26 minute read · January 9, 2018
Simplifying and Accelerating Data Access for Python
Simplifying and Accelerating Data Access for Python
Webinar Transcript
Sudheesh Katkam: I’m here to talk about Dremio as Peter mentioned. The spin I’m going to take on this is essentially how data from your sources gets to your Python applications, the whole journey that it takes and what are the complications that come about and why Dremio is the way through … The one way of accessing that data. So data comes in all shapes, sizes and formats. What do I mean by that? So when you have users and you have devices generating data, they actually are providing complex data that comes in to your company for example, and it goes into various sources. So you have your traditional databases like MySql or SqlServer, right?And you have your MongoDB that stores your complex data or you have your Elasticsearch that stores data that you want to search against. So all of these are essentially storage systems. And then you have on top of that, execution systems that help you run some algorithms or logic against the storage systems. And so all of these storage systems actually provide ways to run algorithms. For example, Elasticsearch helps you search, but it also stores the data. But something like python doesn’t store data, it’s just for algorithms. Once you have data captured in these sources, how do you eventually gather intelligence out of it and how do you bring it to your python applications? Typically, you’ll make it go through an extract, transform and load cycle into another system.So it becomes more consumable for the application that you’re building. And after that you have your visualizations and all of that, right? That’s the simplest setup. So let me show you how it’s done right now, so we’ll do a demo. For people who are familiar with Jupyter Notebooks; a Jupyter Notebook is a way to tell a story in Python. That’s how I look at it. So you have some text that’s telling you what to do stuff and then you have some code that helps you with actually … Get the logic, right? So here’s how you would answer … Here’s how, for example you would narrate a story to someone. I wanna see among the most reviewed restaurants in Vegas, what is the best one based on useful reviews?I actually don’t like Yelp’s algorithm, I wanna rely on useful reviews to give me more information about what restaurants I should pick. So Yelp published this data and let’s say for search capabilities we wanna store your business data in Elasticsearch, but something like reviews, which is more flexible and it’s a document style, you wanna put it in MongoDB, right? You don’t want to keep them all in the same store for example. So I’m going to use the Elasticsearch module to connect to an Elasticsearch hose that’s running here. And where do I want to do is I want to figure out all the restaurants, right? So this is basically the search API they provide and I’m searching the business documents and the filter that I’m applying is basically, “I want all restaurants that have a lot of reviews that are in Vegas”, and they’re sorted by review count.So this gives all the restaurants that have been reviewed. So this is how the sample looks like. And then, also notice I use Pandas. So pandas is a data analytics tool kit, which helps you with basically many … It comes with a bunch of algorithms that could be used to transform data. All right, so I’m going to turn it into a Pandas data frame. So once you have data coming from Elasticsearch, I’m gonna translate it into something that Pandas can consume. And a data frame is basically a 2D array with all the values in there. So this is a 2D array that’s the data frame essentially.So this is a sample from Elasticsearch and now let’s look at how the data looks from Mongo, right? So you have the review data in Mongo and then you have this query that says, “Find me in the review data all the votes that are greater five on the useful count. Let me explain about this thing later. And then I’m loading it now to the data frame and just showing the sample of how that looks. So the business ID is the key that we’re going to use across these two tables to do a job. And that’s what this thing does essentially, right? We are trying to count all … We’re doing a join across the two tables and trying to figure it out … Trying to do a join on the business ID, saying that, “Hey, this is the thing that’s going to join them”, meaning it’s a common field. And we’re gonna count all the votes; the count mean and the sum basically. Right?And I had to do more complex things here. For example, the bat size, because I’m loading data from Mongo and Elasticsearch and Pandas just cannot … our Python application just cannot take that much data into the system, right? Because this could be terabytes of data and how would a Python process handle that? It cannot. So what I’m doing is basically generating in batches. I’m getting data in batches and then saying that, “Hey, maintain only the partial results there and then I’ll compute the mean at the end.” Even this actually did not work so I had to cut down the sample even more so that I get a bad sample. Basically saying once I reached 100 restaurants that meet the join condition, I’ll stop. Let’s look at the various other things at this stuff, this coded right? First, we wrote a language that’s very specific to Elasticsearch and we wrote a query language that’s very specific to MongoDB, right? And we also did this normalization, which is basically transforming, the format that Elasticsearch gave us into a data frame. We did the same thing again for MongoDB. I think I do it here, right? So we are getting … We’re transforming a JSON into again, a data frame. So there’s a lot of copy and conversion going on here. Turns out, whenever you do an append to a data frame, it actually makes another copy. So there’s a lot of copies that are going along here that are invisible.Now, let’s move on to something that will solve that problem for us. Let’s first understand from the sources, right? So the main use case that we have is analytics, right? Where it says something like transactions, right? If you’re looking at data layout in memory, you’re gonna see a table looks … A table has a bunch of rows and columns, but something like traditionally when you put this on run, you put one field after another, right? And now you have fields that are … If you look at blues, they are actually separated from each other, right?
