Apache Iceberg is a data lakehouse table format that provides a robust feature set and open ecosystem for analytics use cases, including ACID transactions, time travel, schema evolution, and more. And, with the release of version 1.0, there is no better time than now to start building with Iceberg. And you aren’t alone; companies like Netflix, LinkedIn, Stripe, and Apple alongside analytics and cloud technology companies like Dremio, Snowflake, and AWS contribute to Apache Iceberg’s rapid pace of innovation. The community of Apache Iceberg users and contributors is growing due to the Apache Foundation’s standards for open community-run projects as well as the capabilities Iceberg enables.
If you are implementing a data lakehouse, continue reading to learn more about the features, community, and history of Apache Iceberg, and why now is time to adopt it as your table format.
Why Is Choosing the Right Table Format Important?
A table format is the core pillar to turning a data lake into a data lakehouse, allowing it to behave like a data warehouse at a fraction of the cost. The table format takes groups of files in your data lake storage and treats them as a full-fledged database table.
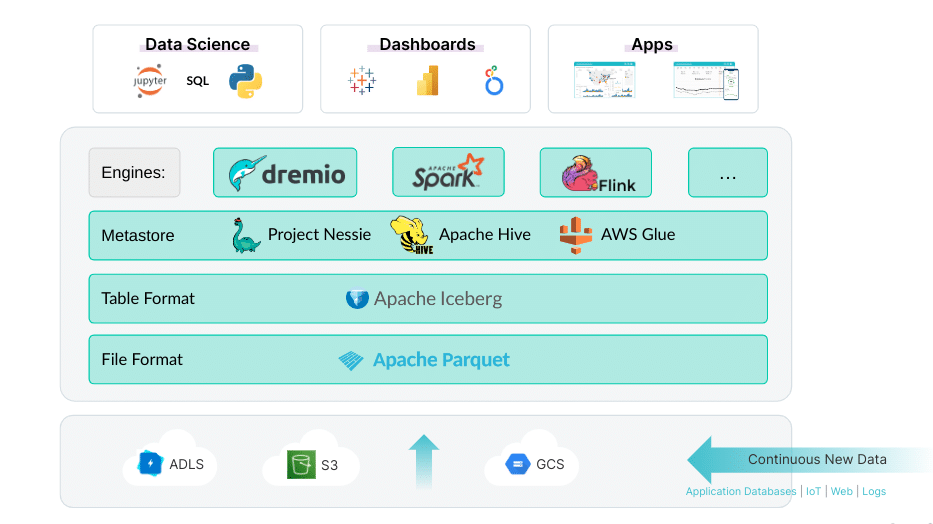
Table formats have differences across feature sets, such as partition evolution, and nuances in performance characteristics for various workloads. Furthermore, the table format you choose affects your overall data lakehouse architecture. It can determine which tools and data lakehouse engines you can use on your data and it could lock you into a vendor ecosystem.
If you choose the wrong table format, there may be a huge price to pay by either suffering through vendor lock-in or dealing with migration costs to move all your data to another format.
Which table format you adopt is arguably the most consequential decision you’ll make because it acts as the foundation to your data lakehouse.This is why selecting a table format should not solely be about features and performance, it should include the openness and diversity of its development as well as the scope of its ecosystem.
Apache Iceberg has a long history of open development and diverse project governance, and is not controlled by any single organization. This provides assurances that the project’s direction will continue its path toward community needs, and not the way a single organization dictates.
Apache Iceberg’s open development and diverse project governance has led to a large community of participants involved in the development of the project.
There is great value that comes from open development and a diverse community of participants including a robust user base and integration ecosystem. Apache Iceberg’s user base is strong with a growing number of organizations using the project in production. Iceberg’s ecosystem is robust with organizations and industry vendors continually creating and contributing integrations for the project.
Open development like Iceberg’s is pivotal to preventing the lock-in that can occur if a project becomes overly controlled by one vendor.
