52 minute read · March 21, 2018
Vectorized Query Processing Using Apache Arrow
Webinar Transcript
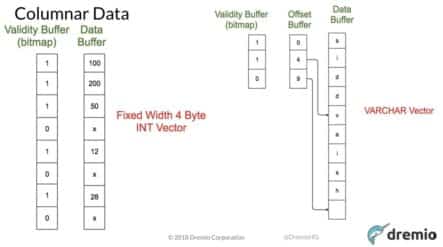
Siddharth:Hello, everyone welcome to my presentation on Vectorized Query Processing using Apache Arrow. I gave this talk two weeks ago at Strata Data conference in San Jose.A brief introduction my name is Siddharth, I’m currently a software engineer at Dremio. Was part of in memory query execution team, I’m also a committer Apache Arrow project. I was previously employed with Oracle as part of Database Egine team and worked on projects related to storage, indexing, transaction processing and columnar query execution. I also love writing technical contents, so I’m an active technical blogger and contribute a lot of technical content as part of, of things that I learn as part of my software engineering job on Quora.Apache Arrow project is a top level open source project and Apache’s software foundation. It was announced two years ago and has seen rapid growth. Developers from 13 plus major open source organization and projects have been contributing to the growth of Arrow community in terms of code, documentation and evangelizing the project as well as helping out new users on the mailing list.
The main emphasis is on developing data structures in memory format as well as libraries to support high performance in memory analytics or data warehouse workloads. Arrow has been designed to work with different programming languages like Java, C, C++, JavaScript and several others and supports a very flexible data model. You could store simple or very flat data types and go all the way up to complex nested, hierarchical JSON data types.Let’s talk about few goals of the Arrow project. The columnar memory format has become the defacto format for running high speed analytical workloads or data warehouse queries, which typically focus on a subset of columns but a large fraction of rows along those columns like aggregations, joins, or simple scans.Now, the columnar format actually allows the developers to write data processing algorithms for these particular queries in a very CPU efficient and cache conscious manner. That improves the performance of these queries by an order of magnitude.Secondly the columnar format allows us to leverage several hardware performance characteristics like Single Instruction Multiple Data or SIMD instructions that can further accelerate such work loads. Another aspect or another goal associated with Arrow project is interoperability where Arrow can actually act as a centralized data format for data exchange between different processing systems. A few more details about this in the coming slides.If you can take Arrow’s implementation or the in-memory columnar implementation, the data structures and the library in any language you can plug that into any other system like Spark or Impala to build high performance columnar execution engine. These systems can actually leverage the in-memory format as well as the wire format provided by Arrow and build a very high performance querying sequential engine.Thanks to the Arrow community the documentation around the code as well as the design, the format and everything is extremely, extremely good and it is cross language compatible. We pay a lot of emphasis on verifying compatibility between different formslike sending data from Java to C++ or vice versa.In a nutshell Arrow is a standardized, language independent columnar format for running analytical operations in a very efficient manner on modern hardware.Let’s talk a little bit more about the interoperability aspect of Arrow. We have different data processing systems like Spark, Impala, Kudu or Cassandra and each of these systems have develop their own in-memory format, which are tailor made to meet their performance requirements as well as functional requirements. But, when the time comes for these systems to exchange data, they pay a lot of performance penalty around copying the data, converting to the target memory format and the serialization and de-serialization and the same set of steps are repeated on the other end.Now, if these system can be provided with a common format of data, a common in-memory format that each of them can leverage, they can actually avoid all the performance overhead associated with serialization, de-serialization, copying and conversion. As far as the cross system communication is concerned performance can be improved with a standard data format like Arrow. That’s where Arrow can act as a high performance interface for data exchange. The main emphasis with Arrow is CPU efficiency. Basically building data structures and formats for supporting analytical workloads and running them in a highly efficient manner.The traditional OLTP workloads, they benefit from the row format. Basically, they benefit from the fact that a single row is stored in a contiguous fashion. A row and all the column values for the row are stored together in memory or on disk.Now, the data warehouse workloads or the analytical queries, they don’t benefit from such format. Columnar format is a right format for such queries because all the values, all the cells for a particular column are stored together, again, in memory or on disk. This data structure organization actually allows us to write very, very simple and efficient code for query processing algorithms. We can write as simple tight FOR loop code to run through the common values in a very efficient manner and this kind of code will be very CPU efficient as well as cache efficient because you’ll be filling your cache lines with related data. All of the values in the columns are of interest. What you are loading into CPU registers as well as memory is the data of interest. You are basically maximizing and utilizing the CPU memory bandwidth in a very efficient manner. Similarly, compiler helps us a lot along with this data format because such kind of code can possibly be converted into vectorized instructions automatically by compiler if the compiler sees such optimization opportunities during compilation. These opportunities are not available to us when we write query processing algorithm for row oriented data.Arrow in-memory format for columnar data actually allows us to access any cell value in the column in constant time. Any structure overhead that we pay upfront to interpret the metadata and other things.Similarly, columnar format also allows us to use CPU efficient compression schemes that are extremely lightweight and actually favor the performance of query rather than actually favoring the compression ratio, which can hurt your CPU efficiency tremendously.More on the compression later in the coming slides.We have two types of data representation in Arrow for Scalars as well as Complex. Scalars, we have for both fixed width scalars as well as variable width scalars like for example we haver representation all the way from short, tiny and small INT and then eight byte big end or long and then two’s complement decimal representation in a sixteen byte format and then four byte float, eight by double and the multiple different representations for date, time, timestamp, to store different kind of resolutions. For variable