12 minute read · September 22, 2023
How to Create a Lakehouse with Airbyte, S3, Apache Iceberg, and Dremio
· Senior Tech Evangelist, Dremio

In the ever-evolving data landscape, the need for robust and scalable data storage solutions is growing exponentially. The essence of data-driven decisions lies in the capability to harness vast amounts of structured and unstructured data from various sources, process them, and prepare them for analysis. In this realm, the concept of the “lakehouse” has emerged as a transformative idea, providing businesses with a means to have the best of both data lakes and data warehouses. But what is a lakehouse, and why should it matter to you? How do tools like Airbyte, Amazon S3, Apache Iceberg, and Dremio fit into this architecture? Let's dive in!
What Is a Lakehouse?
A lakehouse combines the best of both data lakes and data warehouses. It offers the vast storage capability and flexibility of data lakes for diverse data types and the structured, performance-oriented capabilities of data warehouses. This hybrid model allows businesses to ingest, store, and analyze vast amounts of data with agility, making it crucial in today's data-intensive era.
Understanding the Tools
Airbyte: An open source data integration platform that connects sources and destinations, making data ingestion easier and more scalable.
Apache Iceberg: A table format for massive analytic datasets, providing a better experience for data lake users by bringing ACID transactions, finer partitioning, and improved metadata handling.
S3: Amazon S3 (Simple Storage Service) is a scalable cloud storage service from Amazon Web Services (AWS) that allows users to store and retrieve any amount of data anytime, from anywhere on the web.
Dremio: Dremio is a data lakehouse platform that enables fast queries and easy self-service access built on top of open architecture and technologies.
In this article, we will embark on a journey to set up a local environment to seamlessly integrate these tools. Our journey will involve ingesting data into Apache Iceberg with Airbyte, and learning how to query this data using Dremio effortlessly. Whether you're a seasoned data engineer or someone new to the world of data lakes and lakehouses, by the end of this tutorial, you'll have a clearer understanding and hands-on experience of creating a dynamic lakehouse setup.
Read on to unveil the step-by-step guide to this exciting integration!
How to Set Up Our Local Environment
A couple of housekeeping items before we start to set up our environment:
- Must have the latest version of Docker Desktop installed.
- Make sure in your Docker Desktop preferences that the /tmp directory is shared (for Linux).
- Check off the setting that enables the docker-compose CLI command; the docker-compose --version command should return a version 2+.
- Create an S3 bucket or folder in an existing bucket to store our ingested data. Keep the bucket address and your AWS access and secret key handy.
Once you have those items, deploy Airbyte on your machine. Remember that you must deploy Airbyte OSS because currently the Apache Iceberg connector only exists in the OSS software and not in the Airbyte cloud service. Open up your IDE or a terminal to an empty directory.
# clone Airbyte from GitHub git clone https://github.com/airbytehq/airbyte.git # switch into Airbyte directory cd airbyte # start Airbyte ./run-ab-platform.sh
It will take some time for Airbyte to set up fully, but once it is done you can go to localhost:8000 and log in with the username/password of Airbyte/password, and then enter your email to get to the Airbyte dashboard.
Next, open up a second terminal and run the following command to have Dremio run on localhost:9047:
docker run -p 9047:9047 -p 31010:31010 -p 45678:45678 dremio/dremio-oss
Ingesting Our Data
First, we need some sample data; so let’s generate some! Head over to Mockaroo.com and generate a CSV with the fields of your choice; I’ll just use the default field names for 1,000 data records. You’ll want this data somewhere online so it can be accessed via a URL. To do this, I created a free account at Cloudinary.com and uploaded the file. Once your CSV file is uploaded, you can head to the Airbyte dashboard.
