13 minute read · May 31, 2023
Using Generative AI as a Data Engineer
· Senior Tech Evangelist, Dremio
Data engineering is an essential part of data science and analytics, as it involves transforming raw data into a usable form. With the rapid advancement of generative AI, it is becoming increasingly important for data engineers to know its capabilities and potential implications. Generative AI is a type of artificial intelligence (AI) used to create data and generate models from available data. It has the potential to revolutionize how we work with data, allowing us to automate specific tasks and make more effective use of data.
Generative AI is artificial intelligence that can create new data, such as text, images, audio, and video, by learning patterns from existing data, then using this knowledge to generate new and unique outputs. Generative AI can produce highly realistic and complex content that mimics human creativity, making it a valuable tool for many industries such as gaming, entertainment, and product design.
One of the most promising applications of generative AI is in the field of natural language processing (NLP). NLP is a branch of computer science that deals with the interaction between computers and human language. Generative AI can improve the accuracy and efficiency of NLP tasks such as machine translation, text summarization, and question answering.
For example, generative AI can generate SQL queries based on existing datasets. This can be helpful for data scientists who need to quickly and easily access the data they need for their research. Generative AI can also be used to write detailed documents about a dataset. This can be helpful for researchers who want to share their findings with others in a clear and concise way.
Examples of Generative AI for Data Engineering
Using AI to Understand How to Write SQL
I asked GPT about how to write a “MERGE INTO” statement and here is what I got back:

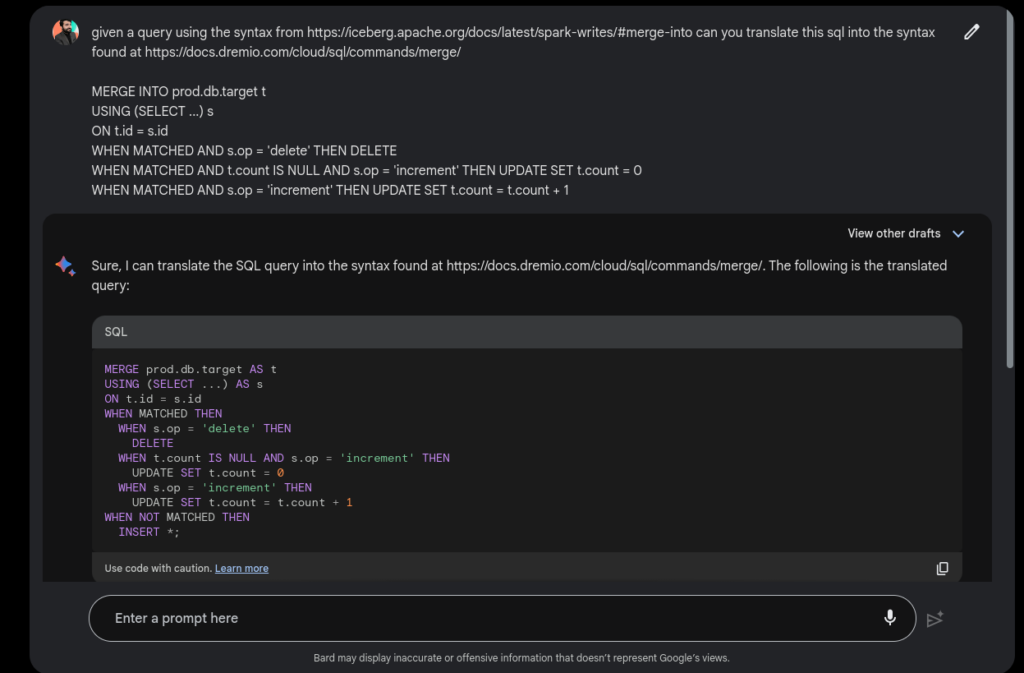
Using AI to Translate Between SQL Dialects
Using Google Bard I took a MERGE INTO query using the SparkSQL syntax from Apache Iceberg’s documentation and translated it into Dremio’s SQL syntax with references to relative documentation. While I don’t need to include the links to the documentation, doing so can help improve the accuracy of the results since Bard has web access.