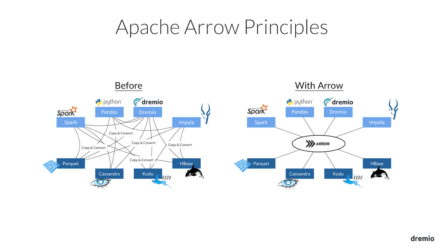
Let’s look at the various other things at this stuff, this coded right? First, we wrote a language that’s very specific to Elasticsearch and we wrote a query language that’s very specific to MongoDB, right? And we also did this normalization, which is basically transforming, the format that Elasticsearch gave us into a data frame. We did the same thing again for MongoDB. I think I do it here, right? So we are getting … We’re transforming a JSON into again, a data frame. So there’s a lot of copy and conversion going on here. Turns out, whenever you do an append to a data frame, it actually makes another copy. So there’s a lot of copies that are going along here that are invisible.Now, let’s move on to something that will solve that problem for us. Let’s first understand from the sources, right? So the main use case that we have is analytics, right? Where it says something like transactions, right? If you’re looking at data layout in memory, you’re gonna see a table looks … A table has a bunch of rows and columns, but something like traditionally when you put this on run, you put one field after another, right? And now you have fields that are … If you look at blues, they are actually separated from each other, right? But imagine something like this, you could just put the whole column next to each other and now this gives you … This is more friendly to the cache, right? Meaning if I wanted the next value, I just load the whole column and I don’t have to load the rows in order to get the columns. So that’s what Arrow’s mainly being done. Arrow is an open source Apache project that tries to simplify columnar data analytics and this is the model it chose. And if you notice that, it also not tries to … It’s just a format, helps with simplifying how columns are accessed and since analytics is based on columnar data, it’s more [inaudible 00:09:15].
But imagine something like this, you could just put the whole column next to each other and now this gives you … This is more friendly to the cache, right? Meaning if I wanted the next value, I just load the whole column and I don’t have to load the rows in order to get the columns. So that’s what Arrow’s mainly being done. Arrow is an open source Apache project that tries to simplify columnar data analytics and this is the model it chose. And if you notice that, it also not tries to … It’s just a format, helps with simplifying how columns are accessed and since analytics is based on columnar data, it’s more [inaudible 00:09:15]. The problem you’re trying to solve in this case specifically is you have systems communicating with each other and they need to speak the same language, right? Otherwise, every time, for example, MongoDB is talking to Python, you have to translate into something Python understands. Arrow tries to avoid that. How it does that is, if both the systems agreed to a common language, then they don’t have to do a translation, right? That’s what Arrow basically is. And for example, if you’re running on the same mode, you can share a mapped file and say, “Hey, this system is gonna write data to this file, the system can read from it.” Or for example if you’re doing a [inaudible 00:09:59], right? So once you add it to the wire and it’s read from the wire, you don’t need to translate it because both the systems understand the same language. It’s important that this language also accommodates nested Schema, meaning something like documents, so it’s catered towards complex data, right? Arrow provides a multiple implementations in C++ and Java and we have bindings in different languages. So it’s also language agnostic.
The problem you’re trying to solve in this case specifically is you have systems communicating with each other and they need to speak the same language, right? Otherwise, every time, for example, MongoDB is talking to Python, you have to translate into something Python understands. Arrow tries to avoid that. How it does that is, if both the systems agreed to a common language, then they don’t have to do a translation, right? That’s what Arrow basically is. And for example, if you’re running on the same mode, you can share a mapped file and say, “Hey, this system is gonna write data to this file, the system can read from it.” Or for example if you’re doing a [inaudible 00:09:59], right? So once you add it to the wire and it’s read from the wire, you don’t need to translate it because both the systems understand the same language. It’s important that this language also accommodates nested Schema, meaning something like documents, so it’s catered towards complex data, right? Arrow provides a multiple implementations in C++ and Java and we have bindings in different languages. So it’s also language agnostic. Previously it would look something like this. So when you’re talking between components, again, you have to copy and convert data every time you were crossing a system within the node or across the node; but with Arrow, you’re gonna speak the same language, so all systems understand as long as they provide this API, how to access and transform the data. A key thing to Arrow is obviously adoption, you need a lot of systems to speak the same language and there’s a lot of involvement in contributing to Arrow and in fact, there’s a 40 x increase in downloads from last year to this year.Now that we established a common language across the systems that are in your company, we’ve got to also provide a way to execute the algorithms that these systems may not be able to do, and that’s what Dremio’s about. We launched in July and like I mentioned, we are an open source self service data platform and I’m getting to what are the different aspects of that, that helped with it. And we are Apache licensed so you can download it online and start using it immediately. We are proud to be built on a lot of open source projects as well. We use Arrow as our-in memory data format. [crosstalk 00:12:09] Well I have some stickers here … First we are a web based application, so you’ll see it’s very easy to navigate and everything. We have a bunch of sources we have.