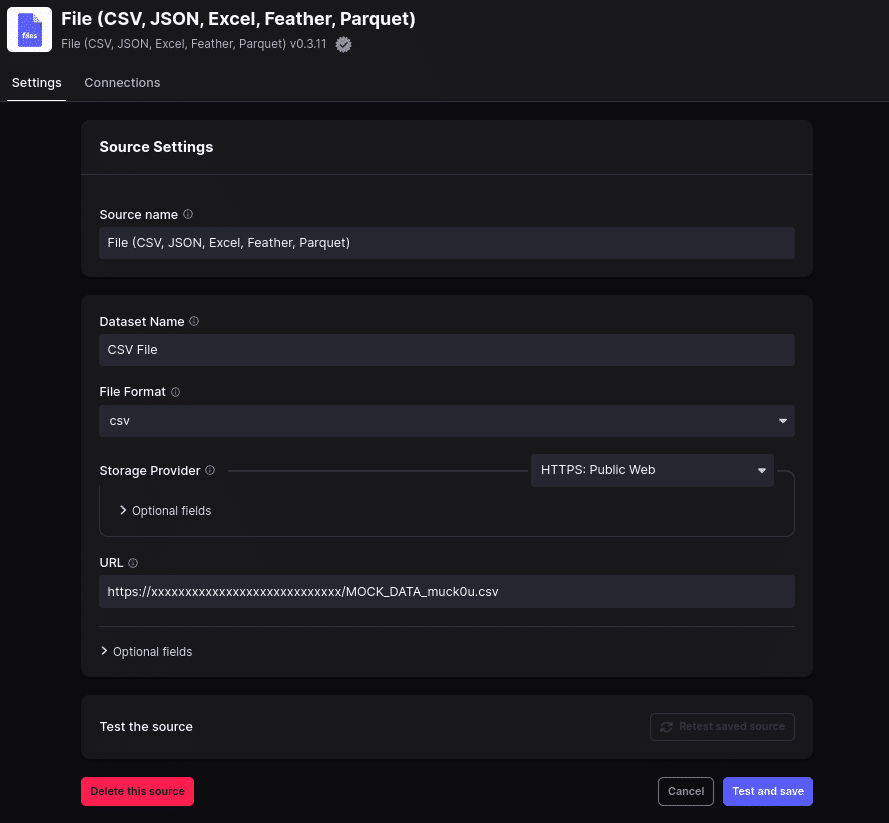
Click on “Create Connection” to create our first pipeline. There are many possible sources you can pull data from and feel free to try different ones after this exercise. For now, choose the file data source where we will set the following settings:
- Set to CSV file type
- HTTPS as the data provider
- Put the URL for your data in the proper field
Create the source and give it a moment to test before moving on to the next step.
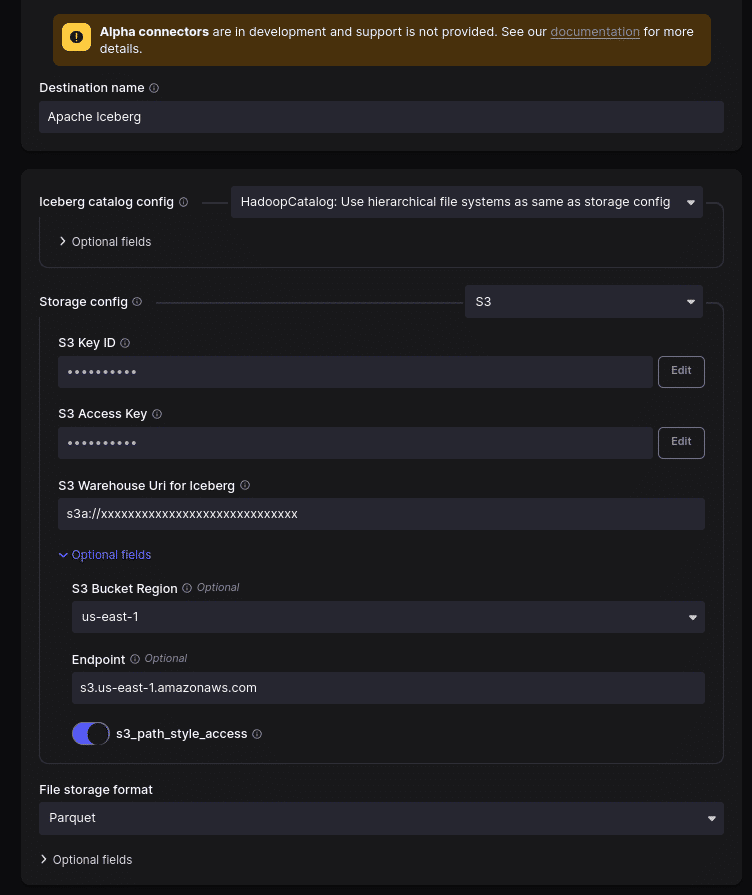
We need to set the destination where the source data will land. We want to land the data in the Apache Iceberg format to use the new Apache Iceberg connector currently in Alpha. So, you need to check the Alpha checkbox to see the Alpha-level connectors.