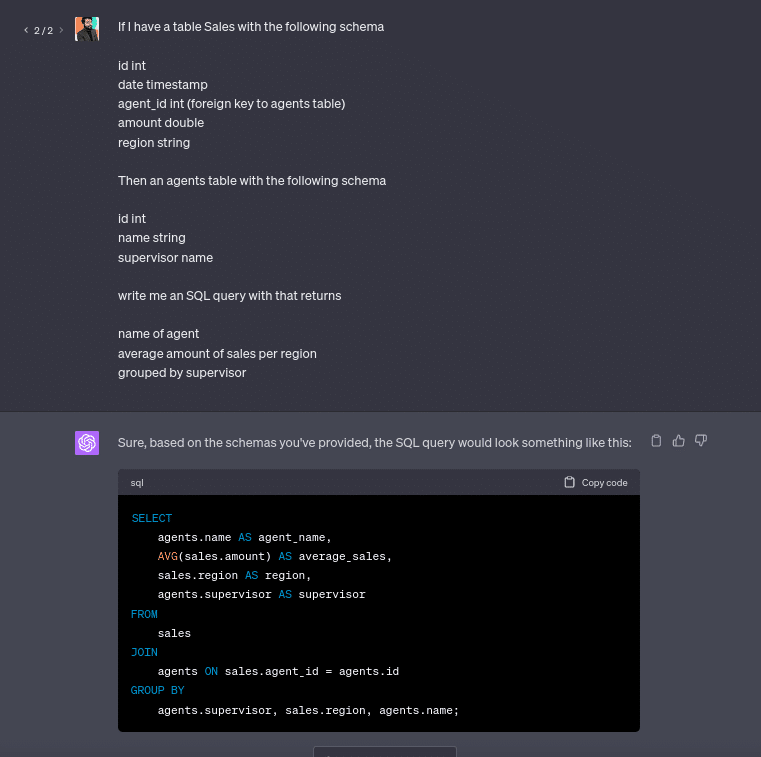
Using AI to Generate SQL Statements Based on Natural Language
Using AI to Generate Documentation on a Dataset
Here I describe a dataset to ChatGPT and ask it for documentation on that dataset.
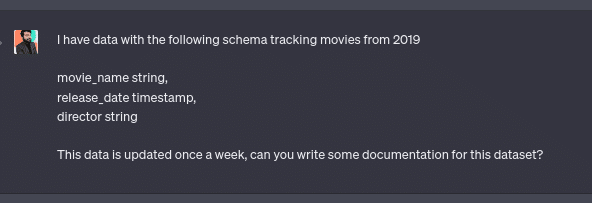
This resulted in the following output:

As you can see, by providing it with just enough context, it created documentation that filled in many intended details that I didn’t explicitly say, such as what the different fields represented.
Using AI to Help Write a Data Pipeline Boilerplate
In this example, I use ChatGPT to help create some boilerplate code that can be used to accelerate the development process. I describe the operators I want for an astronomer DAG and let ChatGPT write some boilerplate for the DAG.
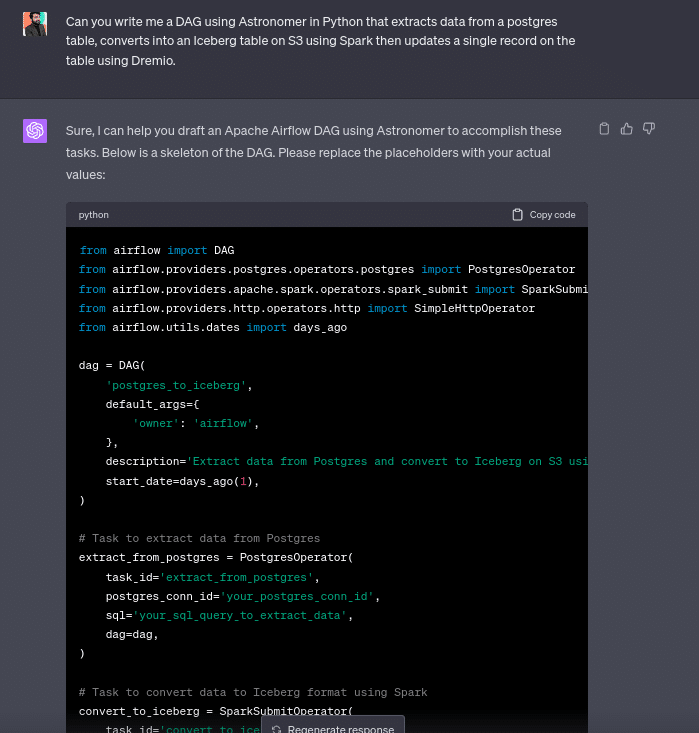
Here is the boilerplate code it gave me:
from airflow import DAG
from airflow.providers.postgres.operators.postgres import PostgresOperator
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator
from airflow.providers.http.operators.http import SimpleHttpOperator
from airflow.utils.dates import days_ago
dag = DAG(
'postgres_to_iceberg',
default_args={
'owner': 'airflow',
},
description='Extract data from Postgres and convert to Iceberg on S3 using Spark then update Dremio',
start_date=days_ago(1),
)
# Task to extract data from Postgres
extract_from_postgres = PostgresOperator(
task_id='extract_from_postgres',
postgres_conn_id='your_postgres_conn_id',
sql='your_sql_query_to_extract_data',
dag=dag,
)
# Task to convert data to Iceberg format using Spark
convert_to_iceberg = SparkSubmitOperator(
task_id='convert_to_iceberg',
conn_id='your_spark_conn_id',
application='path_to_your_spark_script',
# Pass the output of the Postgres task to your Spark job
application_args=['{{ ti.xcom_pull(task_ids="extract_from_postgres") }}'],
dag=dag,
)
# Task to update Dremio
update_dremio = SimpleHttpOperator(
task_id='update_dremio',
http_conn_id='your_dremio_conn_id',
endpoint='your_dremio_endpoint',
method='POST',
# You would need to have a mechanism to extract the relevant data to update Dremio
data='{{ ti.xcom_pull(task_ids="convert_to_iceberg") }}',
headers={'Content-Type': 'application/json'},
dag=dag,
)
# Define task dependencies
extract_from_postgres >> convert_to_iceberg >> update_dremioUsing AI to Generate a Schema from JSON
In this final example, I took a JSON object and asked ChatGPT to write a CREATE TABLE statement with a schema based on the object.

Here is the full JSON object:
{
"id": 1,
"num": "001",
"name": "Bulbasaur",
"img": "http://www.serebii.net/pokemongo/pokemon/001.png",
"type": [
"Grass",
"Poison"
],
"height": "0.71 m",
"weight": "6.9 kg",
"candy": "Bulbasaur Candy",
"candy_count": 25,
"egg": "2 km",
"spawn_chance": 0.69,