Previously it would look something like this. So when you’re talking between components, again, you have to copy and convert data every time you were crossing a system within the node or across the node; but with Arrow, you’re gonna speak the same language, so all systems understand as long as they provide this API, how to access and transform the data. A key thing to Arrow is obviously adoption, you need a lot of systems to speak the same language and there’s a lot of involvement in contributing to Arrow and in fact, there’s a 40 x increase in downloads from last year to this year.Now that we established a common language across the systems that are in your company, we’ve got to also provide a way to execute the algorithms that these systems may not be able to do, and that’s what Dremio’s about. We launched in July and like I mentioned, we are an open source self service data platform and I’m getting to what are the different aspects of that, that helped with it. And we are Apache licensed so you can download it online and start using it immediately. We are proud to be built on a lot of open source projects as well. We use Arrow as our-in memory data format. [crosstalk 00:12:09] Well I have some stickers here … First we are a web based application, so you’ll see it’s very easy to navigate and everything. We have a bunch of sources we have. And we know it’s a nested structure in MongoDB and I’m interested in all the funny ones. So I’m gonna extract that element, right? Instead of having to write that query I can just extract it here and I can say. “Useful_votes” so keep track of it. Sorry. Now I’ve said I want to pick a range for it, right? I say, “Keep only”, and I said, “I want all the useful words that are more than five”. So the same process is more through an interface that is easier to manipulate data.That was Elasticsearch area. So now we can see if this data set has … So you can create spaces that you can share with your coworkers. So I created a review data here and now let’s do Elasticsearch business data. Right? So in Elastic we have business data. We’re interested in our restaurants that are in Vegas, so based on the sample let’s try to keep only the restaurants that are in Vegas. And what other conditions did I have? I had a review count of greater than 100. Oops. “Keep only” and then write something that’s bigger than a hundred. So now this actually a confirmation on the sample on the data and we can save that to this old “Restaurants”. We can save that as, “My Elastic data.”And then we did a complex join across the two data sets based on the business ID. So let’s do that. So I am gonna look at the elastic data and out of the join. Immediately you see it’s trying to suggest some datasets. I am gonna do a custom join on to the review data. So on this side I have the business ID, and on this side too, I have the business ID. So I can preview what that join looks like. Then we did a group buy to figure out how many stars across the two data sets we have.We have the measures, which is, which column are we summing up against? Right? And we have a mean, and we have a count.So, I figured out at the same algorithm, through a flow that you would typically expect, and then the complexities of having to deal with the differentdomain specific languages is gone. And if you are more familiar with SQL, this is essentially a SQL statement and you could edit that too. So right now I actually only accessed a sample of the rear, right? And sort of not running the full fledged query against the terabytes of data that could exist in these two sources. I just hit run and now they should query the two sources and return the same result. I think I should do a, “Order by” as well to figure out what the top one is.All right. So I think I forgot to add a filter on the restaurants so we ended up at other flavors, but yes. And now that we’ve set this up, we are seeing the data flow off from ElasticSearch and MongoDB into Dremio, and then we have the Python API, right? So Dremio has ODBC API and you can access that through the ODBC module that’s available, and you connect to the data source, and basically I did a query against the data set that we have, connecting to Dremio. Now I think this is all, so I’m just going to refresh that. I think let’s first save this as “My results.”So the same my reviewed results as what I’m accessing, I should be accessing through my Python connection, and should be able to see the same data. It’s gonna give a sample … All right, so we see the same results here too. So essentially the whole process of accessing data sources through a unified layer becomes useful when you have a system that can understand that there’s different bits of logic that should go to different systems, and it should be an aggregation system. That’s where you can join the results across the systems. That’s what Dremio provides. Like I mentioned, in open source and the other community that’s active and … yeah.So the part where I did a setup of the data across different sources that could be scripted as well. That is correct. So are you talking about Python scripts.So the thing with that is when you do set that scripts up, you’re gonna have to load the data into python, right? And you’re gonna have to have enough memory to be able to accommodate that. And there’s the bit where after you do that, you’re doing a join across a different data set, right? And when you do that, something like a join explodes the side of the results and a python application cannot handle that. And how we simplify that is … So there’s bits in the first way that I showed, that says, “Hey, give me only this part of data from Elasticsearch and only this part of data from MongoDB, and that’s something Dremio uses as well. We don’t scan the entire data sets from both Elasticsearch and Mongo. We do push down logic into Mongo and Elasticsearch saying, “Hey, give me only the relevant bits that should be joined.”So the question is, imagine a scenario where you have different systems located maybe geographically differently and you have maybe different formats, but it’s