12 minute read · November 9, 2022
Compaction in Apache Iceberg: Fine-Tuning Your Iceberg Table’s Data Files

· Senior Tech Evangelist, Dremio


The Apache Iceberg format has taken the data lakehouse world by storm, becoming the keystone pillar of many firms’ data infrastructure. There are some maintenance best practices to help you get the best performance from your Iceberg tables. This article takes a deep look at compaction and the rewriteDataFiles procedure.
If you are new to Apache Iceberg make sure to check out our Apache Iceberg 101 article that provides a guided tour of Iceberg’s architecture and features.
The Small Files Problem
When ingesting data frequently, especially when streaming, there may not be enough new data to create optimal data file sizes for reading such as 128MB, 256MB, or 512MB. This results in a growing number of smaller files which can impact performance as the number of file operations grows (opening the file, reading the file, closing the file).
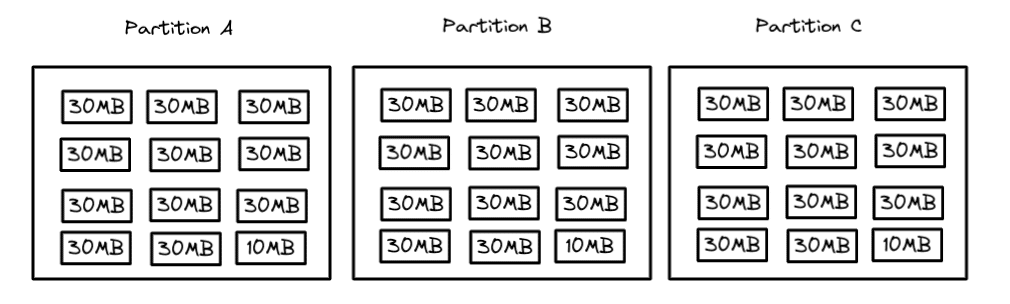
With compaction, you can rewrite the data files in each partition into fewer larger files based on a target file size. So if you target a 128MB file, then the partitions would look like this after compaction:
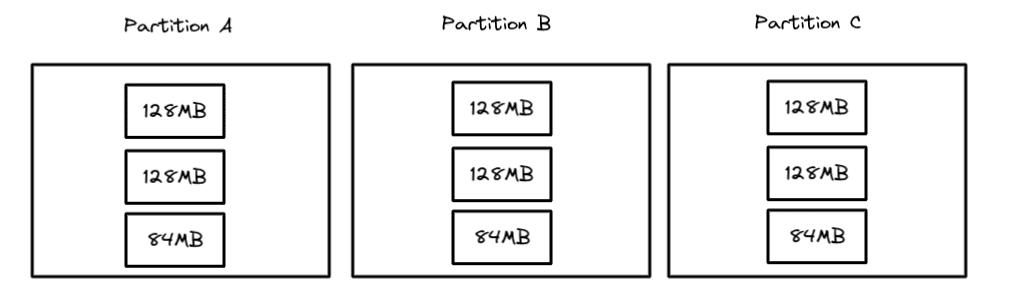
Now, when you scan a particular partition, there will be only one file to scan instead of five which reduces the number of file operations by 80% and speeds up query performance.
The rewriteDataFiles Procedure
In Iceberg libraries there is a procedure called rewriteDataFiles that is used to perform compaction operations. The procedure can be used in Spark using SparkSQL like this:
-- This will run compaction
-- Target file size set by write.target-file-size-bytes
-- table property which defaults to 512MB
CALL catalog.system.rewrite_data_files(
table => 'db.table1',
strategy => 'binpack',
options => map('min-input-files','2')
)This can also be run in Spark using Java:
Table table = ...
SparkActions
.get()
.rewriteDataFiles(table)
.option("min-input-files", "2")
.execute();In both of these snippets, a few arguments are specified to tailor the behavior of the compaction job:
- The table: Which table to run the operation on
- The strategy: Whether to use the “binpack” or “sort” strategy (each are elaborated upon in the sections below)
- Options: Settings to tailor how the job is run, for example, the minimum number of files to compact, and the minimum/maximum file size of the files to be compacted
Other arguments beyond the example above include:
- Where: Criteria to filter files to compact based on the data in them (in case you only want to target a particular partition for compaction)
- Sort order: How to sort the data when using the “sort” strategy
Note: Regardless of your strategy, if the table has a "sort order," it will be used for a local sort. After all the records have been distributed between different tasks, the data will use that sort order within each task. Using the "Sort" strategy will do a global sort before allocating the data into different tasks, resulting in a tighter clustering of data with similar values.
Another thing to keep in mind if you are taking advantage of merge-on-read in Iceberg to optimize row-level update and delete operations is that compaction will also reconcile any delete files, which improves read times since they don’t have to merge the delete files during reads.
