25 minute read · January 18, 2024
Using dbt to Manage Your Dremio Semantic Layer
· Senior Tech Evangelist, Dremio

Accessing, analyzing, and managing vast amounts of information efficiently is crucial for thriving businesses. Dremio, as the premiere data lakehouse platform, enables efficient access to data across multiple sources, teams, and users. One of its core strengths lies in providing robust, unified, self-service access to data through a single, cohesive platform. Dremio's semantic layer is a key to its effectiveness, a critical component that streamlines and simplifies data management, ensuring consistency and reliability across various data analysis tools. The popular data transformation and orchestration tool can be very useful in helping consistently curate and update your Dremio semantic layer.
Understanding Dremio's Semantic Layer
At its core, the semantic layer in Dremio serves as a unified data abstraction layer. It allows users to define standard business logic and data models, which can be used consistently across multiple applications and analytics tools. This approach enhances data governance and security and significantly reduces the complexity and time of accessing and analyzing data. By leveraging Dremio's semantic layer, organizations can achieve a more agile and flexible data architecture, enabling them to adapt quickly to changing business needs. A robust platform is created when combining Dremio’s data virtualization/federation features connecting many data sources, and Dremio’s semantic layer features which allow you to curate that data in a logical model together.
The Role of dbt in Crafting the Semantic Layer
dbt (data build tool) complements Dremio's capabilities. dbt is an open source tool that allows data analysts and engineers to transform and model data using software engineers' practices for application development. It enables the transformation of raw data in your data platform into a structured, queryable format, which is crucial for analytics and business intelligence.
Benefits of Using dbt with Dremio
Enhanced data transformation: dbt facilitates efficient and sophisticated transformations, enabling users to turn raw data into meaningful insights. This process is integral to creating a robust semantic layer in Dremio.
Version control and collaboration: dbt models are written as code and can benefit from using Git and GitHub for versioning, CI/CD, and collaboration, features that are essential for maintaining the integrity and consistency of data models in a team environment. Pair this with the data versioning, observability, and lakehouse management features of Dremio-managed data catalogs, and you get a powerful combination.
Streamlined workflow: Integrating dbt with Dremio streamlines the entire data processing workflow. This integration ensures a seamless and efficient pipeline for data operations. With its model DAG, dbt can run independent queries faster in parallel and react to errors dynamically.
Scalability and flexibility: dbt's architecture is designed for scalability, making it an ideal choice for organizations looking to grow their data infrastructure. It easily adapts to changing data volumes and business requirements. With its model selection syntax, dbt makes it easy to redeploy changes to small subsets of the semantic layer
Community and ecosystem: Being open source, dbt has a strong community and ecosystem, providing a wealth of resources, plugins, and integrations that enhance its functionality.
Combining Dremio's powerful data lakehouse platform and dbt's robust data transformation capabilities creates an unparalleled environment for crafting an effective semantic layer. This synergy allows organizations to manage their data more efficiently, make more informed decisions, and ultimately gain a competitive edge in the marketplace.
Getting Set Up: Integrating dbt with Dremio Cloud
Once you understand the benefits of using dbt to manage your Dremio semantic layer, the next step is setting up your environment. This process involves creating a Dremio Cloud account, adding data sources, and configuring your local development environment to work with dbt and Dremio. Let’s walk through these steps in detail.
1. Create a Dremio Cloud account
The first step is to set up your Dremio Cloud account. Dremio Cloud is a fully managed service that simplifies data engineering and accelerates analytics. If you want to try this exercise using Dremio software on your laptop follow this guide to spin up Dremio from your laptop.
During account creation, you’ll name your project default catalog; it will be used later.
You will be prompted to connect your AWS or Azure account during the setup process. This integration is crucial as Dremio Cloud leverages your cloud storage (like S3 buckets in AWS or Blob Storage in Azure) to store and manage data.
2. Add the sample source
After your Dremio Cloud account is ready, you need to add data sources to it:
In Dremio Cloud, navigate to the “Add Source” section.
Here, you can add a variety of sources, but for starters, choose the “Sample” source. This will give you access to sample datasets provided by Dremio, which are great for testing and exploration.
You should also add an AWS or Azure object storage source for use with dbt.
