13 minute read · May 28, 2024
The Who, What and Why of Data Reflections and Apache Iceberg for Query Acceleration
· Senior Tech Evangelist, Dremio
The quest for speed and efficiency is paramount, yet traditional approaches like materialized views, OLAP cubes, and BI extracts often fall short. While useful, these solutions can introduce complexities in maintenance, lead to increased storage costs, and suffer from latency issues that can hinder real-time decision-making. Recognizing these challenges, this article delves into an innovative solution: Dremio's Reflections. This feature promises to simplify data architecture by eliminating the problems of the previously mentioned solutions and enhancing query performance, thus redefining how data-driven organizations achieve analytical efficiency. Through a deeper exploration of Dremio's Reflections, this article aims to illuminate their operational mechanics, benefits, and the significant edge they offer over traditional methods.
What are Data Reflections?
Data Reflections in Dremio leverage the platform's sophisticated semantic layer, which intimately understands both raw datasets and their derived views. When a Reflection is created, it generates an Apache Iceberg-based representation of the data within the data lake configured in Dremio. Subsequently, when this dataset or its child views are queried, Dremio assesses each associated Reflection to determine if using it could yield faster query results. If beneficial, Dremio substitutes the queried dataset with the Reflection for execution, enhancing performance significantly. The benefit doesn’t just come from the optimized physical data structure but also the planning benefits that Apache Iceberg metadata provides on that optimized structure.
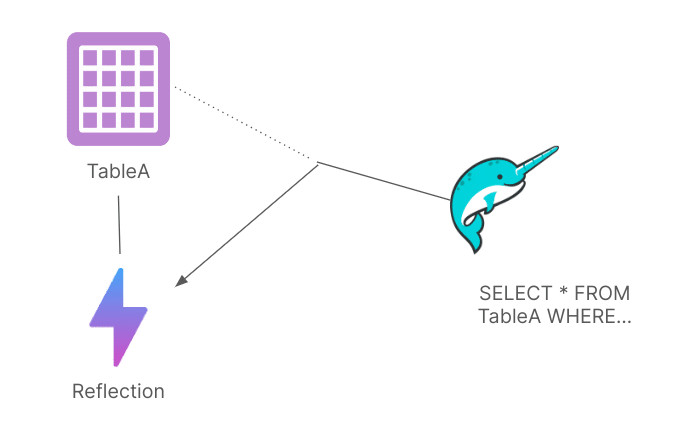
Creating Reflections is straightforward and facilitated by Dremio's user interface with a few clicks or by sending Dremio SQL via REST API, JDBC/ODBC, or Apache Arrow Flight. Once established, Dremio automatically updates the Reflection regularly, simplifying the data engineer's responsibilities. This automation allows analysts and data scientists to focus solely on their queries without the burden of remembering multiple versions of the same dataset. Dremio intelligently selects the optimal representation for each query, streamlining the process and ensuring efficient use of data acceleration. Moreover, due to Dremio's awareness of dataset relationships, Reflections can accelerate queries not only on the primary dataset but also on its child views, thereby extending the benefits of existing Reflections.
Here is some examples of SQL used to create a reflection:
Raw Reflection
ALTER TABLE Sales."customers"
CREATE RAW REFLECTION customers_by_country USING DISPLAY (id,lastName,firstName,address,country)
PARTITION BY (country)
LOCALSORT BY (lastName);Aggregate Reflection
ALTER TABLE Samples."samples.dremio.com"."zips.json" CREATE AGGREGATE REFLECTION per_state USING DIMENSIONS (state) MEASURES (city (COUNT)) LOCALSORT BY (state);
Types of Data Reflections?