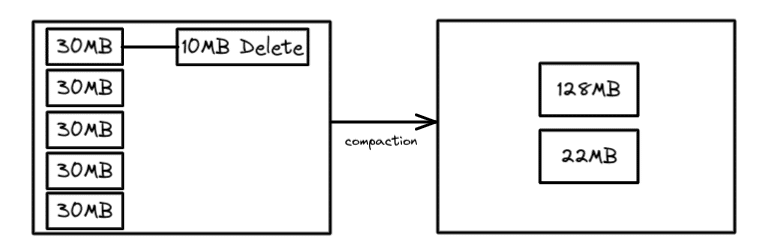
The Binpack Rewrite Strategy
The default rewrite strategy is binpack which simply rewrites smaller files to a target size and reconciles any delete files with no additional optimizations like sorting. This strategy is the fastest, so if the time it takes to complete the compaction is a consideration, then this may be your best option. The target file size is set as a table setting which defaults to 512MB, but it can be changed like so:
--Setting Target File Size to 128mb
ALTER TABLE catalog.db.table1 SET TBLPROPERTIES (
'write.target-file-size-bytes' = '134217728'
);(Note: The default of 512MB is ideal since the target row group size by default is 128MB so it will still achieve the desired level of parallelism desired with Parquet files.)
While running a binpack may be the fastest strategy if you are running compaction during streaming or frequent batches, you may not want to run compaction on the entire table. Only the data ingested during the last period will be compacted to avoid small files.
For example, the following snippet only compacts files that include data created in the last hour, assuming our schema included an “ingested_at” field that is filled when the data is being ingested:
CALL catalog_name.system.rewrite_data_files( table => 'db.sample', where => 'ingested_at between "2022-06-30 10:00:00" and "2022-06-30 11:00:00" ' )
This results in a much faster compaction job that won’t compact all files or reconcile every delete file but still provides some enhancement until a larger job can be run on a less regular basis.
The Sort Strategy
The sort strategy allows you not only to optimize the file size but also sort the data to cluster the data for better performance. The benefit of clustering similar data together is that fewer files may have relevant data to a query, meaning the benefits of min/max filtering will be even greater (fewer files to scan, the faster).
For example, without sorting:
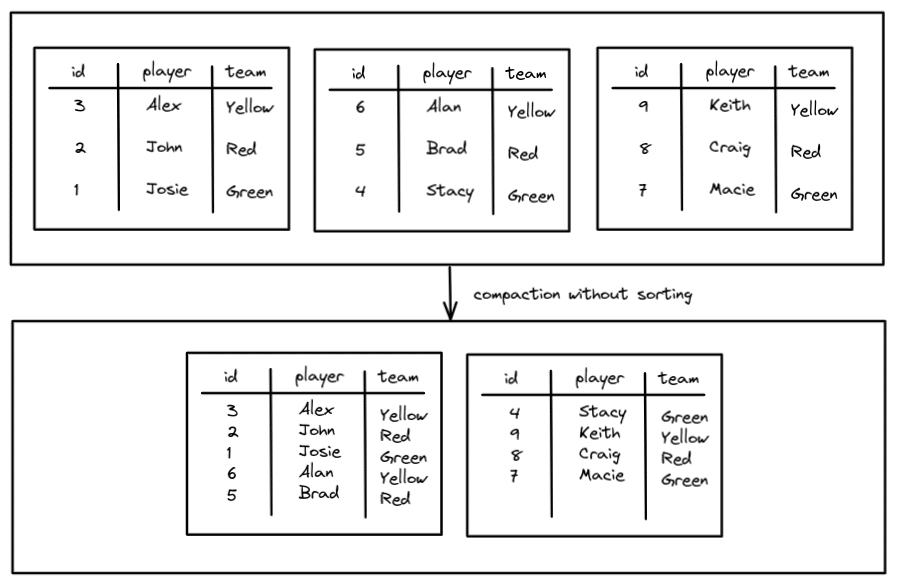
We reduced the number of files from three to two, but without sorting, regardless of which team you may query for, you have to search both files. This can be improved with sorting so you can cluster the data by team.