3. Prepare your local development environment
To work with dbt and Dremio, you'll need to set up your local development environment:
Open your preferred integrated development environment (IDE) and create an empty folder. This folder will host your dbt project.
Open a terminal in this folder.
4. Set up a Python virtual environment
It’s a best practice to use a virtual environment for Python projects. This keeps dependencies required by different projects separate and organized.
In the terminal, create a new virtual environment by running:
python -m venv venv
Activate the virtual environment. On Windows, use:
python -m venv venv
On Unix or MacOS, use:
source venv/bin/activate
5. Install dbt-dremio
With your virtual environment activated, install the dbt-dremio package.
Run the command:
pip install dbt-dremio
This will install the dbt-dremio connector, allowing dbt to interact with your Dremio data sources.
6. Initialize your dbt project
Now it’s time to create your dbt project.
In the terminal, run:
dbt init your_project_name
Replace your_project_name with the desired name of your project. This will prompt you with questions to configure your profile in ~/.dbt/profiles.yml. We’ll cover what each prompt means next.
7. Configure your dbt project
- Enter a Number: Enter the number that corresponds to Dremio which should be “1” (this tells dbt it is using the Dremio plugin).
- Enter a Number: The next number is which version of Dremio you are using, which for this tutorial should be Dremio Cloud which is number “1” (choose Dremio Software with Username/Password if working from laptop).
- Choose an API: Identify which Dremio Cloud API are you using; default uses the North American API, select the European one if using the European Dremio Cloud. (If working from your laptop use 127.0.0.1 as the host and 9047 as the port.)
- Enter Email: This is the email your individual Dremio account is under. (If working from a laptop enter username, then password, then skip to object_storage_source.)
- Enter PAT Token: Generate a PAT token from the Dremio Cloud UI and enter it here for this step.
- Enter Project ID: Enter the ID of the Dremio Cloud project this dbt project will run against.
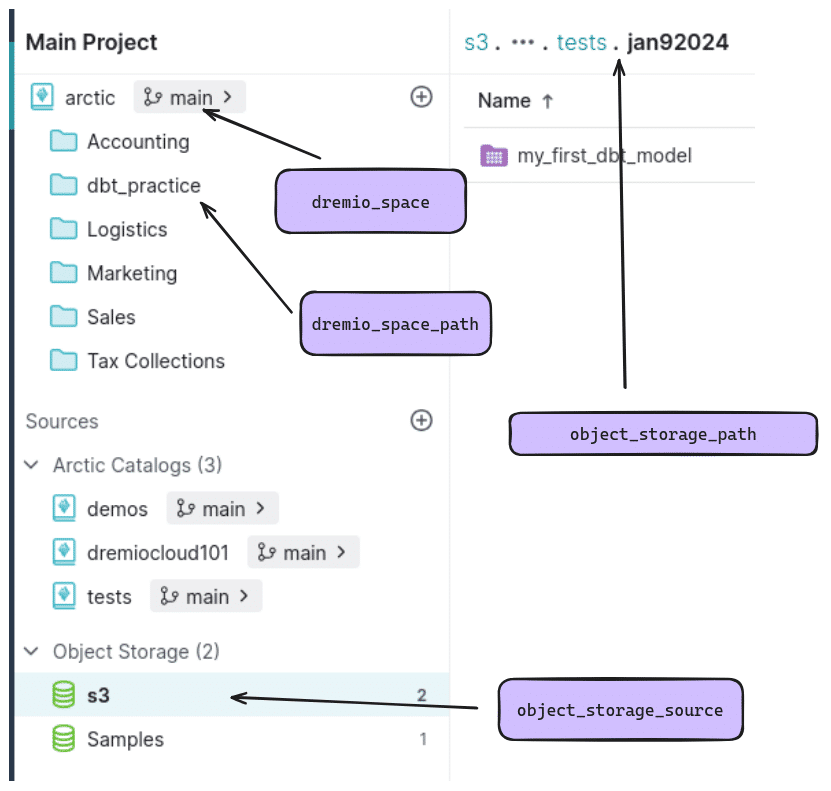
- object_storage_source: This should be the name of an Arctic catalog or object storage source in your project (e.g., S3). (On your laptop, this could be any Nessie/metastore/object storage source.)