width data we have UTF8 or varchar as well as varbinary where each value in the common is of variable width in nature and not fixed width unlike other scalar vectors.Then for Complex, we have struct, list and union. These can together be combined in an arbitrary fashion to represent any kind of hierarchy or nested JSON like data. Like, for example, you can have a list at the top level and inside the list you can have Scalars, which are the leaves. Like for example you can have a list of imps or you can have a list and inside the list you can have a struct, which is again a complex but the struct inside can have scalar vectors like INT and a float. You have a list that’s struct and the struct is of INT and float. That’s how you can actually represent different fields in your dataset, different complex fields in your dataset into corresponding columnar representation in Arrow.Let’s take a few examples to show how we actually translate the data into in-memory columnar representation in our data structures.First example is for a fixed width four byte INT vector. Basically it’s a representation for a four byte integer column where every value in the cell is fixed width four byte in size. There are two buffers to store the column data. First buffer is a validity buffer, which is basically a bit map, data structure to track, which value in the column is null or not. If the bitmap value is one, if its particular value in the position is one, the corresponding value in the column is non-null. If it’s zero, then the corresponding value in the column is null. The actual column values are actually stored in the data buffer. The data buffer, each value in the data buffer is fixed width four byte in size, storing vector column data. In this case as you can see the fourth value in the column is null. In the data buffer it could be garbage, it could anything which we don’t have to interpret because the validity buffers, the bit is not set over there. These two buffers actually make up a in-memory representation of INT vector who represent any kind of a fixed width four byte column.Then we have available width representation on the right hand side where each element in the data buffer is of variable length and size. Along with the validity buffer and the data buffer, we need additional piece of information in a metadata to track the start position, end position of each of the elements in the columns, right?The offset buffer which is again a fixed width buffer where each value in the buffer is of four byte in size and off set buffer stores the … Helps us to find out the length of each value in the variable width column. In this case we have two values in the variable width column. The first is SIDD, which is four bytes in size and the next value is VAISH which is five bytes in size. The offset, the starting offset is zero and the next starting offset is four. That means the length of the first element in the variable width column is four bytes.Then, the next starting offset is nine, that means the length of the second variable width element in the column is five bytes.Notice the fact that here although we have two values in the column the number of positions which have valid data in the offset buffer is actually always one more than the number of column values. This is always true for variable width elements because we need an additional position to track the last offset. If you have ten values in the column, you need to have at least data for 11 positions in the offset buffer, otherwise you will not be able to track the end offset of the tenth element in a variable width column. This is not true for fixed width columns because the validity buffer in the data buffer, they run parallel to each other and there is no concept of offset buffer.Let’s take a slightly more complex example to see how the JSON like data can be represented in an in-memory columnar vectors. Here we have data for two individuals and for each individual we drag information like name, id, and addresses. Name is again a varchar so it can be represented using three buffers like validity, offset and the data buffer as mentioned in the previous slide. Then, ID is again a fixed width column so it can be represented like fixed with four byte INT vectors, as earlier mentioned in the previous slide.The most interesting piece of information over here is the addresses. Each person can have one or more addresses, which indicates that address at the very top is a list, some form of a list. Right?First person has one list, because it has one address. Second person has two lists. Two elements in the list. Sorry, sorry about that. The first person has one element in the list and the second person has two elements in the list. The internal pieces of information inside the list are number and street which form the address information. Inside the list we have struct and inside the struct we track these two numbers which is a number and a street. That’s how we represent this data in a hierarchical fashion. We start with a list and the list has a struct and the struct then has scalars, number and the varchar.Now, let’s see how we actually retrieve the information for each of, the address information for each of these individuals from the list vector. The very top, the list vector has an offset buffer. The offset buffer indicates the number of elements in the list at each position. In this case at the first position we have only … The number of lists are one, right? Because the first person has one address. In the second case the number of … The size is two, right? Because it has two different elements in the list. Right? The first address, and the second address. The offset buffer helps us to track this.If you take the first element the start offset, the next offset is one that means the size is one. Now, we use this information to make a call to the internal vector and the internal vector in this case is a struct vector. What we typically do is, we do a struct vector.get object zero, at position zero. The struct vector delegates the call to internal vectors which in this case happens to be an INT vector as well as a varchar vector. Then the call goes to INT vector but gets zero and the answer is two, which gets the number information for first person.Then you get varchar vector that gets zero, right? In this case because it’s a varchar vector we again have to go to the offset buffer of the varchar vector which tells us that, “Hey, at the first position the length of the variable width field is one byte which his A.” That’s how we get the address information for the first person. You know that this is the only first and the last address because of the offset buffer because it indicated the size of one.In the next case, you see the first start offset if one and the end offset is three. Right? That means the size is two. Here we’ll make two different calls to struct vector. We’ll do a struct vector and get object one and then we’ll do struct vector and get object two. That way we can actually retrieve two different pieces of information, for the address. We’ll do INT vector to get object one. That is four. Then, varchar vector at object one. Here we’ll find out that the length is two