8 minute read · August 6, 2024
Getting Hands-on with Snowflake Managed Polaris
· Senior Tech Evangelist, Dremio

In previous blogs, we've discussed understanding Polaris Catalog's architecture and getting hands-on with Polaris Catalog self-managed OSS; in this article, I hope to show you how to get hands-on with the Snowflake Managed version of Polaris Catalog, which is currently in public preview.
Getting Started
To get started, you'll need a Snowflake account; if you don't already have one, you can create a trial account for free at snowflake.com.
Once you have an account, head over to the "Admin" section, and you can add another account and you'll see the option "Create Polaris Account".

The account will be added to the list of accounts, and you'll want to copy your locator ID (the URL associated with this account) somewhere so you can access it when you need it. You'll find this under the "locator" column in the list of accounts.

Take that URL and open it in another URL to access the Polaris management console logging with the credentials you created when you created the Polaris account. Then, you'll click on "catalogs" and create a new catalog, which will open a dialogue box that looks like this.
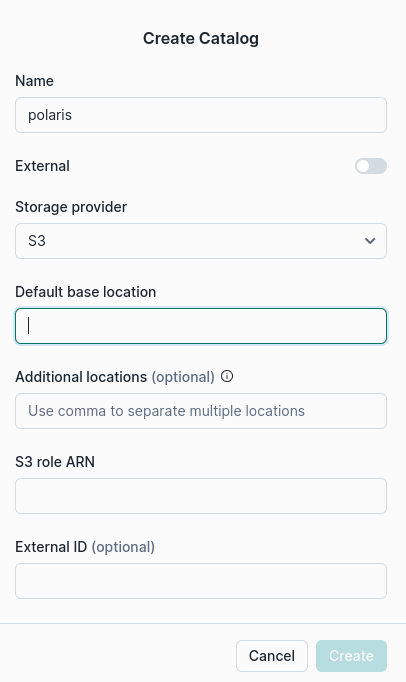
Then, fill out the fields with an S3 path where you want data stored under "default base location" and an ARN for a role with read/write access to that bucket.
Then, you'll want to click on the catalog in the list of catalogs and create a catalog role and assign that role that CATALOG_MANAGE_CONTENT privilege. Then head over to the "roles" section under "connections" and create a principal role then head back to the catalog and assign the principal role the catalog role you created earlier.
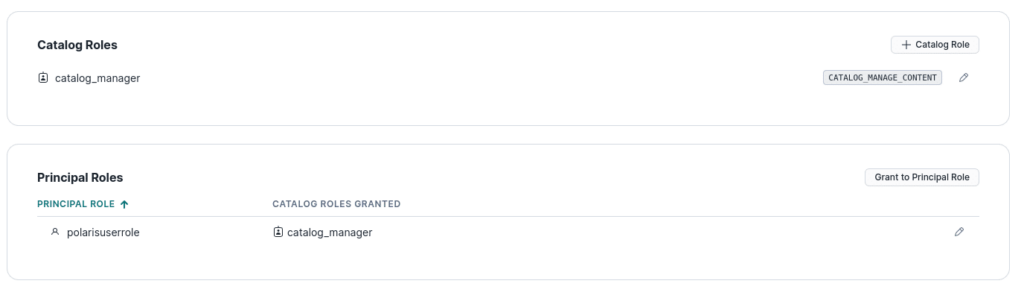
Once this is created, create a new connection/principal and assign the principal role you created to the new connection (for this demo, not for production). Afterwards, you'll get the credentials for this user; Make sure to copy this over somewhere you can access it for later.

Now, the catalog is set and can be used from Snowflake as an external catalog, as documented here. It is also possible to use the Polaris catalog with other engines that support the Apache Iceberg REST Catalog, like Spark.
Trying Out Our Catalog in Spark
You can spin up spark on your laptop with the following command.
docker run -d \ --platform linux/x86_64 \ --name spark \ -p 8080:8080 \ -p 7077:7077 \ -p 8888:8888 \ -e AWS_REGION=us-east-1 \ -e AWS_ACCESS_KEY_ID=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \ -e AWS_SECRET_ACCESS_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \ alexmerced/spark35notebook:latest
Keep an eye out for the URL to access our python notebooks in the out put that should look like:
http://127.0.0.1:8888/lab?token=5ca0733a9874062c80bc0227c66011f121bd287279d5093a
Then in Pyspark you should be able to run code like the following:
import pyspark
from pyspark.sql import SparkSession
import os
## DEFINE SENSITIVE VARIABLES
POLARIS_URI = 'https://xxxxxxxxxx.snowflakecomputing.com/polaris/api/catalog' # Locator URL From Snowflake
POLARIS_CATALOG_NAME = 'polaris'
POLARIS_CREDENTIALS = 'xxxxxxxxxxxx:yyyyyy' #Principal Credentials accesskey:secret
POLARIS_SCOPE = 'PRINCIPAL_ROLE:ALL'
conf = (
pyspark.SparkConf()
.setAppName('app_name')
#packages
.set('spark.jars.packages', 'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.5.2,org.apache.hadoop:hadoop-aws:3.4.0')
#SQL Extensions
.set('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions')
#Configuring Catalog
.set('spark.sql.catalog.polaris', 'org.apache.iceberg.spark.SparkCatalog')
.set('spark.sql.catalog.polaris.warehouse', POLARIS_CATALOG_NAME)
.set('spark.sql.catalog.polaris.header.X-Iceberg-Access-Delegation', 'true')
.set('spark.sql.catalog.polaris.catalog-impl', 'org.apache.iceberg.rest.RESTCatalog')
.set('spark.sql.catalog.polaris.uri', POLARIS_URI)
.set('spark.sql.catalog.polaris.credential', POLARIS_CREDENTIALS)
.set('spark.sql.catalog.polaris.scope', POLARIS_SCOPE)
.set('spark.sql.catalog.polaris.token-refresh-enabled', 'true')
)
## Start Spark Session
spark = SparkSession.builder.config(conf=conf).getOrCreate()
print("Spark Running")
## Run a Query
spark.sql("CREATE NAMESPACE IF NOT EXISTS polaris.db").show()
spark.sql("CREATE TABLE polaris.db.names (name STRING) USING iceberg").show()
spark.sql("INSERT INTO polaris.db.names VALUES ('Alex Merced'), ('Andrew Madson')").show()
spark.sql("SELECT * FROM polaris.db.names").show()Conclusion
Keep in mind that Polaris is in the early stages of public preview, so there may be imperfections and troubleshooting as it gets refined. But hopefully, this will help you on your journey to getting started with Polaris at these early stages.
As mentioned in this Datanami article, some of the open-source Nessie catalog code may find its way into Polaris. Below are some exercises to get hands-on with Nessie and learn about what may be in store for Polaris's future.
Here are Some Exercises for you to See Nessie’s Features at Work on Your Laptop
- Intro to Nessie, and Apache Iceberg on Your Laptop
- From SQLServer -> Apache Iceberg -> BI Dashboard
- From MongoDB -> Apache Iceberg -> BI Dashboard
- From Postgres -> Apache Iceberg -> BI Dashboard
- From MySQL -> Apache Iceberg -> BI Dashboard
- From Elasticsearch -> Apache Iceberg -> BI Dashboard
- From Kafka -> Apache Iceberg -> Dremio
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->