The Promise of Apache Iceberg
Originally, the Hive table format (released as part of the Hive project in 2010) was the only table format available, and was a great innovation at the start, but had imperfections related to updating the data in the table, concurrency, maintaining table stats, evolving the table, performance, and more. To deal with these issues, Netflix sought to create a better table format that would address these issues, and enable ACID transactions, concurrency and more data warehousing-like features on the lake. Thus, the Iceberg table format was born.
Apache Iceberg offers several valuable features when working with your data lakehouse data such as:
- ACID transactions
- Schema evolution
- Partition evolution
- Compatibility Mode (Object Storage Scaling)
- Hidden partitioning
- Concurrent writers and readers
- Time travel
- Fast query planning and execution
After being created and used by Netflix internally, they donated Iceberg to the Apache Foundation so it could be a community-driven project and enable an even playing field for vendors and companies who want to help build Iceberg and leverage it for their real-world needs. A level playing field is important because if one vendor dominates the project's direction over time, other vendors may reduce their support, leading to inevitable vendor lock-in and the higher costs that come with it.
Apache Iceberg is now actively developed and used by leading data companies across all industries including Netflix, Apple, Dremio, Stripe, LinkedIn, Tencent, and many more. Many other companies benefit from the project and are involved in the development, governance, and direction of a transparently open Apache project which ensures the Iceberg ecosystem will always be a fair playing field for the vendors who decide to support it.
Many popular data tools that currently support Iceberg include:
- Dremio
- Apache Spark
- Apache Flink
- Project Nessie
- Apache Gobblin
- Apache Drill
- Apache Hive
- Apache Dorris
- Apache Impala
- Snowflake
- Cloudera Data Engineering
- Cloudera Data Warehousing
- Trino
- Presto
- Dataproc
- AWS Glue
- Amazon Athena
- StarRocks
- Debezium
The reason for so much momentum around the development, use, and integration of Apache Iceberg is largely due to its rich community and governance model which has also led to the rich set of features the project provides to the data community.
Many of these features exist because of the architecture of Apache Iceberg.
What Makes Iceberg Extra Special
There are many things that make Apache Iceberg unique among table formats — here are just a few:
- As an Apache Project it is held to the highest standards of openness, including complete visibility of the code, those who govern the project, and the conversations among those who govern the project.
- Other table formats embraced the file layout of the Hive table format for organizing files and partitions — using a basic directory structure, which causes throttling on object storage when too many files are in the same directory/prefix. Apache Iceberg is the only format that breaks from the traditional Hive file layout, allowing it to use more optimal file layouts for object storage to avoid this bottleneck.
- Apache Iceberg has the most extensive write integration of all the table formats with a host of tools that allow you to write to Iceberg tables such as Apache Spark, Apache Flink, Dremio Sonar, Trino, Snowflake, AWS EMR, AWS Glue, AWS Athena, and Fivetran.
- Apache Iceberg is the only format with partition evolution that lets you change the way your table is partitioned as business and data situations evolve without the need to rewrite the entire table.
- The ability to execute multi-table transactions and enable robust DataOps using tools like Project Nessie and Dremo Arctic.
No Better Day Than Today
With the recent feature releases of Iceberg, there’s no better day than today to adopt Apache Iceberg:
- Z-order: You can now use z-order sorting during compaction jobs. This helps improve performance when the data is queried by multiple dimensions independently.
- Merge-on-read support: Merge-on-read support in Spark for deletes was added in version 0.13.0 and merge-on-read support for updates and merges was added with version 0.14.0.
- You can trust in 1.0: Apache Iceberg has been stable and production ready for quite some time, running in production for years at places like Netflix and Apple. But some users viewed the version number as a signal of project maturity, and even though core APIs were long stable, the version number didn’t provide formal guarantees. With the latest 1.0 release, long-running production-grade stability and API stability is formalized.
Conclusion
It’s clear Apache Iceberg has the momentum of contributors, adopters, and integrations, along with high standards of openness and a robust feature set, to win the contest as the standard data lakehouse table format.
There’s never been a better time to adopt Apache Iceberg as the foundation of your data lakehouse.
Additional Iceberg Resources
Here are some additional resources to help you learn more about Apache Iceberg:

