6 minute read · August 31, 2023
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
· Product Marketing Director, Iceberg Lakehouse Management, Dremio


Big news for new Dremio Cloud customers: Dremio Arctic is now the default catalog, and every new project will come with an Arctic catalog. Dremio Arctic augments the traditional Dremio experience by delivering more capabilities on top of the self-service semantic layer. Now it’s easier than ever to get started building your data lakehouse, and using data as code to easily empower all of your data consumers with a consistent, accurate view of your data.
Dremio Arctic is a data lakehouse management service that makes it easy to manage Iceberg tables and deliver a consistent, accurate, and performant view of your data to all of your consumers while dramatically reducing management overhead and storage footprint.
Let’s go through Arctic’s functionality and the potential applications and benefits of those features. Broadly, they fit into two categories: Data as Code, and automatic optimization of Apache Iceberg tables.
Data as Code
Data as Code enables data teams to manage their data the way software developers manage code. It uses metadata pointers to create a branch, which is a no-copy clone of your data lake. Data teams can create multiple branches for production, development, testing, data ingestion, and more, so multiple data consumers can work on the same data in isolation. No changes are made to the main branch until a user performs a merge via a commit, and all changes are atomic.
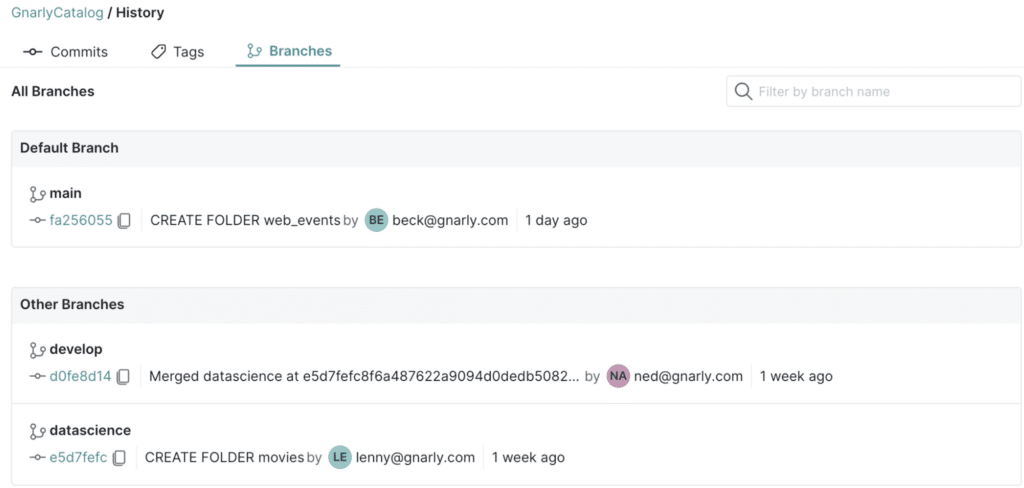
Here are some of the use cases we’ve seen customers implement:
Zero-Copy Clones for Development, Testing, & Production Environments: Many data platforms require data teams to manage and maintain separate environments for development, testing, and production. Aside from the infrastructure costs associated with standing up multiple environments, it can take hours for data teams to ensure that all of the data copies are identical, to keep up with changes to data pipelines, and to ensure that any changes to the data cascade to other copies.
With Dremio Arctic’s no-copy architecture, data teams can easily deliver identical environments without managing or maintaining data copies.