the same kind of data, right? Meaning say for example, it’s crime data, how do you access through one layer? Can our system handle it? Yes. You would basically define what I created was a data set that actually … It’s almost like a virtual data set. It’s actually not accessing the … It’s representing what the underlying data is, but it’s not really a data set by itself. So you would say, “Hey, this isn’t this format.” And you could create like a virtual data set that is a union of all those data sets using “union all”, and then you can access that virtually the same.What would be the advantage?. Imagine these systems … So first of all, you don’t have to bring it into one system. It will be able to analyze this here, right? And what that brings is you don’t maintain any copies, you’re just maintaining this view on the data. Another advantage I could think of is … so you can only go as fast as the scanners can go on the systems. But if the systems do provide some form of a logic push down, that will be used, right? And if you do want to do something like get it faster then you could actually cache it in our system. For example, if multiple users are more curious about that data, then we try to intelligent cache it and then provide an alternative view of that data set.
And we know it’s a nested structure in MongoDB and I’m interested in all the funny ones. So I’m gonna extract that element, right? Instead of having to write that query I can just extract it here and I can say. “Useful_votes” so keep track of it. Sorry. Now I’ve said I want to pick a range for it, right? I say, “Keep only”, and I said, “I want all the useful words that are more than five”. So the same process is more through an interface that is easier to manipulate data.That was Elasticsearch area. So now we can see if this data set has … So you can create spaces that you can share with your coworkers. So I created a review data here and now let’s do Elasticsearch business data. Right? So in Elastic we have business data. We’re interested in our restaurants that are in Vegas, so based on the sample let’s try to keep only the restaurants that are in Vegas. And what other conditions did I have? I had a review count of greater than 100. Oops. “Keep only” and then write something that’s bigger than a hundred. So now this actually a confirmation on the sample on the data and we can save that to this old “Restaurants”. We can save that as, “My Elastic data.”And then we did a complex join across the two data sets based on the business ID. So let’s do that. So I am gonna look at the elastic data and out of the join. Immediately you see it’s trying to suggest some datasets. I am gonna do a custom join on to the review data. So on this side I have the business ID, and on this side too, I have the business ID. So I can preview what that join looks like. Then we did a group buy to figure out how many stars across the two data sets we have.We have the measures, which is, which column are we summing up against? Right? And we have a mean, and we have a count.So, I figured out at the same algorithm, through a flow that you would typically expect, and then the complexities of having to deal with the differentdomain specific languages is gone. And if you are more familiar with SQL, this is essentially a SQL statement and you could edit that too. So right now I actually only accessed a sample of the rear, right? And sort of not running the full fledged query against the terabytes of data that could exist in these two sources. I just hit run and now they should query the two sources and return the same result. I think I should do a, “Order by” as well to figure out what the top one is.All right. So I think I forgot to add a filter on the restaurants so we ended up at other flavors, but yes. And now that we’ve set this up, we are seeing the data flow off from ElasticSearch and MongoDB into Dremio, and then we have the Python API, right? So Dremio has ODBC API and you can access that through the ODBC module that’s available, and you connect to the data source, and basically I did a query against the data set that we have, connecting to Dremio. Now I think this is all, so I’m just going to refresh that. I think let’s first save this as “My results.”So the same my reviewed results as what I’m accessing, I should be accessing through my Python connection, and should be able to see the same data. It’s gonna give a sample … All right, so we see the same results here too. So essentially the whole process of accessing data sources through a unified layer becomes useful when you have a system that can understand that there’s different bits of logic that should go to different systems, and it should be an aggregation system. That’s where you can join the results across the systems. That’s what Dremio provides. Like I mentioned, in open source and the other community that’s active and … yeah.So the part where I did a setup of the data across different sources that could be scripted as well. That is correct. So are you talking about Python scripts.So the thing with that is when you do set that scripts up, you’re gonna have to load the data into python, right? And you’re gonna have to have enough memory to be able to accommodate that. And there’s the bit where after you do that, you’re doing a join across a different data set, right? And when you do that, something like a join explodes the side of the results and a python application cannot handle that. And how we simplify that is … So there’s bits in the first way that I showed, that says, “Hey, give me only this part of data from Elasticsearch and only this part of data from MongoDB, and that’s something Dremio uses as well. We don’t scan the entire data sets from both Elasticsearch and Mongo. We do push down logic into Mongo and Elasticsearch saying, “Hey, give me only the relevant bits that should be joined.”So the question is, imagine a scenario where you have different systems located maybe geographically differently and you have maybe different formats, but it’s the same kind of data, right? Meaning say for example, it’s crime data, how