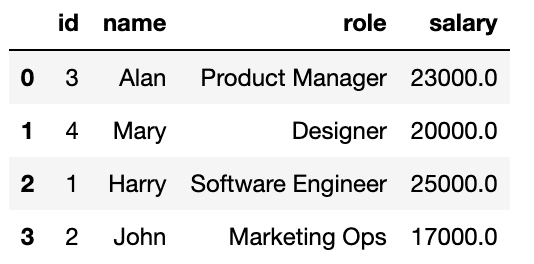
Now, for the experimentation work, you would like to insert some new records into this table as shown below.
schema = spark.table("glue.test.employees").schema
data = [
(6, "Troy", "CMO", 30000.0),
(7, "Raine", "UX", 21000.0),
(8, "Harry", "QA", 22000.0)
]
df = spark.createDataFrame(data, schema)Finally, you write these new records in isolation to the local branch ML_exp, so it doesn’t impact the main table. There are two ways to do this but the first option is the preferred one for any sort of write operations.
Option 1:
df.write.format("iceberg").mode("append").save("glue.test.employees.branch_ML_exp")Option 2:
df.write.format("iceberg").option("branch", "ML_exp").mode("append").save("glue.test.employees")If you now query the data from this specific branch, you can see the new data along with the already existing records.
spark.sql("SELECT * FROM glue.test.employees VERSION AS OF 'ML_exp'").toPandas()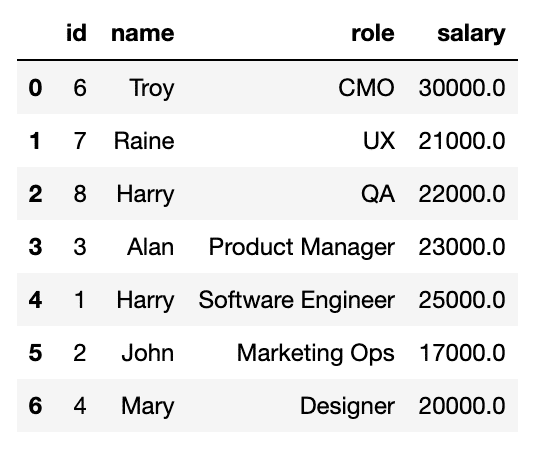
To ensure that there has been no impact on the existing table, you can query the original table and validate. As seen below, the records remain intact and there has been no changes to the table because of your experiment, which is amazing!
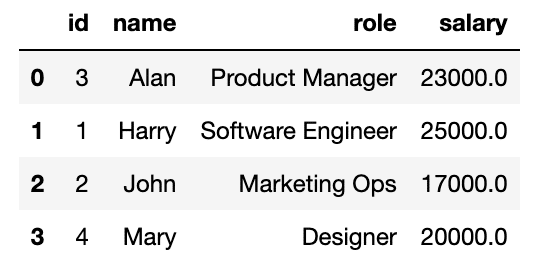
Finally, you go on with inserting some more data for training your model and based on that make the decision to utilize the dataset in production or discard it. If you decide to discard your experiment and don’t want to retain the branch, you can just drop it using this syntax.
spark.sql("ALTER TABLE glue.test.employees DROP BRANCH ML_exp")Additionally, if you want to check all the existing branches and tags for your Iceberg table, you can do so using the metadata table refs. Here is the syntax.
spark.sql("SELECT * FROM glue.test.employees.refs").toPandas()
It is important to note that Iceberg enables native branching and tagging at a table-level, which means that the capabilities are currently limited to a single table. If you are looking to achieve multi-table transactions or rollbacks, using catalog-level branching with solutions like Project Nessie might be more beneficial.
Here are some additional resources on Apache Iceberg.
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->