bytes because start offset is one and the end offset is three. We get information as CC. The first address information because four and then CC.Then we do strict vector and get object two. Then we get INT, the element in the INT vector position two which is five. Then do the same thing for the varchar vector. Here we find out that the length of the variable width field is at that particular position is three bytes, DDD, so we get the information as, number as five and street as DDD. This forms the second address for the individual.Moving on to Arrow messaging.Basically every Arrow message is responsible for sending enough information over the wire such that at the other end we can decode it completely and reconstruct the table data in memory into Arrow vectors or each vector is represented in memory representation for a column in your dataset, a column or a field in your dataset. Schema basically consists some kind of a metadata describing each of those fields or columns. Right? Typical Arrow message starts with a schema having all the metadata describing each of the columns in your dataset. Now you can choose to encode some columns, one or more columns in your dataset with dictionary encoding scheme. If that is that case then immediately after the schema you’ll have the dictionary. In this case, if the actual record, actual data that, actual table data is at one column and that one column is A B C B A C B, basically here. Care column, right?If the field is dictionary encoded then after the schema we extend a dictionary batch. Having the entire dictionary for the values. The value A in the column is encoded with dictionary value zero. Value B in the column is encoded with value one, and C with two. After the schema we add the dictionary batch to the message and after the dictionary batch we have the actual record batch where, in this case the record batch will be referencing the dictionary values that were a part of the dictionary batch preceding the record batch. The schema dictionary batch along with the record batch forms a single Arrow message.If there is no dictionary batch, that means there are no fields dictionary encoded in your dataset. After the schema immediately there’ll be one or more record batches. We used to put both streaming format as well as file format for Arrow messaging and both these formats have support for randomly accessing any record batch in the stream.Streaming format or file format are basically in similar, it’s just that in the streaming format we can look at it as a sequence of encapsulated messages. At the beginning of message you have some metadata and the length of the metadata which is a fixed width four byte. Then you get the length. Then you get the metadata and then read the message. Then again, you do the same thing for the next message in the stream. That’s how you can actually implement a streaming reader for Arrow messages.This particular slide describes how we construct a record batch when we have to send the table data over the wire. Basically is an enlarged form of the record batches that we have shown on this slide. What goes inside the record batch.Record batch is nothing but basically the actual data, the actual data for the different columns or fields in your dataset. At the end of the day what we’re sending over the wire is a table data. Now, here the table data representation is in the form of Arrow vectors. For each column in a dataset, we have an in-memory Arrow vector. The vector stores the data in one or more buffers.In this case if the data is name, age and then phones, then for the name column we have three buffers because it’s like a varchar vector so we have the validity buffer, the offset buffer and the data buffer. Each of those buffers become the part of the record batch that we’re sending over the wire. Then we add the buffers for the age column which is the validity buffer and the data buffer. Then, similarly we do the phones thing. What we’re sending over the wire is essentially the information that makes up the dataset.Now, for the guy on the other side to be able to reconstruct a record batch in memory in the form of Arrow vectors for each field, we need some metadata. Like, what are the length of these buffers? How many null values are there in each column? All of this information is encapsulated inside the data header. We also send these addresses of all of these buffers because each of these buffers is a physical contiguous chunk of memory, so the validity buffer is a contiguous chunk of memory for name and the offset buffer for name column is a contiguous chunk of memory. The data buffer for name column is a contiguous chunk of memory and so on and so forth.It’s basically a contiguous chunk of memory related to any address space which could be a memory map file or it could be … It could be anything. This allows the entity on the other side to be able to construct a record batch in memory without any copies. With Arrow messaging we support zero copy de-serialization and serialization. That actually provides very, very fast data access.When we are working with complex or nested data types and trying to form the record batch for serializing over the wire what we essentially do is that we traverse the tree in a depth-first manner. Literally flattening the tree, visiting each node, getting the metadata and the information about the buffers at that level and then just adding them to the record batch. It’s like looking at the tree or the vector tree for a typical representation of hierarchical data and then just flattening it out and adding the data and the meta data to the record batch.Because whichever way you look at it whether it’s simple data or complex data, the data is stored in some vectors and those vectors store the data in some physical buffers, one or more buffers and each buffer is a contiguous chunk of memory. What goes over the wire is basically this information.Arrow supports different language bindings. The main goal being cross language compatible. We currently have strong implementations for Java, C++, C, Ruby, Python, and JavaScript. There are several other language implementations in pipeline like are [inaudible 00:23:17].The next set of slides will focus on how we have leveraged Arrow libraries, data structures and columnar in-memory format to build the high performance in-memory execution engine in Dremio.Dremio is a data platform to accelerate the data warehouse or analytical workloads across heterogeneous data formats. Its’ basically a self-service data platform. Our core execution engine is called as Sabot and it’s built entirely on top of Arrow libraries. It is in a very columnar format, it’s wire format and it’s written entirely in Java. We’ll talk about a few things, a few things, a few aspects related to the usage of Arrow inside Dremio like memory management and then majority of the slides will be focused on vectorized query processing, talking about some details, with respect to the design and implementation of some of your vectorized operators like hash aggregation vectorized copy. A few details about how to use compression with respect to vector columnar data and few details regarding the implementation of our vectorized