do you access through one layer? Can our system handle it? Yes. You would basically define what I created was a data set that actually … It’s almost like a virtual data set. It’s actually not accessing the … It’s representing what the underlying data is, but it’s not really a data set by itself. So you would say, “Hey, this isn’t this format.” And you could create like a virtual data set that is a union of all those data sets using “union all”, and then you can access that virtually the same.What would be the advantage?. Imagine these systems … So first of all, you don’t have to bring it into one system. It will be able to analyze this here, right? And what that brings is you don’t maintain any copies, you’re just maintaining this view on the data. Another advantage I could think of is … so you can only go as fast as the scanners can go on the systems. But if the systems do provide some form of a logic push down, that will be used, right? And if you do want to do something like get it faster then you could actually cache it in our system. For example, if multiple users are more curious about that data, then we try to intelligent cache it and then provide an alternative view of that data set. And we’ve stored it in Arrow friendly format because this is very likely gonna be a columnar analytic case, right? So yes, in that case we do provide intelligent cache to make the data access faster.So the question is, do you do query push downs? Well, how I’d like to think about that is, you’re writing your query as a SQL and you wanna do part of the query into the system itself. For example, SQL Server fully support SQL, right? If you wanna … Instead of transferring any data from SQL Server into Dremio, into the application, we just say, “Hey, push down the entire query into SQL Server.” It already knows how to run that logic. In fact we do more complex than that. If you have Elasticsearch and SQLServer, we know which bit should be pushed into Elasticsearch, which bit should be pushed into SQL Server, and then we only do the final aggregations of joins that you have.The question is, is the aggregation part scalable? Yes. So it depends on your deployment, but Dremio is horizontally scalable, you can deploy as many executors as you want, that’s what we call them. And this could be like a distributed hash table across all of them and if there’s an aggregation that’s taken care of as well. And there’s a swing to disk, meaning if we were working on that, it basically means if this hash tag was still bigger than what can fit in the memory, we can actually write to disk and then read it back and merge the results.So that’s essentially … The question is, can you look up in a system that provides secondary indexes to a field that you wanna look up in a private system, right? How you would do that is using something called reflections. You can define a –Kelly Stirman: So imagine for a moment that the source aid is JSON in S3 and you had, you know, ten billion JSON Documents in S3. Scanning that is gonna be very slow. So Dremio has a concept called data reflections where there are two kinds of reflections. One is we call a raw reflection where we will materialize that JSON is parquet in our reflection store because scanning parquet is about, you know, 500 times faster than scanning the raw JSON unnecessary.The second type of reflection is called an aggregation reflection and this is where we would precompute average min, Max, sum, those kinds of values grouped by dimensions that you specify. So if you had Tablo workloads or BI tool workloads that you wanted to make really, really fast, we’ve pre-computed all those answers and processed those as Parquet and our query planner can intersect those sequel queries and rewrite them to use the parquet.So it’s not a traditional beetroot-style index, but the idea is can we organize the data in such a way that it makes the query planning much more efficient? Which is fundamentally what an index does. We have different kinds of reflections. These are all invisible to the querying application, so you never worry about this in Python. You never worry about this in a BI tool. They’re just things that the query planner can use to make the queries very, very fast. And so we don’t always push queries down into the source. We can use these reflections to make the queries really fast, but also to offload operational systems because a lot of times you have an operational system, you don’t want to send a table scan because it’s gonna crush the performance of that system. So these reflections can offload the analytics from the operational system as well.So the question is, are there limitations in terms of Schema complexity of the source data? So if you’re coming to join me, I worked at MongoDB for four years and so yeah, I’m familiar with some, you know, people abusing Schema and abusing JSON in a variety of interestingly ways. There really aren’t … We have full support for the JSON Spec and all the rich types available in JSON, and we’ve really tried them. And one of the principles of Arrow is that it accommodates nested data structures in JSON as well as traditional table type data structures in one in memory format and it’s very, very efficient for these kinds of things. So the idea is you shouldn’t have to compromise just because the Schema is complex, but the thing that’s more problematic for most people aside from the complexity of the Schema is that the Schema changes from document to document.One of the things that’s in Dremio is a schema learning engine that we go read data from the source and infer a Schema and then we read again and if that schema changes, we automatically update our catalog of what the Schema is, so that as documents evolve or as the underlying schema evolves, you don’t have to reconfigure the system. And that’s a real advantage because people, one of the things that happens in these lesser schema dynamic environments like Elastic and Mongo is developers just kind of do whatever they want and they start adding documents and sometimes not on purpose and you don’t have a Schema to