"avg_spawns": 69,
"spawn_time": "20:00",
"multipliers": [
1.58
],
"weaknesses": [
"Fire",
"Ice",
"Flying",
"Psychic"
],
"next_evolution": [
{
"num": "002",
"name": "Ivysaur"
},
{
"num": "003",
"name": "Venusaur"
}
]
}Here was ChatGPT’s response:
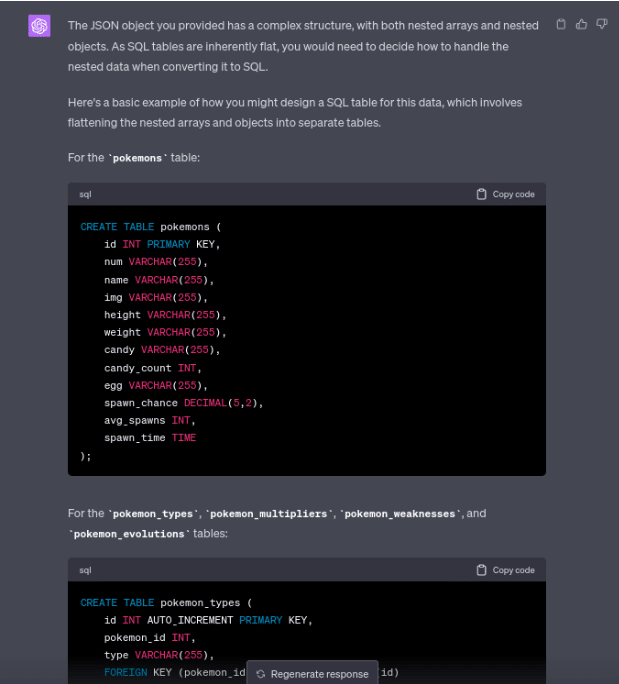
Here are all the schemas it generated based on the JSON object:
CREATE TABLE pokemon_types (
id INT AUTO_INCREMENT PRIMARY KEY,
pokemon_id INT,
type VARCHAR(255),
FOREIGN KEY (pokemon_id) REFERENCES pokemons(id)
);
CREATE TABLE pokemon_multipliers (
id INT AUTO_INCREMENT PRIMARY KEY,
pokemon_id INT,
multiplier DECIMAL(3,2),
FOREIGN KEY (pokemon_id) REFERENCES pokemons(id)
);
CREATE TABLE pokemon_weaknesses (
id INT AUTO_INCREMENT PRIMARY KEY,
pokemon_id INT,
weakness VARCHAR(255),
FOREIGN KEY (pokemon_id) REFERENCES pokemons(id)
);
CREATE TABLE pokemon_evolutions (
id INT AUTO_INCREMENT PRIMARY KEY,
pokemon_id INT,
evolution_num VARCHAR(255),
evolution_name VARCHAR(255),
FOREIGN KEY (pokemon_id) REFERENCES pokemons(id)
);As you can see, using generative AI can make many tasks quicker:
- Generating SQL from natural language
- Translating between SQL dialects
- Generating boilerplate data pipeline DAGs
- Generating relational schemas for unstructured and semi-structured data
Risks to Consider
Data engineers should be aware of certain risks associated with generative AI. One risk is the correctness of code created by the generative model, which may not be often usable as is, or the inability to create code using the latest features and syntax due to the cutoff of training data.
Risks of generative AI to data engineers:
- Correctness: The SQL, Python, or other code generated by generative AI may not run as is or be entirely correct due to lack of context or limitations of the model. All code generated should be treated as a starting place for further development, as you’ll want to test and iterate on what is generated.
- Staleness: If you use the newest tools and features, generative AI may not be trained on that data and be less helpful. This can be overcome by providing more context, such as snippets of documentation, but this is limited by the number of tokens an AI prompt can accept.
These are just some of the risks associated with generative AI. Data engineers should be aware of these risks and take steps to mitigate them.
Best Practices for Data Engineers
Using generative AI models to generate SQL and Python code has opened up new opportunities for data engineers. With the ability to generate code snippets and automate parts of the development process, these models can increase productivity and efficiency. However, to effectively incorporate generative AI into their workflow, data engineers need to follow certain best practices.
