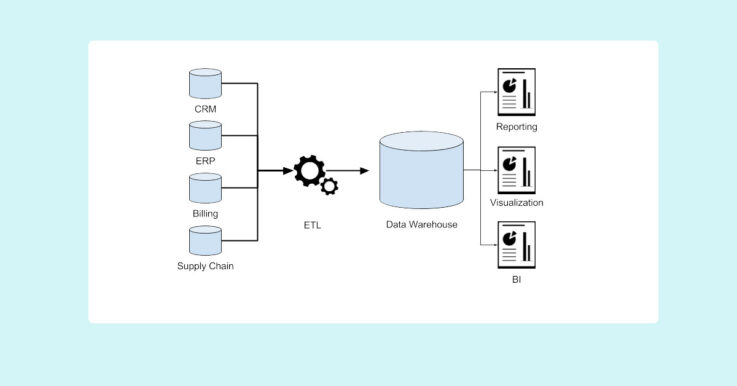
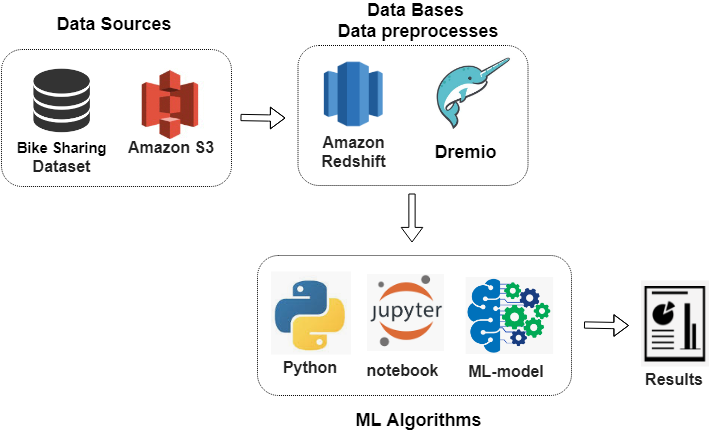
What Is a Data Lakehouse?
As the name suggests, a data lakehouse architecture combines a data lake and a data warehouse. Although it is not just a mere integration between the two, the idea is to bring the best out of the two architectures: the reliable transactions of a data warehouse and the scalability and low cost of a data […]