refer to, to know what it is you have to work with. The adoptive engine is very important.So I think the question is, it looks like Dremio is focused on making it so data’s accessible no matter where it is, but what about redistributing the data to consumers almost in a pub-sub model or almost like Kafka? Right now we are focused on analytics. Dremio has read only access to all these sources, but the idea of a virtual data set is you can very cheaply create views of data no matter what somebody wants without making a copy of the data. And so you can create these virtual data sets and a consuming application could pull those virtual data sets and pick up whatever they want very, very efficiently. I think a real problem is making copies of the data and people wanna get away from that. So we virtualized how you access data and how you transform data using SQL and made it so that anyone can have the data they want without making copies and also without writing a bunch of code to create those virtual datasets.Dremio is a Java application that you can download and run on your laptop, which is, you know, what I do myself. But it’s really designed in a scale-out distributed deployment and you can either run it stand alone in containers or on EC2. These reflections we talked about can persist in S3 or if you already have a Hadoop cluster, you can provision and manage Dremio me as a YARN application. In fact that screen is pretty straight forward. If you come into, you would install dremio on an edge note in your Hadoop cluster, and you would go to this, pick your flavor of Hadoop that you’re running and you would put in the IP address for the resource manager and name note and then how many workers and how many cores and how much ram per worker. If you want twenty, if you want fifty, if you want a thousand and then YARN will go provision that in the Hadoop cluster. We’re working on similar capabilities for Mercers and Kubernetes and all the other kind of orchestration frameworks, but the idea is that you’re gonna run this in a distributed environment, and there’s built in automatic high availability and it’s at its core, a java based application that logs the sis log and Jay log and you’re able to run this pretty easily, and we’re making the system more autonomous over time.It’s less work and easier to use than Hadoop. It’s maybe not as easy to use as Python, for those of you here tonight, but we’ve really tried to make something that anyone can use very, very easily to kind of take control of the data and put it in the hands of the data consumer. So you can go to the download page with Noelly. Say, Hi Noelly. So you’ve got a community edition and it’s gonna default to whatever operating system your browser is on, but you’ve got Windows, RPM, Tor, and if you happen to be a user of MapR, we have a distribution from MapR.And then we have an enterprise edition that’s a paid version of the product. If you have an Air gap’s deployment that you want to install Dremio, then you’re gonna put it on some sort of media and take it into your environment and you’re gonna stand up dremio on a single server and then you’re going to make some configuration changes and the subsequent nodes that you bring up, you seed with an IP address to phone home to the master node and then it will pick up the configuration of all the nodes as the server comes to live.Let’s say its conception is the same as if you’re using containers. We have the concept of a coordinator node and an executer node and there’s one master coordinator node that takes care of all the metadata for the whole system and everybod sort of picks up from that master node.OK, that’s actually a great question. So the question is, if I have a data source that’s not on this list, how do I access the data, including an API? Like what if the data is in Salesforce or Marketo or something like that, or Workday? And so we have an STA coming in the next six months that will let you configure a data source to be addressable by Dremio. And this is a non-trivial exercise because we basically want to be able to take any arbitrary sequel expression and pushed down what makes sense to push down into whatever source that is. So if you have a way to push that data from Cloudwatch into S3, then we can pick up the stuff in S3. Right now we don’t have an API for Cloudwatch. It’s an interesting suggestion, it’s the kind of thing that maybe we would add or maybe something you would build yourself, or the community would build that you would be able to use kind of plugging to Dremio.How does this differ from Apache drill is the question. The question is interesting, especially since the creators of Dremio were also the architects of Apache Drill, and Drill is a kind of SQL on anything technology. If you were using Cloudera, you would have Impala as the SQL execution engine. If you were using Hortonworks, you would have Hive. If you were using MapR you would have Drill. The Drill is more like Presto and then it lets you query things that aren’t in your Hadoop cluster. So Dremio is similar to Drill in that it’s a SQL execution engine that is able to query systems and different technologies and we actually call that part of our product CBO. It’s the execution engine. But drill does not have this rich user interface. It does not have data acceleration capabilities and also the core execution engine does not use Arrow, and it does not have an asynchronous execution model, which is really important for doing high concurrency workloads with very, very good performance.So it’s kind of like a new take on some of the basic ideas of Drill that is I think much, much further along than where Drill is today. So the next question is what about streaming data? Not all my data’s at rest. So Kafka will, I believe next year, be one of the first class sources here. And one of the things we’ll do is we’ll make it so you could union Kafka data with data at rest and we’ll do the intersection of those data sets so you don’t have to worry about that in your application merging. Thank you. Thank you guys very much, we really appreciate it.
