9 minute read · June 10, 2024
What is Data Virtualization? What makes an Ideal Data Virtualization Platform?
· Senior Tech Evangelist, Dremio
Data virtualization allows you to interact with multiple data systems through a single interface, treating them as a unified system. This capability lets you view all datasets across various systems and execute queries that utilize data from multiple sources simultaneously. This reduces the traditional need to move data across multiple systems to eventually make use of them in a data warehouse increasing the time to insight.
While data virtualization offers numerous benefits, it also presents certain challenges. In this article, we will explore both the advantages and the obstacles and discuss how the Dremio Lakehouse Platform enhances the value of virtualization by integrating features that support Lakehouse and Mesh architectures seamlessly.

Benefits Of Virtualization
Data virtualization systems offer a myriad of benefits that can significantly enhance data management and utilization within an organization:
- Unified Data Access: Data virtualization eliminates the need for multiple ingestion connectors and integrations by providing a single interface to access multiple data sources. This unification simplifies data retrieval and allows for more efficient data operations.
- Real-Time Data Integration: Data virtualization enables real-time access to data across different systems without data replication. This ensures that users always work with the most current data, improving decision-making and operational efficiency.
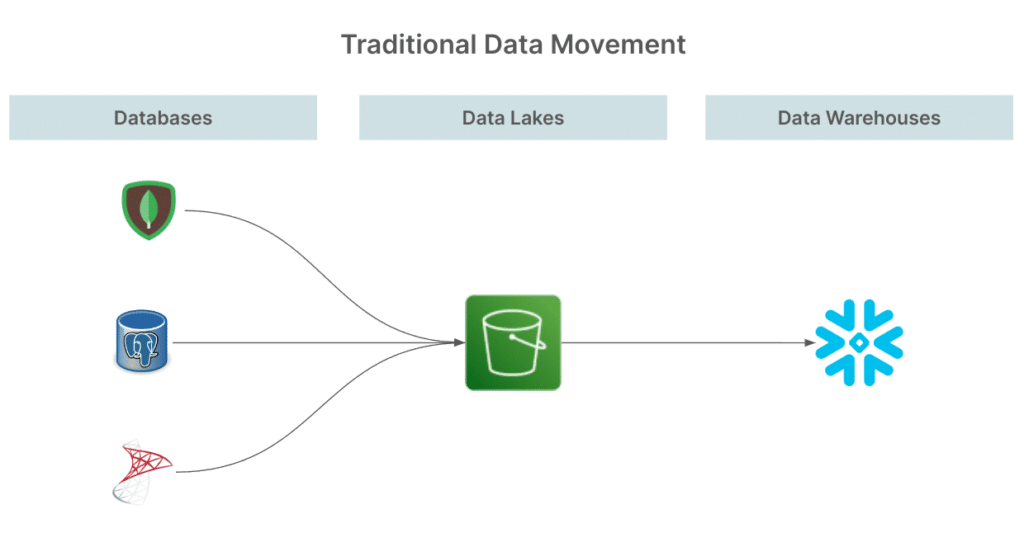
- Cost Efficiency: Data virtualization helps lower infrastructure and maintenance costs by reducing the need for extensive data movement and storage. Organizations can leverage their existing systems without investing heavily in new hardware or storage solutions.
- Enhanced Data Governance: With data virtualization, organizations can enforce consistent data governance policies across all data sources. This ensures data quality, security, and compliance, regardless of where the data resides.
- Improved Agility: Data virtualization allows organizations to quickly adapt to changing business needs by providing agile data access and integration. New data sources can be incorporated into the virtualized environment without significant changes to the underlying infrastructure.
- Simplified Data Management: Managing data across multiple systems can be complex and resource-intensive. Data virtualization simplifies this process by centralizing data access and management, reducing the burden on IT teams.
By leveraging these benefits, organizations can achieve a more streamlined, cost-effective, and agile data management strategy, ultimately driving better business outcomes.