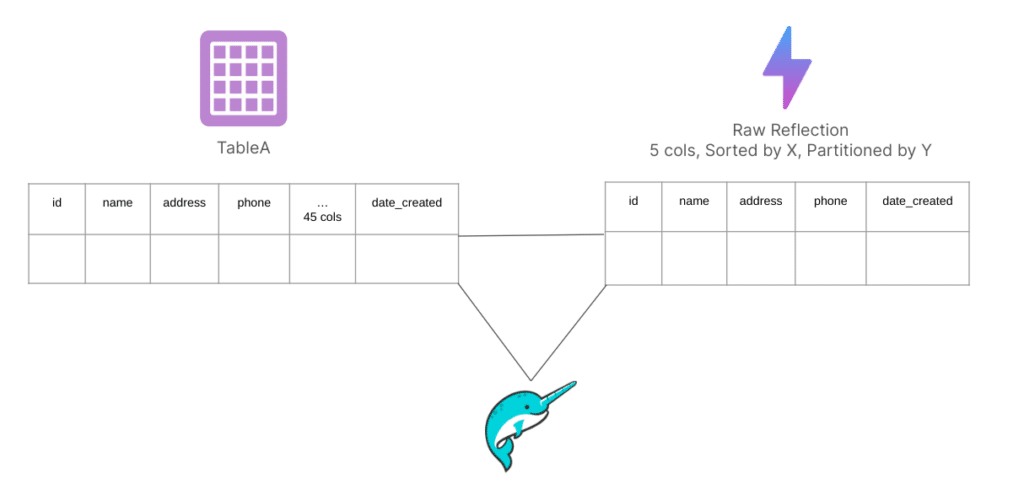
Dremio supports two primary types of Reflections—Raw and Aggregate—each serving distinct optimization purposes. Raw Reflections, akin to materialized views, do not necessarily materialize entire datasets. Instead, they provide the flexibility to selectively materialize specific columns, while also allowing custom sorting and partitioning rules. For instance, consider a table with 50 columns of unpartitioned voter data. Typical queries might only involve a subset of columns focused on voters from a specific state or party. In such cases, you could create two separate Raw Reflections: one partitioned by state and another by party, each reflecting only the five relevant columns. This targeted approach significantly reduces the storage footprint compared to materializing all columns, optimizing resource usage and query performance.
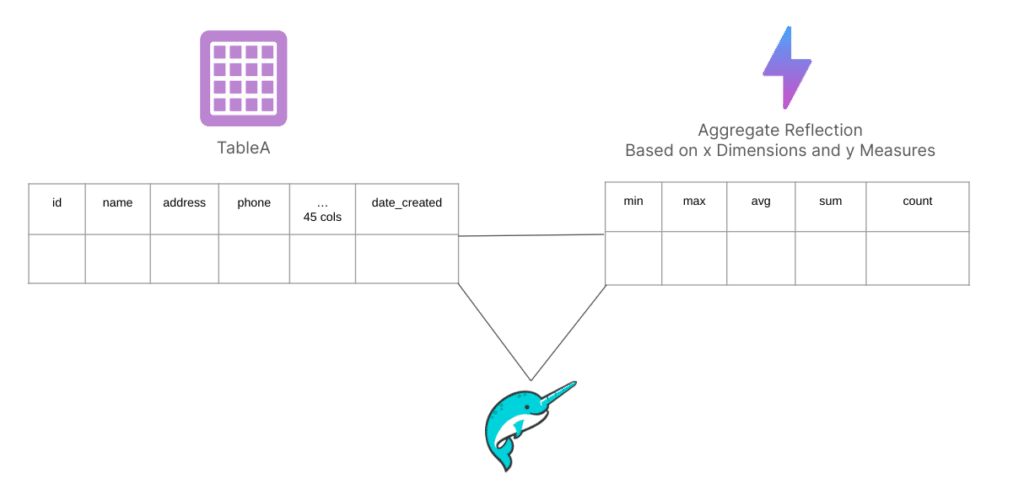
Aggregate Reflections, on the other hand, are similar to OLAP cubes and are designed to pre-compute and store aggregated data based on specified measures and dimensions. This setup is particularly effective for optimizing queries that include GROUP BY operations, commonly used in BI tools, thus drastically speeding up response times to near-instantaneous levels.
Additionally, Dremio introduces a feature known as External Reflections, which allows for the manual creation of materializations outside of Dremio. These external datasets can then be registered within Dremio and used to accelerate queries against specific datasets, further enhancing the flexibility and performance of Dremio’s data management capabilities. Finally, Dremio has Starflake Reflections, which are reflections on Star or Snowflake schemas that can be used to accelerate any join permutation of the underlying fact tables.