- object_storage_path: This would be the path to a sub-location in your object storage for materializing tables (new physical tables are saved here). (Example: tests.jan92024)
- dremio_space: For Dremio Cloud, this would be the name of the Arctic catalog you want views to be added to (example: Arctic). (If working from a laptop, this would be the name of a space you created on your account.)
- dremio_space_path: A subfolder of the Arctic catalog you want views created by your dbt models to appear in (example: dbt_practice).
Once everything is set up you’ll have the following folder structure:
. ├── analyses ├── dbt_project.yml ├── macros ├── models │ └── example │ ├── my_first_dbt_model.sql │ ├── my_second_dbt_model.sql │ └── schema.yml ├── README.md ├── seeds ├── snapshots └── tests
/dbt_project.yml
The main file we should look at next is the dbt_project.yml file, which will look like:
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models
name: 'test_run'
version: '1.0.0'
config-version: 2
# This setting configures which "profile" dbt uses for this project.
profile: 'test_run'
# These configurations specify where dbt should look for different types of files.
# The `model-paths` config, for example, states that models in this project can be
# found in the "models/" directory. You probably won't need to change these!
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
clean-targets: # directories to be removed by `dbt clean`
- "target"
- "dbt_packages"
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the `{{ config(...) }}` macro.
models:
test_run:
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view- name: This is the name of your dbt project. In this case, it's 'test_run'. Project names should only contain lowercase characters and underscores.
- version: Defines the version of the dbt project, here it is set to '1.0.0'.
- config-version: This specifies the version of the dbt configuration file format. '2' is the current version.
- profile: This indicates which profile to use from the profiles.yml file. Profiles define environments and contain database connection information. Here, it's set to use the 'test_run' profile.
- paths: These settings specify where dbt should look for different types of files. The default directories for models, analyses, tests, seeds, macros, and snapshots are defined here. For example, model-paths: ["models"] means dbt will look for models in the "models/" directory.
- clean-targets: Lists the directories that the dbt clean command will clear out. This helps remove old logs and temporary files that dbt creates during its run. It's set to clear the 'target' and 'dbt_packages' directories here.
- models: This section is used to configure your dbt models.
- test_run: This is the name of your dbt project (matching the project name), and it's used here to scope the configurations to models within this project.
- example: This is a sub-directory within your models directory. This configuration applies to all models in the 'example/' directory.
- +materialized: This is a key dbt configuration. It specifies how dbt should materialize (or build) the models in the database. In this case, it's set to 'view', meaning dbt will create views in the database for these models.
Let’s examine the default models in the project:
/models/example/my_first_dbt_model.sql
/*
Welcome to your first dbt model!
Did you know that you can also configure models directly within SQL files?
This will override configurations stated in dbt_project.yml
Try changing "table" to "view" below
*/
{{ config(materialized='table') }}
with source_data as (
select 1 as id
union all
select null as id
)
select *
from source_data
/*
Uncomment the line below to remove records with null `id` values
*/
-- where id is not nullModel Configuration
{{ config(materialized='table') }}This line is a dbt-specific configuration that determines how the model will be materialized in the database. In this case, materialized='table' means that when dbt runs this model, it will create a physical table in your data warehouse. If you change 'table' to 'view', dbt will create a view instead.
SQL Query
with source_data as ( select 1 as id union all select null as id ) select * from source_data
This is the leading SQL query for the model. It uses a common table expression (CTE) named source_data.
Inside the CTE, two rows are created: one with an id of 1 and another with a null id.
After the CTE, the select * from source_data statement selects all columns from the source_data CTE.
This means the resulting table (or view, depending on the materialization setting) will have two rows, one with id 1 and the other with a null id.
Optional Where Clause
-- where id is not null
This line is commented out, but removing the comment (--) will act as a filter to remove rows where the id is null.
If you uncomment this line, the resulting table or view will only contain the row with id 1, as the row with the null id will be filtered out.
/models/example/my_second_dbt_model.sql
-- Use the `ref` function to select from other models
select *
from {{ ref('my_first_dbt_model') }}
where id = 1Model Content
select *
from {{ ref('my_first_dbt_model') }}
where id = 1The ref Function
{{ ref('my_first_dbt_model') }}This is a dbt-specific Jinja function. ref is used to create a reference to another model within your dbt project. In this case, it's referring to a model named my_first_dbt_model.