Parquet reader.Let’s talk about the memory management inside Dremio with respect to Arrow. Arrow actually includes a chunk based managed allocator which is built entirely on top of of Netty’s JEMalloc implementation. The main memory management model or allocation model is sort of a tree based model where we start with the root allocator. The root allocator then internally has different child allocators created for different pieces of work. One of the important synaptic that we enforce at the allocator is some sort of a initial reservation and limit. When you create a child allocator, by creation I’m not meaning that allocation of memory, it’s merely creating an allocator object or initiating or the object. You an impose a reservation that, “Hey, this allocator in future should be able to allocate this much of memory safely and this much amount of memory will never be released or given to the parent allocator until the allocator is closed.” This is for the initial reservation synaptic. That, “Hey, I’m safe. This much of memory I should be allocated in future. I don’t want to allocate it upfront but I should be able to allocate in the future if there is a need.”Then, there is a memory limit. Now memory limit generally in systems could be a limit that is imposed by the operating system or it could be a limit imposed by the JVM. This particular case, we are imposing the limits ourselves locally inside the application. Each child allocator or each allocator has a limit on how much of memory it can allocate during its lifetime. It cannot go beyond that.Even if you set an arbitrary limit on some child allocator it is bound to never go beyond the limits set on the parent allocator.We use reference off-heap buffer management. Basically all the memory that comes for storing the data inside our in-memory column, our vectors comes from direct memory. It doesn’t come form the JVM heap to save ourselves from some overhead associated with garbage collection in Java.Now, let’s talk about little bit in how we use these tree based allocation model as well as the initial reservation and memory limit semantic inside Dremio. Each operator in the query plan tree gets it’s own allocator. You have let’s say you have query plan of say eight operators. I don’t know. Some random number. Each operator will get its own allocator with some initial reservation and memory limit. Let’s take the example of external sort operator which is the operator responsible for handling the sort queries with the ability to sort large amounts of datasets and gracefully handling the out of memory conditions because it has the ability to spill data whenever we are running under low memory conditions.At the top level we have a root allocator for the operator. When we setup the operator and the operator execution has to begin, it gets its allocator. There are two main sub components of the sort operator. One is the memory run second is disk run.Memory run is basically responsible for as the incoming batches of data are arriving into the operator, it keeps sorting them in memory and adding them. Basically if the life is good you never run out of memory. What happens is that data keeps arriving into the operator, keeps getting sorted and nothing happens. At the end when all the input has been processed you have all the data sorted and the operator can start outputting the data out of the memory run sub component.We also have a disk run component which manages the spilling. In case we run out of memory, we need to spill the in-memory data which is already sorted. Then once the data has been spilled, we again need to do some sort of processing to load that data into memory, continue with some sort of merge sort or load different streams of data into memory and so some sort of, and we merge in memory and sort the data, finally finish processing and then pump the data out of the operator.But, this doesn’t happen in a straight forward manner because, let’s say you are adding data, the memory run is adding data as it’s arriving into the operator and sorting them. In future you run out of memory, you need to spill, right? The act of spilling, itself requires some memory because you need to copy the data out and then spill it, right?What memory does is in order to guarantee a 100% spill is that as the incoming batches of data are arriving, we know the size of the data because we keep a track of what kind of data types or fields we are working with. It kind of maintains a running maximum of different or the size of the batch that has been arrived. Each unit of work given to the operator as input is a batch, a data batch of some number of records. Memory run keeps track of the largest batch that has been added so far and uses this size to update its initial resolution of the child allocator.Now, how does this help? This helps because in future, if there is a need to spill, the child allocator provided by memory run has the ability to allocate enough memory to copy out the largest batch, largest sorted data batch from memory and spill to disk. That’s how the initial reservation semantic with memory run help us in a very, very real world scenario. Once you have spilled the data to disk the problem is not over because even through … Let’s say you ran out of memory, spilled the memory to disk, “Oh, life is good.” No. Because now you need to make sure that you have enough memory to load that data back into disk and finish your processing. That’s what disk run child allocator does.Again, this child allocator is created off the top root allocator in the sort operator. What this does is that, it keeps a track of how many times we have spilled data to disk. Times as in the number of spill iterations we have done. In each iteration we spill the data in terms of multiple chunks, like multiple byte size chunks. In a singe iteration we may have spilled 10 chunks. Then, each chunk would have a size that went to disk, right? This guy keeps a track of each such iteration and the largest chuck sized that spilled per iteration.Now, what it has to do is, in order to do an end way merge of data, load it back into memory, it has to be able to allocate memory equal to the amount of the largest batch size, largest chunk size built per iteration. Let’s say you have had three or four spill iterations. Each spill iteration we spilled 10 chunks of data. Let’s say the largest chunk size spilled per iteration was W for first iteration X, Y, Z, for second, third, forth iteration respectively. Now in order to do a four way merge of four chunks from each of these iterations we need to be able to reserve a memory, minimum memory equivalent to W+X+Y+Z+ some constant for additional safety.This is how we use these memory reservations, the tree based model, and different semantics to implement an operator that can handle out of memory conditions in a graceful manner.Little bit more about the memory management. In Dremio the data flows through in a pipeline fashion. It flows from one operator to another operator as a set of vectors. We call it a record batch. In this case we have shown two operators scan and aggregation. The dataset happens to have three columns and has one Arrow vector for each of those columns. You