After selecting the Apache Iceberg destination, let’s use the following settings:
- Choose the HadoopCatalog option for the catalog configuration; this lets us write Apache Iceberg tables directly to our storage.
- The S3 Key should be the access key you got from S3.
- The S3 Access Key field should be the secret key you got from S3.
- The warehouse should be s3a://your/bucket (adjust to match your desired s3 location but must have the s3a prefix).
- Click optional fields and set the region to your desired AWS region and the S3 endpoint to the endpoint for that region, which you can find here.
On the final connection string, change the frequency to manual and keep everything else on the default setting.
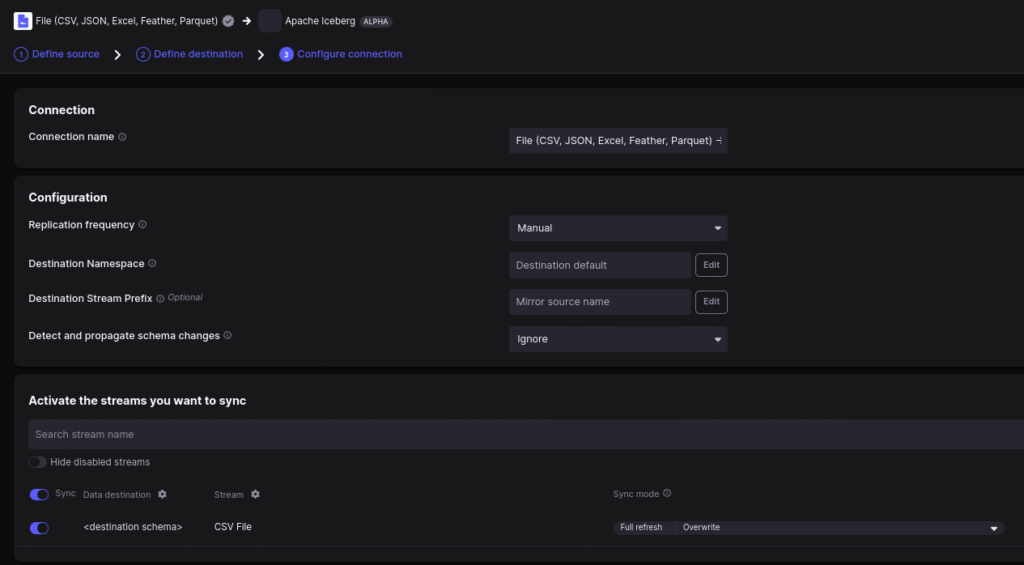
Then click setup connection, and the pipeline should be open and you can run it by clicking “sync now.” Note: you can run it again anytime you click the “sync now” button or on a schedule you set.
Then check your S3 bucket and you’ll see that the table is in a location called default/airbyte_raw_csv_file with the data and metadata folder inside. We successfully ingested the data! Now let’s query it with Dremio.
Querying Data with Dremio
Head over to localhost:9047, set up your Dremio account, and navigate to the Dremio dashboard. Click “add source” in the bottom left, select S3, add in your S3 credentials, and then click “save” to add the source.

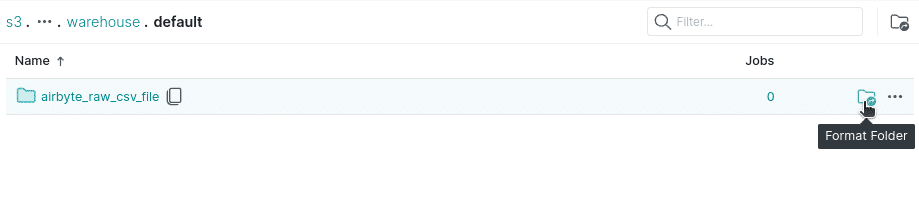
You can now see the source on the Dremio dashboard. Navigate to find the airbyte_raw_csv_file directory.