Data Science Branches: Data scientists need access to production-quality data, and the freedom and flexibility to experiment with that data safely. Again, with traditional data platforms, data scientists generally require their own copy of data, which the data team then has to manage and maintain. A data science branch enables data scientists to work with production data in isolation, without impacting the main branch.
Data Ingestion & Data Quality: Data teams can create a separate branch for Extract, Transform & Load (ETL) or ELT workloads, and test that data for quality assurance before merging the new data into the main branch.
There are many possibilities with Data as Code, and perhaps the best part is that we’re just scratching the surface of what’s possible.
Automatic Optimization for your Iceberg Tables
Apache Iceberg is quickly gaining traction as the open table format of choice for data lakes. It was originally developed by Netflix in response to the limitations of Hive tables, especially for large enterprise datasets, and today it enjoys, by far, the broadest ecosystem support of any of the open source table format projects.
For enterprise data lakes, Iceberg features several optimizations that eliminate tedious data management tasks. One of those features is compaction, which rewrites small files into larger files. Organizations with streaming or micro-batching workloads, for example, will find compaction necessary to reduce the read time for queries, and rewriting these files without compaction is a manual, labor-intensive process. Another feature is garbage collection, which removes unused files to optimize storage utilization.
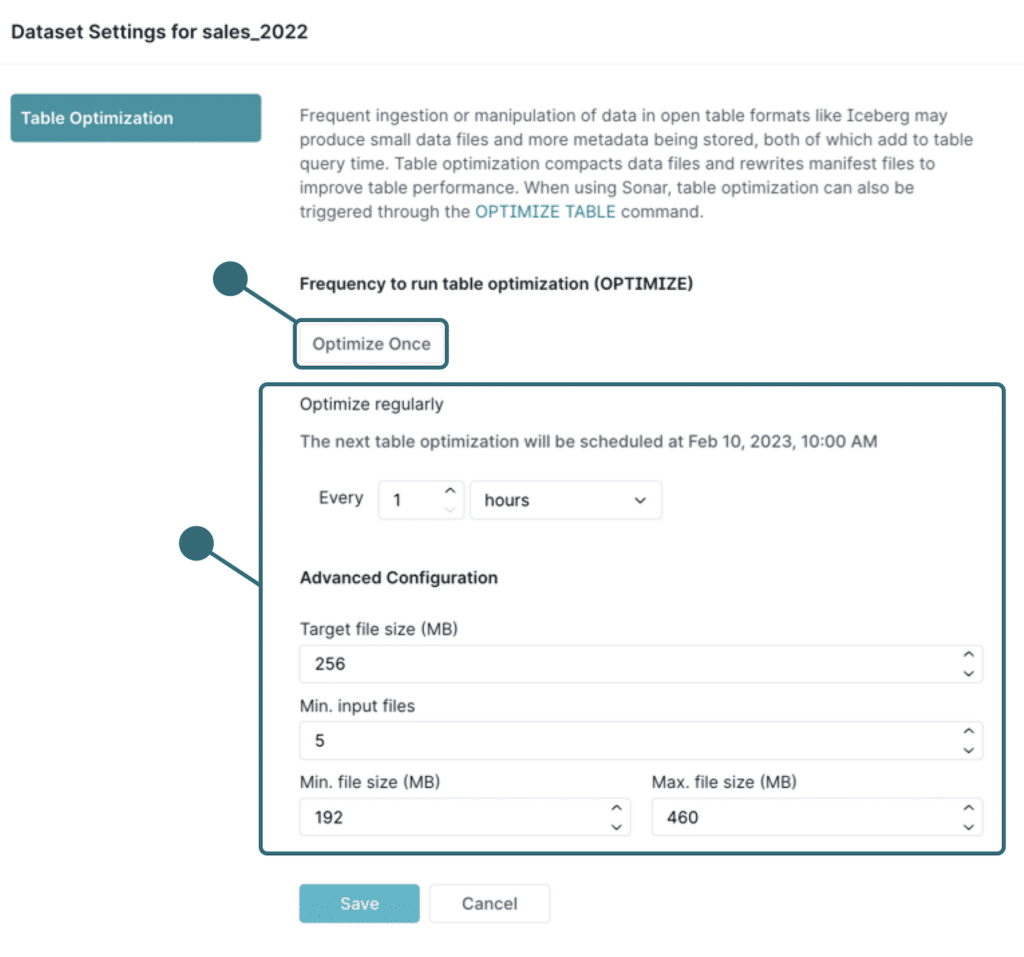
Dremio Arctic automates these processes and performs them on a set schedule, with full automation coming soon.
What's Next?
In future blog posts, we’ll go through these features in more detail and walk through some of the data as code functionality.
In the meantime, join our September 12 episode of Gnarly Data Waves for an introduction to Dremio Arctic, where we’ll dive into the features a little more and demonstrate the data as code functionality.
Additional Resources

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Dremio Cloud on Azure Available Now
Dremio Blog: News Highlights,
Learn More ->

BLOG
What’s New in Dremio: New Gen AI Data Descriptions and a Unified Path to Iceberg with Dremio v24.3 and Dremio Cloud.
Dremio Blog: News Highlights,
Learn More ->