The purpose of using ref is to create a dependency between models. When you run dbt, it builds models in the correct order based on these dependencies. For example, if my_first_dbt_model needs to be built before this model can be run, dbt will automatically figure this out and build my_first_dbt_model first.
The SQL Query
The SQL query itself is straightforward. It selects all columns (select *) from the dataset produced by my_first_dbt_model.
The where id = 1 clause filters the result to only include rows where the id column equals 1.
Purpose and Use Case
This model demonstrates a fundamental aspect of dbt: building modular and dependent models that reference each other. This approach allows complex data transformation workflows to be broken down into smaller, manageable pieces. Each piece (or model) can be developed, tested, and understood independently, while dbt orchestrates the overall workflow.
For example, my_first_dbt_model might be a model that transforms raw data into a more analysis-friendly format. This current model could then be used to refine or analyze that data, filtering it down to rows of particular interest (in this case, where id is 1).
Key Takeaway
The ref function is central to dbt's philosophy of modular and maintainable data modeling. It allows data teams to build complex data transformations in a structured and efficient manner, with clear dependencies and order of operations.
Now you can run the command:
dbt run
As long as you configured all the right details in the profile, this should run smoothly, and you’ll find two new views in the location you specified for your project’s Arctic catalog.
The SQL can reference objects accessible by your Dremio project, like the sample dataset.
For example, if we wanted to create a view of the sample taxi dataset with only two of the columns available, we can create a file:
/models/example/taxi1.sql
SELECT pickup_datetime, passenger_count FROM Samples."samples.dremio.com"."NYC-taxi-trips-iceberg"
Then, if we want to make another view with only one column based on that view we can create with:
/models/example/taxi2.sql
SELECT pickup_datetime
FROM {{ ref('taxi1') }}Then we can run the dbt models again and see the new models in the locations we specified in the dbt profile when the project was configured.
If you want to land the view in a different location than the one specified in the dbt profile you’d just use the config function before the query.
- Landing the view in a different folder in the same Arctic catalog:
{{ config(schema='2024.dbt_practice.jan92024.test')}}
SELECT pickup_datetime
FROM {{ ref('taxi1') }}- Landing the view in a different Arctic catalog:
{{ config(database='demos',schema='2024.dbt_practice.jan92024.test')}}
SELECT pickup_datetime
FROM {{ ref('taxi1') }} AT BRANCH mainSince we’re depending on a view being created in a different catalog and since Arctic catalogs can have multiple branches, you need to specify the branch when landing the view in a different catalog.
Conclusion
Throughout this blog, we've explored the dynamic synergy between Dremio, a premier data lakehouse platform, and dbt (data build tool), a potent tool for data transformation. This combination is a formidable solution for businesses striving to efficiently access, analyze, and manage vast data.
Together, Dremio and dbt bring several advantages to the table:
- Enhanced data transformation: dbt's sophisticated transformations turn raw data into valuable insights, integral to Dremio's robust semantic layer.
- Version control and collaboration: Essential for maintaining data model integrity, these features ensure consistency in a team environment.
- Streamlined workflow: The integration of dbt with Dremio assures a seamless and efficient data processing pipeline.
- Scalability and flexibility: dbt's architecture is designed for growth, adapting to changing data volumes and business needs.
- Community and ecosystem: As an open source tool, dbt boasts a strong community offering extensive resources and integrations.
The journey outlined in this blog is more than just a technical setup; it's a path to mastering data in previously challenging or impossible ways. By harnessing Dremio's data lakehouse capabilities and dbt's transformational prowess, organizations can make more informed decisions, manage their data more efficiently, and gain a competitive edge in the data-driven marketplace.
As we conclude, remember that the world of data is ever-evolving. The combination of Dremio and dbt isn’t just a solution; it's a continuously advancing pathway to data excellence, unlocking potential and opportunities for businesses ready to embrace the future of data management.
Additional dbt with Dremio resources:
Video Demonstration of dbt with Dremio Cloud
Video Demonstration of dbt with Dremio Software
Dremio dbt Documentation
Dremio CI/CD with Dremio/dbt whitepaper
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Dremio Blog: Product Insights,
Learn More ->

BLOG
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.
Dremio Blog: Product Insights,
Learn More ->

BLOG
Kubernetes Autoscaling in Dremio 24.3
Dremio Blog: Product Insights,
Learn More ->