Understand the limitations: Generative AI models, like any other tool, have limitations. They work by learning patterns from training data and then generating similar patterns. Therefore, the quality and usefulness of the generated code depend heavily on the training data. If the model was not trained on a particular coding pattern or style, it might not be able to generate it. Also, it may produce incorrect or nonsensical code if the input is unclear or not detailed enough.
Verify and test the generated code: It's crucial to thoroughly verify and test all code generated by AI. While generative AI models can be powerful tools, they're not infallible. They can make mistakes and overlook nuances that a human developer would catch. Therefore, data engineers should always review the generated code for correctness, efficiency, and adherence to coding standards. Automated testing and code review tools can be beneficial in this regard.
Use as a tool, not a replacement: Generative AI should be viewed as a tool to assist data engineers, not a substitute for them. The models can generate code snippets quickly and help with tedious aspects of coding, but they lack the ability to understand a project's larger context or goals. Data engineers must still provide direction, make high-level design decisions, and integrate the generated code into the larger codebase.
Protect sensitive information: When using generative AI, be careful not to expose sensitive information. The models learn from the data they are trained on, and they can inadvertently generate code that contains sensitive information from the training data. Therefore, always ensure that training data is adequately anonymized and that generated code is reviewed for potential leaks.
Iterative refinement: When using generative AI for code generation, start with small, well-defined tasks. Use the feedback from these tasks to improve the model's understanding and performance. Gradually increase the complexity of jobs as the model's performance improves.
Stay up to date with advancements: Generative AI is rapidly evolving, with new models and techniques being developed regularly. Stay up to date with the latest advancements to understand how they can be incorporated into your workflow. Participate in relevant communities, attend conferences, and read current papers and articles.
Conclusion
Generative AI can be a powerful tool for data engineers, but it must be used responsibly and effectively. By understanding its limitations, verifying its output, using it as an aid rather than a replacement, protecting sensitive information, refining its use iteratively, and staying up to date with advancements, data engineers can leverage generative AI to enhance their productivity and creativity.
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->