And we’ve stored it in Arrow friendly format because this is very likely gonna be a columnar analytic case, right? So yes, in that case we do provide intelligent cache to make the data access faster.So the question is, do you do query push downs? Well, how I’d like to think about that is, you’re writing your query as a SQL and you wanna do part of the query into the system itself. For example, SQL Server fully support SQL, right? If you wanna … Instead of transferring any data from SQL Server into Dremio, into the application, we just say, “Hey, push down the entire query into SQL Server.” It already knows how to run that logic. In fact we do more complex than that. If you have Elasticsearch and SQLServer, we know which bit should be pushed into Elasticsearch, which bit should be pushed into SQL Server, and then we only do the final aggregations of joins that you have.The question is, is the aggregation part scalable? Yes. So it depends on your deployment, but Dremio is horizontally scalable, you can deploy as many executors as you want, that’s what we call them. And this could be like a distributed hash table across all of them and if there’s an aggregation that’s taken care of as well. And there’s a swing to disk, meaning if we were working on that, it basically means if this hash tag was still bigger than what can fit in the memory, we can actually write to disk and then read it back and merge the results.So that’s essentially … The question is, can you look up in a system that provides secondary indexes to a field that you wanna look up in a private system, right? How you would do that is using something called reflections. You can define a –Kelly Stirman: So imagine for a moment that the source aid is JSON in S3 and you had, you know, ten billion JSON Documents in S3. Scanning that is gonna be very slow. So Dremio has a concept called data reflections where there are two kinds of reflections. One is we call a raw reflection where we will materialize that JSON is parquet in our reflection store because scanning parquet is about, you know, 500 times faster than scanning the raw JSON unnecessary.The second type of reflection is called an aggregation reflection and this is where we would precompute average min, Max, sum, those kinds of values grouped by dimensions that you specify. So if you had Tablo workloads or BI tool workloads that you wanted to make really, really fast, we’ve pre-computed all those answers and processed those as Parquet and our query planner can intersect those sequel queries and rewrite them to use the parquet.So it’s not a traditional beetroot-style index, but the idea is can we organize the data in such a way that it makes the query planning much more efficient? Which is fundamentally what an index does. We have different kinds of reflections. These are all invisible to the querying application, so you never worry about this in Python. You never worry about this in a BI tool. They’re just things that the query planner can use to make the queries very, very fast. And so we don’t always push queries down into the source. We can use these reflections to make the queries really fast, but also to offload operational systems because a lot of times you have an operational system, you don’t want to send a table scan because it’s gonna crush the performance of that system. So these reflections can offload the analytics from the operational system as well.So the question is, are there limitations in terms of Schema complexity of the source data? So if you’re coming to join me, I worked at MongoDB for four years and so yeah, I’m familiar with some, you know, people abusing Schema and abusing JSON in a variety of interestingly ways. There really aren’t … We have full support for the JSON Spec and all the rich types available in JSON, and we’ve really tried them. And one of the principles of Arrow is that it accommodates nested data structures in JSON as well as traditional table type data structures in one in memory format and it’s very, very efficient for these kinds of things. So the idea is you shouldn’t have to compromise just because the Schema is complex, but the thing that’s more problematic for most people aside from the complexity of the Schema is that the Schema changes from document to document.One of the things that’s in Dremio is a schema learning engine that we go read data from the source and infer a Schema and then we read again and if that schema changes, we automatically update our catalog of what the Schema is, so that as documents evolve or as the underlying schema evolves, you don’t have to reconfigure the system. And that’s a real advantage because people, one of the things that happens in these lesser schema dynamic environments like Elastic and Mongo is developers just kind of do whatever they want and they start adding documents and sometimes not on purpose and you don’t have a Schema to refer to, to know what it is you have to work with. The adoptive engine is very important.So I think the question is, it looks like Dremio is focused on making it so data’s accessible no matter where it is, but what about redistributing the data to consumers almost in a pub-sub model or almost like Kafka? Right now we are focused on analytics. Dremio has read only access to all these sources, but the idea of a virtual data set is you can very cheaply create views of data no matter what somebody wants without making a copy of the data. And so you can create these virtual data sets and a consuming application