have three vectors.A scan operator has done the processing and now the data has done some processing. Now the data or batch has to be fed into the aggregation operator so that it can start the processing. Typical sequel processing, the output of one operator becomes the input of another operator.Now, remember, in the previous slide I mentioned that each operator gets its own allocator. Now, here we are not doing any copy here, right? We are simply transferring the accounting and ownership business for that particular data batch and vectors to the allocator of aggregation operator. The scan allocator has done its job, releases its control and claim on the memory associated with the data batch and these vectors.Now we use the transfer capability that is implemented as part of each vector to just transfer the control, the memory ownership and accounting responsibility of the buffers for each of those three vectors to the allocator of the aggregation operator. There is no data copy effectively needed. It’s just that control is now with the aggregation operator of the record batch.Moving on to vectorized execution. There are typically two models of query execution that are generally mentioned in literature of text for database and implementation. The traditional model is also called as an iterator model or a tuple based model. Each operator in the query plan tree pushes one tuple at a time of the tree. You have a operator at the bottom. It scan, it starts processing the data and then pushing the data up in the operator tree one tuple at a time.Then there is another model which is called as vectorized model. Now, there are two differences here. First the focus has completely shifted from writing query processing or row oriented data to vectorized to columnar format. You have columnar representations where in one column is stored in a contiguous fashion and a vector and the in-memory representation is called as a vector containing fixed number of values from the column.The second difference between the vectorized model and the traditional model is that instead of pushing one tuple at a time up the query plan tree, you basically push a block. A block comprises of different tuples and then those tuples are stored as set of vectors. You may have, a block may comprise of 4000 tuples or 4000 records and they are stored as vectors in a columnar representation. It’s a block of vectors and this is the unit of data that is transported by one operator to another operator as the query execution progress through the query plan tree.Now, there are several benefits of such kind of processing. Firstly when we load the data form disk a single query needs to touch the columns, only that are required by the query because the data is stored in a columnar format. You save a lot on the disk or your bandwidth by just touching the columns that are necessary.Similar theory is applied when you actually process the data in memory and load it into CPU. You are filling your cache lines with related data because each column is stored together. All the values in the column are of interest. Whatever processing you need to do, you can write a simple tight FOR loop and run through the column values in a very, very efficient manner doing filter out the column values, add the column values with another column. This code is going to be far more efficient than loading one tuple at a time and the tuple might have 100 columns and only column out of that might be interest. You are populating the cache with unnecessary data. That’s why such code is very, very less CPU efficient.Let’s take the example. On the left hand side we have the traditional model of the tuple [inaudible 00:36:47]. The scan operator starts getting the input data and starts pushing tuples through the filter operator. Then, the filter operator pushes the qualifying tuples to the aggregation operator. Operator keeps calling next on the operator downstream in the query plan tree. The output of that is that the operator down in the tree starts pushing the tuple up to the operator located above in the tree. That’s how the query execution proceeds.Now, there is severe performance overhead in this execution because just look at the number of function calls that’ll be there. The poor utilization of the disk bandwidth and the CPU memory bandwidth and also about the … On the efficiency associated with the usage of CPU cache. You’re transporting a tuple where as you may need to work only with a set of columns in that tuple. This is definitely a poor way of processing, query processing algorithm especially for data warehouse workloads.On the right hand side now we have instead of pushing a tuple at a time for the query plan tree, we are pushing a block of vectors, each vector has a set of records or fixed no of records or column values. There are as many vectors as there are columns in the dataset. You just keep pushing a batch of these vectors up the query plan tree and this will be the input and output of different operators in the query plan. This approach is far more efficient than the other approach because you optimize or you amortize the cost associated with function calls between different operators like, next, next, next. You’re not pushing million tuples up the tree. You’re just pushing … You’re just reducing the cost by many fold.Let’s talk about how we actually size our vectors. As I said, I think I’ve said this, I’ve mentioned this multiple times in the presentation without explaining it is that a unit of work in Dremio is called as a record batch or data batch or a set which comprises of Arrow in-memory vectors. Each vector is for a field or a column in your dataset and consists of fixed number of records.Let’s say you have a million record dataset. What we will work on at a time is record batch of 4000 records. This is the record batch. This record batch is also the unit of data that flows through the pipeline or the query plan tree from one operator to another operator. Now, there are different kind of mechanics associated with how to fix the no of records in a data batch. It could be one or all the way up to 64 thousands.We have seen that the large batch size like 8000 or 16,000 actually improves the performance because the unit of work increases and the number of times you’ll repeat the processing goes down. But, the larger batch also causes pipe lining problems because you are actually sending extremely, extremely large amounts of data between one operator to another operator. Whereas if you use a smaller batch size like 128 or 256, although the processing on an individual batch will be faster and the amount of the data transferred between the operators is going to be much slower, but because of the sheer number of times that the processing has to be repeated and the volume of objects that will be constructed, the heap overhead of a query just shoots up. That’s why the standard record batch size that we have been working with at Dremio and that is configurable is, record batch size of 4095 records.Now, there is an interesting reason why we do not use a power of two, something as 4096 but we use a power of two minus one, 4095. Because remember that for vectors which use an offset buffer