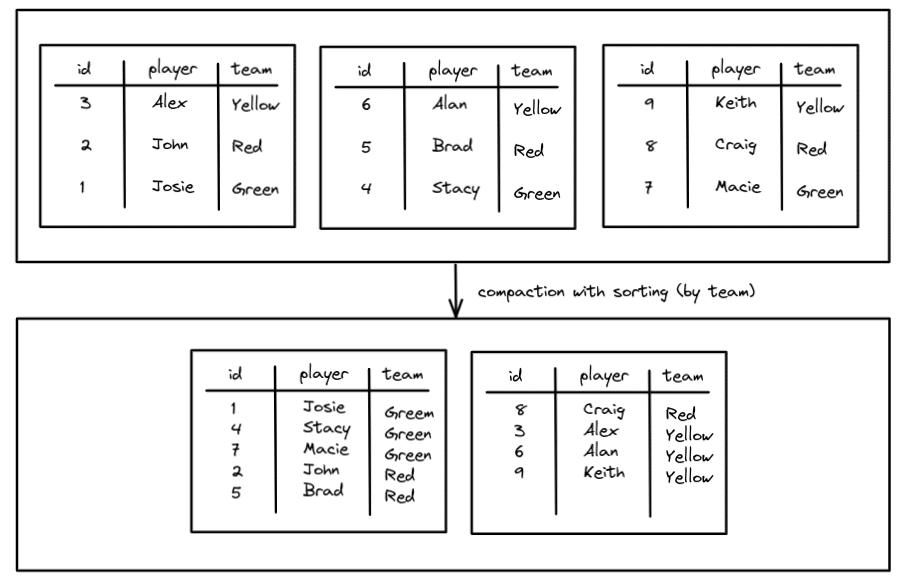
Now all the Green and Yellow team data is limited to one file which will speed up queries for members of those teams. The Red team is split across two files but we are still better off than before. To run compaction using the sort strategy looks pretty much the same as binpack except you add a “sort_order” argument.
CALL catalog.system.rewrite_data_files( table => 'db.teams', strategy => 'sort', sort_order => 'team ASC NULLS LAST' )
When specifying your sort order you can specify multiple columns to sort by and must specify how nulls should be treated. So if you want to sort each team by their name after the initial team sort, it would look like this:
CALL catalog.system.rewrite_data_files( table => 'db.teams', strategy => 'sort', sort_order => 'team ASC NULLS LAST, name DESC NULLS FIRST' )
Z-Order Sorting
Z-order clustering can be a powerful way to optimize tables often filtered by multiple dimensions. Z-order sorting differs from multi-column sorting because Z-order weights all the columns being sorted equally (it doesn’t do one sort than the other).
To illustrate how this works, imagine that you wanted to sort a table by height_in_cm and age and you plotted all the records into four quadrants like the following:
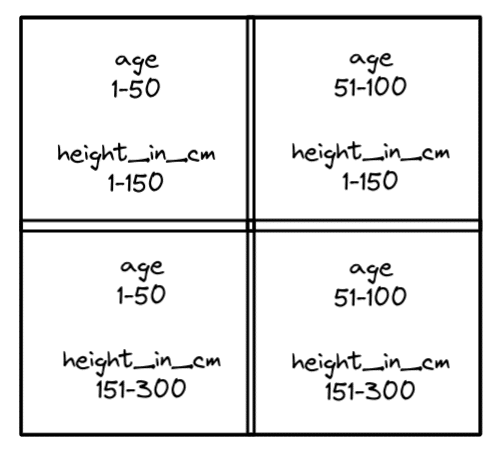
So you put all records into these four quadrants and then write them to appropriate files. This will maximize the benefit of min/max filter when both dimensions are typically involved in the query. So if you searched for someone of age 25 who is 200cm in height, the records you need would be located in only the files that records in the bottom-left quadrant were written to.
Z-order sorting can repeat multiple times, creating another four quadrants within a quadrant for even further fine-tuned clusters. For example, if the bottom-left quadrant were further Z-ordered, it would look like this:
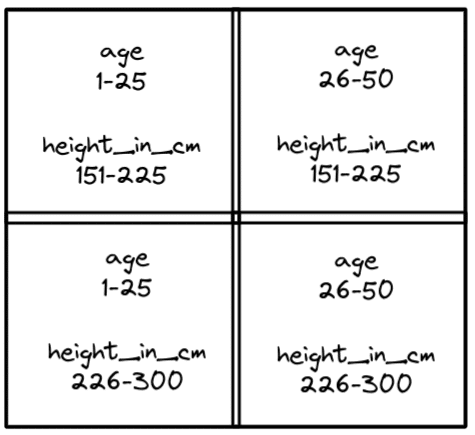
The result is a very effective file pruning anytime you filter by age and height_in_cm. To configure the compaction job to take advantage of Z-order clustering you would just run a compaction job like so:
CALL catalog.system.rewrite_data_files( table => 'db.people', strategy => 'sort', sort_order => 'zorder(height_in_cm, age)' )
Conclusion
Running compaction jobs on your Apache Iceberg tables can help you improve their performance but you have to balance out the level of optimization with your needs. If you run frequent compaction that need to be completed quickly, you are better off avoiding sorting and using the binpack strategy.
Although, if you want better optimization of reads, using sort can maximize the compaction benefit (use Z-order when multiple dimensions are often queried). Apache Iceberg gives you powerful compaction options to make sure your table performance is blazing fast on your data lakehouse.
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Dremio Blog: Product Insights,
Learn More ->

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.
Dremio Blog: Product Insights,
Learn More ->