When to Use Reflections
Reflections in Dremio can be beneficial in several scenarios, enhancing performance and simplifying data architecture:
- Minimizing Pushdowns: When Dremio connects to external databases or data warehouses, it typically pushes down initial queries to these source systems. Dremio can eliminate the need for these pushdowns by creating reflections on the datasets. This is particularly beneficial for source systems that also serve operational purposes, as it helps scale them without overloading them with analytical queries.
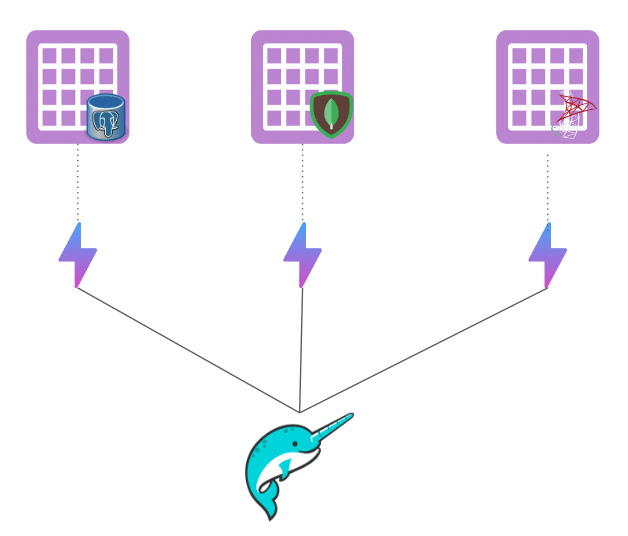
- Materializing Joins: Joins can be resource-intensive, especially across different sources. Instead of reflecting individual source tables, a view representing a join can be a valuable alternative. For example, if `view_a` represents a join of two tables and is the basis for `view_b`, `view_c`, and `view_d`, reflecting `view_a` can accelerate queries across all four views, simplifying the data handling and improving performance.
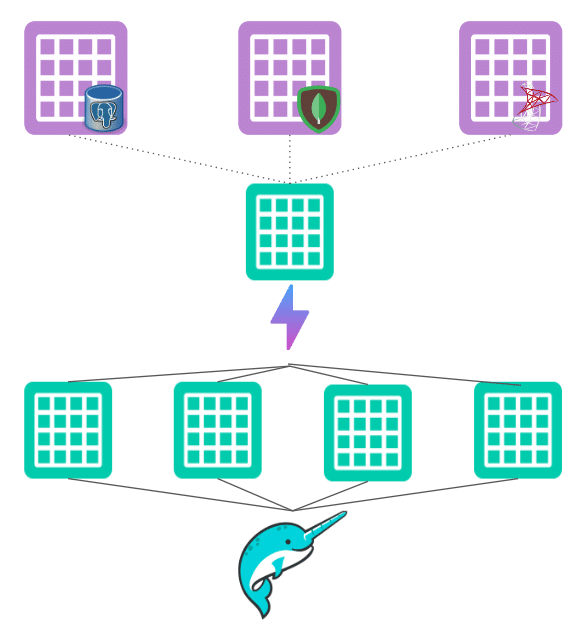
- Speeding up Dashboards: Traditional BI extracts and cubes can be cumbersome and slow. By creating an aggregate Reflection on datasets used for BI dashboards, you can avoid these pitfalls. Aggregate Reflections streamline data processing, speeding up dashboard performance dramatically.

- Reflections as ETL: In scenarios where data flows from raw layers to transformed (silver) and then to business-logic-driven (gold) layers, reflecting the gold layer can effectively replace intermediate ETL processes. This setup means that as Reflections are refreshed, they serve as batch ETL jobs, thereby streamlining the data pipeline and reducing the overhead of traditional ETL tasks.
Utilizing Reflections in these ways maximizes data query efficiency and optimizes overall data management within Dremio's ecosystem.