like a variable vector or a list vector the number of valid data positions in the vector are always, in the offset buffer are always one more than the number of actual values in the columns. If we use 4096 record, that means 4096 column values, we will actually end up allocating in the offset buffer for 8192 records because of power of two allocation semantics in Arrow. That’s why we use power of two minus one number of actual column values. That way we will not over allocate the memory required for the offset buffer. Instead we will just allocate memory required for offset buffer for just 4096 values which is exactly what we need.With batch size we actually control the amount of memory that we have allocated for the vectors. In operators like external sort or aggregation or join where we really need to be conscious of the amount of memory that the operator has reserved and the amount of memory that each child allocator has to work with, we can not really allocate memory for vectors without being aware of what is the default memory allocation. You cannot do vector.allocate and leave it to the API to allocate some default memory because at the end of it you can run out of memory because you were supposed to work within certain memory requirements.Carefully configuring the batch size and the number of vectors, number of values in the column vector and then allocating memory appropriately just for those number of records allows us to write our algorithms which are very graceful and are very, very robust.Let’s take an example of how the vectorized query execution leverages SIMD acceleration to further improve the performance of analytical queries. We have data for a simple column. Let’s say it’s just a fixed width column where we have a validity buffer as well as the data buffer. In a single SIMD load instruction we load the data into 128 [inaudible 00:43:27] register. I’m just taking an example of SSE2 SIMD 128 bit register although modern intel processors are equipped with AVX 512 bit SIMD register. But, let’s just for the brevity let’s just take this example. Each value in the column is four bytes in size. That means in the single SIMD load instruction you can load four values from the column into the register. Now, in a single comparison instruction you can do a filter processing. In a single SIMD instruction you can leverage data level parallelism and find of which of these four values are greater than or equal to 100. You can do extremely fast predicate evaluation by using SIMD instruction on columnar values. The output of this SIMD evaluation is kind of a bit mask or an element mask. It’s like basically each value is a 32 bit integer either all ones or all zeros indicating which column value passed the filter or passed the predicate or not. In this case the first second and fourth value passed the filter.But again we now need to find out which of these are null or not null and then finally construct the output. We then take the validity buffer in a single SIMD instruction. We load that validity buffer into the SIMD register and then again flatten it or expand it such that each value is either all ones or all zeros. Then do a single SIMD AND instruction to just do a logical bit wise AND of all the values as the output of the predicative valuation with the validity bits to find out which are the [inaudible 00:45:10] values here. At the end what you get is 100 and then you get 120 as the answer because even though 200 passed the filter in the first SIMD instruction, the second SIMD instruction will give it zero.Now this output can then be fed into a branch free FOR loop, a very, very simple FOR loop and we can just do some brick shifting on that an then construct the output vector. There are no branches needed. It’s going to be extremely fast.This is how SIMD instructions can be used in a very, very simple manner on columnar data to accelerate the processing by an order of magnitude, especially for operations like scan, filter, sum and other operations these can be accelerated by an order of magnitude by using SIMD instructions.Let’s talk about a few details of design and implementation of our hash aggregation operator.In our performance experiments we feel that if we use a columnar format for looking up the hash table or inserting data into the hash table it is actually not very efficient. Yes. Until now I have talked about that, yes, we need to have columnar format for such and such reasons to suit the performance requirements of these workloads. But, yes, there are cases where the performance is kind of suboptimal. What we do is that, even though the overall implementation of the operator is vectorized the hash table actually stores the group by key column data in a row wise format. We get the input data batch in vectors columnar format. Input data batch for hash aggregation comprises of two types of columns. One set of columns is the group by key columns on which you are doing group by, on. The other columns is the aggregation columns like sum, salary, sum, average, min, max, count. Aggregation columns. These are on all of these columns in the data batch, input data batch are in columnar format. It’s the record batch basically of the operator.What we do is that we … First let’s just talk about the group by key columns. Because we discovered that storing them in columnar format is going to hurt our performances, so we first pivot them. We first pivot them into a row wise representation. That hash table is broken into two regions. One is the fixed width contiguous region and the second is the variable width contiguous region.The fixed width contiguous region is stores the row wise representation of all the group by column keys, the fixed width keys. The variable width contiguous region stores the row wise representation of all the variable width group by key columns. We get the input data batch, pivot the columnar data into pivot space which gives you a row wise representation. Then use the row wise representation or the linearized area of bytes to compute the hash on the entire batch of data. We write a simple FOR loop, compute the hash on the entire batch of data and then just loop over them and insert the keys into the hash table.The aggregation columns like sum, min, max and the corresponding columns they are all represented in columnar format. What we do for them is that we form a vector pair. The input vector which is given to us as part of the input record batch and the output vector. Output vector will store the computed values. If you have a input vector is a salary and the aggregation you want to do is sum, then the input vector will be the salary column, actual column and the output column will store the computed values. The summation values for each of the unique keys that are given to us in the group by key columns. At the time of projection the output vector can be directly projected into the result set. That’s pumped out of the operator.Now, this output vector in the aggregation column, is related and associated with the hash table data structure because once we insert the row wise keys into hash table and we get an ordinal … Ordinal is basically an insertion poINT to the hash table. We use a fixed