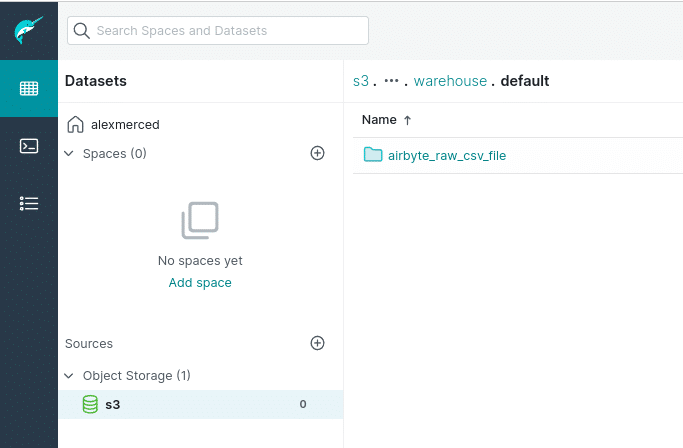
Then click on the “format folder” icon toward the right, select “Iceberg,” and click save so Dremio recognizes this directory as an Apache Iceberg table.
Once it is done saving, it will take us to the query editor, where we can run a query on this data.
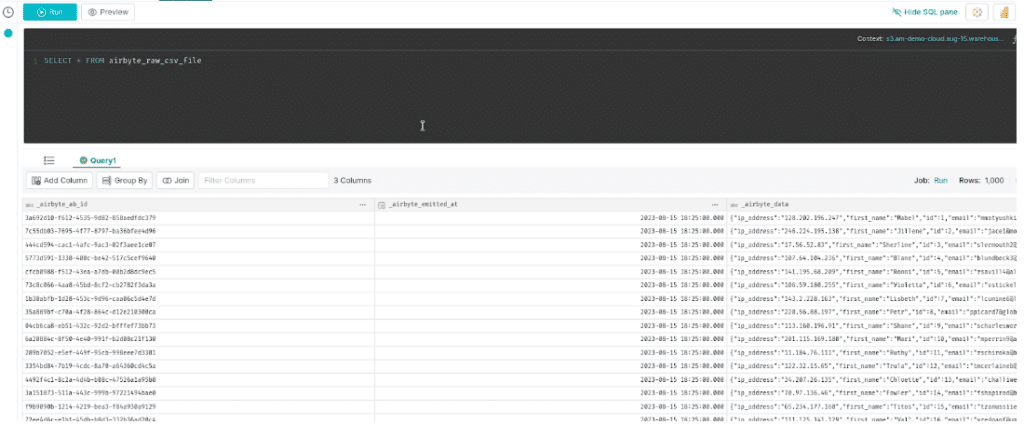
Per the Iceberg connectors documentation, the data from our CSV file is saved in a JSON column called _airbyte_data. We want to extract that JSON as separate columns, luckily Dremio makes last mile ETL work like this, which is something we can self-serve.
- Use the CONVERT_FROM function to convert the JSON into a Struct, and then just give each property its own column from there.
SELECT CONVERT_FROM(_airbyte_data,'json') as data, data['ip_address'] as ip_address, data['first_name'] as first_name, data['last_name'] as last_name, data['id'] as id, data['email'] as email, data['gender'] as gender FROM airbyte_raw_csv_file;
Run the query and now each piece of data has its own field. We can save this view by right-clicking “Save View As” in the upper-right corner.
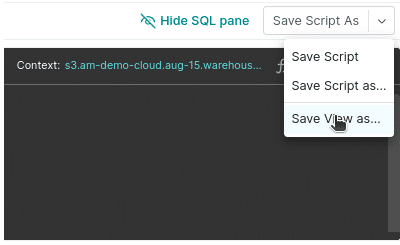
Save the view under the name of your choosing, and you’ll now be able to access the view directly from the Dremio dashboard like it were its own table.
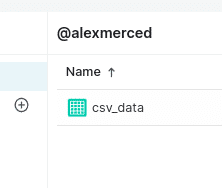
With enterprise versions of Dremio Software or Dremio Cloud, we can share access directly to this view without sharing access to the raw data, apply column and row masking, and much more.
Summary
Using Airbyte, you can easily ingest data from countless possible data sources into your S3-based data lake, and then directly into Apache Iceberg format. The Apache Iceberg tables are easily readable directly from your data lake using the Dremio data lakehouse platform, which allows for self-service data curation and delivery of that data for ad hoc analytics, BI dashboards, analytics applications, and more.
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->