Challenges when using Virtualization
Despite the numerous benefits, data virtualization systems come with their own set of challenges that organizations must address to fully leverage their potential:
- Performance Issues: Combining and querying data from multiple sources in real time can lead to performance bottlenecks. Ensuring that queries run efficiently across disparate systems may require robust monitoring, optimization, and tuning.
- Scalability: As data volumes grow and more data sources are added, scaling a data virtualization solution to handle increased load can be challenging. Organizations must ensure that their data virtualization platform can scale efficiently without degrading performance.
Many platforms just push down queries to connected sources, which creates competing demands on source systems as they handle operational and analytical queries. Dremio's unique architecture overcomes this challenge, enabling data virtualization at scale.
Dremio Enables Virtualization at Scale
Dremio offers exceptional speed for data lakehouse queries with its infinite scalability and Apache Arrow processing. Dremio’s Apache Arrow processing will still give you industry-leading performance when dealing with non-lake sources. Although, you can deal with excessive query pushdowns by leveraging Dremio's unique Reflections feature. Reflections allow you to create optimized Apache Iceberg representations of frequently accessed data behind the scenes. Dremio will transparently substitute these optimized representations, eliminating the need to push down many queries and improve performance and scalability.
The best part of this feature is its transparency. Users can query the original database and data warehouse tables without even being aware of using Reflections in the query execution. This is distinct from many other virtualization platforms that may employ materialized views, which create new namespaces that analysts must explicitly query or they may use indexes to optimize performance, which only work on certain types of tables and sources, leaving you dependent on the type of data you're virtualizing.
This feature is able to operate uniquely because Dremio offers more than a data virtualization platform; it is also a data lakehouse and semantic layer platform.
Data Lakehouse: As data lakehouse platform, Dremio can query your data lake storage efficiently but more so its able to leverage your data lake storage for advanced acceleration like reflections.
Semantic Layer: By defining your data metrics and data views within Dremio, Dremio understands the relationship between all the accessible objects, enabling Dremio to identify when created reflections can be transparently swapped. This allows acceleration to be independent of the tool you use to deliver your report, dashboard, or application, allowing multiple use cases for the same data to benefit from the same acceleration.
Dremio's unique approach removes the primary roadblocks to virtualization at scale while retaining all the governance, agility, and integration benefits.
Conclusion
Data virtualization enables seamless access to and querying of datasets across various systems, significantly reducing the traditional need for data movement and accelerating the time to insight.
While data virtualization offers numerous benefits, such as unified data access, real-time integration, cost efficiency, enhanced governance, improved agility, and simplified management, it also presents challenges like performance issues and scalability concerns. Addressing these challenges requires advanced technology and strategic implementation.
Dremio's Lakehouse Platform stands out by effectively addressing the complexities of data virtualization. Its unique architecture supports efficient query processing tailored to different data sources. Dremio's infinite scalability and Apache Arrow processing ensure blazing-fast performance for data lakehouses. Dremio's Reflections feature optimizes query performance for non-lake sources by creating and using Apache Iceberg representations of frequently accessed data, eliminating the need for many query pushdowns.
This transparent optimization allows users to interact with the original database and data warehouse tables without being aware of the underlying enhancements, unlike other platforms that rely on materialized views or indexes, which can complicate user interactions. Dremio's approach removes primary roadblocks to virtualization at scale while maintaining all the governance, agility, and integration benefits. Get started with Dremio today!
Here are Some Exercises for you to See Dremio’s Features at Work on Your Laptop
- Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
- From SQLServer -> Apache Iceberg -> BI Dashboard
- From MongoDB -> Apache Iceberg -> BI Dashboard
- From Postgres -> Apache Iceberg -> BI Dashboard
- From MySQL -> Apache Iceberg -> BI Dashboard
- From Elasticsearch -> Apache Iceberg -> BI Dashboard
- From Kafka -> Apache Iceberg -> Dremio
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->