set of bits from that ordinal to determine the address into the output vector of the aggregation to go and accumulate the value. If you have a fixed width key … Let’s say you have a fixed width key as age, value 25 and then you have a variable width key something, I don’t know some text. That forms a one row wise key. You compute the hash on it, insert that into the table, then you get an ordinal. You use some bits from the ordinal to figure out what is the value in the input vector, what is the corresponding salary for this group by key and where to store the summation of salary into the output vector. That’s how these data structure, the row wise representation of the keys and the columnar representation of aggregation columns are connected together to build high performance hash aggregation algorithm.Few more details. You get an input batch. The input batch is comprising of three vectors here plus pivot. Basically by pivoting, you can see different rows. You pivot into row wise format, where you have all the fixed width columns and then you also indicate which value in the column is validity or not.Similarly you have the variable width columns. Because variable width columns you need to track the length of each column. Each variable width column is then preceded by the … Each variable width column data is preceded by the length of that particular data. Again, everything is in row wise fashion. You compute the hash on this, insert into the hash table. Then, use the hash table insertion ordinal to build your aggregation tables which are columnar format. Once the entire input data has been processed you un-pivot. That means you basically un-pivot the row wise representation from the fixed block region and the variable block region in the hash table to where column corresponding columnar representation of the group by keys. Because what hash table has is the unique group by keys. It’s just that they’re in row wise fashion for performance reasons. Un-pivot, construct columnar vectors and then directly project the computed values from the output vector in aggregation columns and then that makes your output result set for the hash aggregation operator.Let’s talk about vectorized copy. In several cases or several pieces of code in Dremio we copy records but we input and output record batches. There are typically two kinds of copiers. The first is a straight copier where we simply leverage the transfer capability, we have implemented over each vector where we simply transfer the memory account in an ownership business from an allocator of one operator to an allocator of another operator without really copying the memory physically. We just use vector to vector transfer.Vector V1, there’s a buffer, your memory ownership is now to vector V1’s another buffer for a different allocator. It’s just that you transfer the data batch. That makes a straight copy. Another copy is when you want to actually copy a specific set of records in no specific order from an input column vector into an output column vector. Now, here we use an additional piece of information, something called as a selection vector data structure. There are two kinds of selection vector data structure. Two byte and four byte.Let’s talk about the two byte data structure. We use the two byte offset to index the input column. Like, which value in the column needs to be copied and then get the source data for the copy and then use this to copy into the output vector. All of this code is written in a very, very C, C++ style. It’s a simple FOR loop, where we directly work with the underlying memory, underlying chunk of memory. We bypass the entire Arrow vector APIs, the function calls associated with them and just directly work with the memory used underneath by the vectors. Then, just simply keep shifting the address window, use the selection vector, the two byte offset to index the input vector data buffer, get the address and then get the target address and then do a simple mem copy using the APIs provided by platform dependent.This way we implement a highly efficient vectorized copy of different types. Both doing a straight copy in which we just transfer the memory accounting and ownership business from one allocator to another allocator and the second copy in which case we actually do a copy specific cell values for one column to another column in a very, very efficient manner.Columnar format actually allows us to leverage very lightweight and CPU efficient compression schemes like general purpose compression schemes which are used heavily in databases and other systems like LZ or ZLIB. They give you phenomenal compression ration but they hurt CPU efficiency because the cost of compressing the data and decompressing the data add up to the query execution time. Columnar data, the focus is always on building high performance query processing algorithms. The focus is on performance and minimizing the runtime, execution time of the query. But, that doesn’t mean we will not use compression, it just means that we have find other optimal overheads.Columnar format allows us to use several lightweight schemes like dictionary encoding, bit packing, run length encoding where there is absolutely to no CPU overhead of using these schemes. Secondly they actually in some cases, they allow us to directly operate on the compressed columnar data. That improves the performance of your queries by an order of magnitude because you don’t have to decompress all the column data upfront before starting the processing.For example you need to do some … You have a scalar column, you have variable width column, right? Now variable width column generally you cannot do SIMD on that. But, because SIMD needs fixed alignment for the values of the column to be loaded into a SIMD register in a single instruction. But, you can use dictionary encoding compression scheme to encode your variable width column values into fixed width dictionary values and then write your query processing algorithm on top of it, on top of the dictionary values. That way instead of working on the actual variable width non-compressed column values, you are working on fixed width dictionary encoded values. We can use different types of information about a column like what is the cardinality of column, whether the column is sorted or not, what is the data type.For example, if the column has a low cardinality we can generally use dictionary encoding because we also do not want to waste a large amount of memory on building the dictionary. That’s why low cardinality columns are favorable for using dictionary compression scheme.Similarly, if you have lots of repeated data values, like 40, 40, 40, 40, 40 and then so on and so forth, you can use simple scheme length like run length encoding to just convert this data from simple column values into triplets. Like, data is 40, starting offset and the run length. How many times the data is repeated.Let’s take an example on how we use dictionary encoding on the variable width column values. You have column values which, the unique column values are United States, China, India, France, United Kingdom, which are variable width in nature. You need to write a query which does a filtering on