The Cutting Edge of Data Reflections
Dremio has consistently invested in enhancing the capabilities of its Reflection technology to optimize query performance and reduce operational costs. A notable advancement is the introduction of a Reflection Recommender. This tool proactively suggests reflections that can accelerate query speeds, lower costs and improve efficiency. Additionally, Dremio has developed Incremental Reflections, which update datasets selectively based on changes in the data. This method significantly reduces the resources and time required for updates, leading to faster and more cost-effective data management.
Looking forward, Dremio is poised to introduce further innovations in Reflection technology. These enhancements aim to foster an environment of autonomous query acceleration, minimizing manual oversight and maximizing performance within the data lakehouse architecture. Such advancements are set to streamline processes, ensuring that data-driven insights are delivered quickly and efficiently.
What makes them different?
While many query engines and data lakehouse platforms offer query acceleration features, Dremio's Reflections stand out due to their flexibility, accessibility, and integration, addressing several common challenges faced by other platforms:
- Universal Compatibility: Unlike some virtualization platforms that restrict acceleration features to specific data sources, Dremio's Reflections are versatile, functioning with any data source configured within Dremio.
- Accessibility for All Users: Some platforms reserve acceleration tools for enterprise-tier users only. In contrast, Dremio's Reflections are accessible even in the free community edition, democratizing advanced data processing capabilities.
- Simplified Namespace Management: Traditional platforms might rely on Materialized Views and Cubes, which can complicate namespace management and require additional maintenance. Dremio's Reflections refresh on an adjustable schedule and operate seamlessly within existing namespaces, enhancing manageability and reducing overhead.
- Native Integration: While other platforms may acquire external technologies to provide acceleration, often necessitating additional infrastructure like separate clusters, Dremio’s Reflections are natively integrated within its core engine, eliminating the need for extra computational resources.
- Deployment Flexibility: Dremio's Reflections are robust, supporting diverse deployment scenarios whether on-premises or in the cloud. This contrasts with some platforms that limit acceleration features to specific deployment types.
- Cross-Tool Efficiency: Traditional BI tools may require separate acceleration setups, leading to redundant team effort. Dremio’s Reflections are managed centrally within the data lake and benefit all users, regardless of the BI tool employed. This means if multiple teams use different BI tools to build dashboards on the same dataset, they all benefit from the same set of Reflections.
Dremio’s approach enhances performance, simplifies management, and extends the benefits of acceleration features across a broader range of scenarios and users.
Conclusion
We've journeyed through the landscape of traditional data processing solutions and their limitations, including materialized views, OLAP cubes, and BI extracts. These methods, though functional, often lead to increased storage costs, maintenance complexities, and latency issues that can impede real-time decision-making. Dremio's Reflections are a groundbreaking alternative that promises to simplify data architecture by eliminating these challenges and enhance query performance significantly.
Dremio's Reflections utilizes the platform's advanced semantic layer to intelligently manage data, creating efficient Apache Iceberg-based representations that streamline and accelerate data querying processes. Whether through raw or aggregate Reflections, Dremio ensures optimal data utilization, facilitating rapid and cost-effective data management. This capability extends across various operational scenarios, from reducing pushdowns in external databases to optimizing ETL processes, thus demonstrating Reflections' versatility and effectiveness.
Moreover, introducing features like the Reflection Recommender and Incremental Reflections showcases Dremio's commitment to continuous innovation, aiming to foster an autonomous environment for query acceleration within the data lakehouse architecture. By addressing common constraints of other platforms and providing robust, flexible solutions accessible to a broad range of users, Dremio's Reflections not only meet but exceed the needs of modern data-driven organizations, ensuring that they remain at the forefront of analytical efficiency.
As we look forward to further advancements, Dremio's Reflections are set to redefine the data processing standards, proving that the quest for speed and efficiency in data analytics can be successfully achieved.
Get hands-on with Reflections, dremio-dbt and Git for Data with this exercise.
Sign up for AI Ready Data content
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Dremio Blog: Product Insights,
Learn More ->

BLOG
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.
Dremio Blog: Product Insights,
Learn More ->

BLOG
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights, Dremio Blog: Product Insights,
Learn More ->