could pull those virtual data sets and pick up whatever they want very, very efficiently. I think a real problem is making copies of the data and people wanna get away from that. So we virtualized how you access data and how you transform data using SQL and made it so that anyone can have the data they want without making copies and also without writing a bunch of code to create those virtual datasets.Dremio is a Java application that you can download and run on your laptop, which is, you know, what I do myself. But it’s really designed in a scale-out distributed deployment and you can either run it stand alone in containers or on EC2. These reflections we talked about can persist in S3 or if you already have a Hadoop cluster, you can provision and manage Dremio me as a YARN application. In fact that screen is pretty straight forward. If you come into, you would install dremio on an edge note in your Hadoop cluster, and you would go to this, pick your flavor of Hadoop that you’re running and you would put in the IP address for the resource manager and name note and then how many workers and how many cores and how much ram per worker. If you want twenty, if you want fifty, if you want a thousand and then YARN will go provision that in the Hadoop cluster. We’re working on similar capabilities for Mercers and Kubernetes and all the other kind of orchestration frameworks, but the idea is that you’re gonna run this in a distributed environment, and there’s built in automatic high availability and it’s at its core, a java based application that logs the sis log and Jay log and you’re able to run this pretty easily, and we’re making the system more autonomous over time.It’s less work and easier to use than Hadoop. It’s maybe not as easy to use as Python, for those of you here tonight, but we’ve really tried to make something that anyone can use very, very easily to kind of take control of the data and put it in the hands of the data consumer. So you can go to the download page with Noelly. Say, Hi Noelly. So you’ve got a community edition and it’s gonna default to whatever operating system your browser is on, but you’ve got Windows, RPM, Tor, and if you happen to be a user of MapR, we have a distribution from MapR.And then we have an enterprise edition that’s a paid version of the product. If you have an Air gap’s deployment that you want to install Dremio, then you’re gonna put it on some sort of media and take it into your environment and you’re gonna stand up dremio on a single server and then you’re going to make some configuration changes and the subsequent nodes that you bring up, you seed with an IP address to phone home to the master node and then it will pick up the configuration of all the nodes as the server comes to live.Let’s say its conception is the same as if you’re using containers. We have the concept of a coordinator node and an executer node and there’s one master coordinator node that takes care of all the metadata for the whole system and everybod sort of picks up from that master node.OK, that’s actually a great question. So the question is, if I have a data source that’s not on this list, how do I access the data, including an API? Like what if the data is in Salesforce or Marketo or something like that, or Workday? And so we have an STA coming in the next six months that will let you configure a data source to be addressable by Dremio. And this is a non-trivial exercise because we basically want to be able to take any arbitrary sequel expression and pushed down what makes sense to push down into whatever source that is. So if you have a way to push that data from Cloudwatch into S3, then we can pick up the stuff in S3. Right now we don’t have an API for Cloudwatch. It’s an interesting suggestion, it’s the kind of thing that maybe we would add or maybe something you would build yourself, or the community would build that you would be able to use kind of plugging to Dremio.How does this differ from Apache drill is the question. The question is interesting, especially since the creators of Dremio were also the architects of Apache Drill, and Drill is a kind of SQL on anything technology. If you were using Cloudera, you would have Impala as the SQL execution engine. If you were using Hortonworks, you would have Hive. If you were using MapR you would have Drill. The Drill is more like Presto and then it lets you query things that aren’t in your Hadoop cluster. So Dremio is similar to Drill in that it’s a SQL execution engine that is able to query systems and different technologies and we actually call that part of our product CBO. It’s the execution engine. But drill does not have this rich user interface. It does not have data acceleration capabilities and also the core execution engine does not use Arrow, and it does not have an asynchronous execution model, which is really important for doing high concurrency workloads with very, very good performance.So it’s kind of like a new take on some of the basic ideas of Drill that is I think much, much further along than where Drill is today. So the next question is what about streaming data? Not all my data’s at rest. So Kafka will, I believe next year, be one of the first class sources here. And one of the things we’ll do is we’ll make it so you could union Kafka data with data at rest and we’ll do the intersection of those data sets so you don’t have to worry about that in your application merging. Thank you. Thank you guys very much, we really appreciate it.