that or a predicate evaluation on that. What we do is that we dictionary encode this column. On the left hand side we show the dictionary values. [inaudible 00:57:53] we show the encoded values and columns using the dictionary.The query comes as the select something from the table where country is equal to France. Now, we use France to consult the dictionary and get the dictionary encoded value which is four. We then load four in a single SIMD instruction into a SIMD register. We load all the encoded column values, the dictionary encoded column values in a single SIMD instruction into a SIMD register, that you have loaded all the two, five, four, three, one, seven, values in a SIMD register and just do a parallel predicate evaluation or parallel compare by single SIMD instruction.This way you can actually rewrite as a I mentioned in my previous slide, the rewrite filter on strings as filter on fixed dictionary values. This is the power of dictionary encoding. You can actually compress your variable width column values into fixed width dense arrays and then rewrite your query processing algorithms that can just quickly loop through those compressed column values in a very efficient manner. Directly operating on compressed data you are decompressing only the necessary data.Dremio uses materialized views to cache information basically the information that can be used to accelerate subsequent queries or queries in the future and those materialized views are stored in columnar format on disk. We leverage the Parquet’s columnar format. But when we have to run a query then materialized view has to be used for the query, we load the data from columnar format on disk in Parquet to the corresponding columnar format in memory into Arrow.Our initial reader for this was actually based on a row oriented format. It was basically a row wise reader where it was not at all taking advantage of the fact, the source data on disk is also columnar in fashion and the target data that we are trying to build in memory is also columnar fashion. Then, we rewrote the algorithm, reader algorithm to be completely vectorized where the processing is done one column at a time and then it is highly, highly efficient because we can completely take advantage of what are the compression schemes that we have used in Parquet for each column and sometimes even do a bulk copy by decoding those compression schemes in an efficient manner and then reading each column based on the way it has been compressed into a Parquet page.Now, the new reader does columnar operations while reading and writing Parquet files. We also support filter push down for Parquet scans. The predicates or the filters indicated in the query can directly be pushed down to the Parquet files such that we only load the necessary column data into memory when reconstructing the Arrow in memory vectors.Let’s talk about late materialization. The main idea is to work on the columnar format till late in the query plan. Yes, I have been suggesting that why storing data, storing data in a columnar format is essential to building high performance analytical query engines. But, the idea is not to just read the columnar data and stich the values together to perform a row store operations on tuples. The idea is to keep the columnar format till very late in the plan and avoid constructing tuples only when necessary. This actually improves the utilization of memory bandwidth because you can keep operating on the columnar format as long as necessary. Right? Do filter processing, scans on one columns at a time in simple efficient FOR loops. You can even use SIMD processing when operating on a particular column.Whereas if you do not do this and if you construct tuples upfront, you’ll lose the opportunity of using SIMD acceleration. Similarly, when you are constructing tuples upfront you have to decompress all the values and you may not have even needed those values. You are actually forming unnecessary tuples.With late materialization, you keep operating on the columnar format till as late as possible. You get several advantages. You can keep operating on compressed columnar data, of course if it allows. For example, dictionary encoding allows us to operate on fixed width and variable width compressed columnar data. You can keep doing that and then only, you can form the tuples only when are necessary. You decompress only the necessary data values. This improves a lot on the utilization of memory bandwidth.Secondly when you do this, you have to use some intermediary data structures. For example, the query is, filter on one column and then project on other column. One way to do this is either you read both the columns, stich the values together, form tuples and then start feeding into your operator. But, that is very less efficient because you just need to do filter processing on operator and need to project the other operator. Why not just keep the filter column in a columnar format, process them very quickly, construct intermediary list or a selection vector to find out which of the values pass the filter and then use those in that intermediary list to then process the target column for projection and then project the necessary values. You never constructed unnecessary tuples. You potentially operated on compressed columnar data. You potentially had the opportunity to leverage SIMD and then finally you only projected the necessary values, you never form any tuples. You only formed the necessary tuples.Late materialization along with the ability to directly operate on compressed data, opportunity to use SIMD at appropriate points heavily improves the utilization of memory bandwidth as well as the performance of our queries.Let’s talk about how Arrow in-memory format allows us to un-nest list vectors. There are some cases in which we want to unroll the lists to separate records in the dataset. You have a list of several different records. That list vector has an inner vector and the inner vector could again be a complex vector or a scalar vector. In this case the list vector has a struct vector and the struct vector has three scalars inside the inner vectors. The memory representation in the data structure format is such that we literally don’t have to do any data copy over here. Each vector has been provided with the ability of doing a split end transfer, where a set of records from the vector from the vector can be quickly copied or transferred, I would say, that, transferred to another set of records in a different vector. What we are doing over here is that we take each of the buffers for the inner vector, form a slice, the start point of split and the length of the split and just do a buffer transfer to the target allocator of another vector. This enables a very, very efficient un-nesting of values from the list into separate different records as different vectors.That’s it. Please try to get involved with the Arrow community. We have a Slack channel. Please follow us on Twitter. These are my handles. These are the handles or Apache Arrow, the Dremio HQ and myself. Also please join the Arrow community, the Dremio community. Go to our link and sign up for the community addition and start playing around.




