18 minute read · September 13, 2022
How Z-Ordering in Apache Iceberg Helps Improve Performance
· Developer Advocate, Dremio

So you have adopted or are thinking about testing Apache Iceberg as the table format for organizing and managing all the raw data files (Parquet, ORC, etc.) that land in your data lake. You can now perform data warehouse-level operations such as insert, update, and delete directly on the data in your lake and, most notably, in a transactionally consistent way. Things are going great — your data is in an open format, multiple engines can use data based on specific use cases, and you don’t have to pay a hefty cost for a data warehouse.
But that’s really just the beginning of your journey. Querying hundreds of petabytes of data from a data lake table demands optimized query speed. Your queries are fast today, but they might not be over time. You have to ensure your queries stay efficient as more and more files accumulate in the data lake, because over time you may end up with the following scenarios:
- Your query patterns may change
- New query patterns may be added
- Queries may be slow because of unorganized files
Let’s Dig Deeper
To efficiently answer a query request, the goal should be to read as little data as possible. Iceberg facilitates techniques such as partitioning, pruning, and min/max filtering to skip data files that do not match the query predicate. You can read more about all the techniques here.
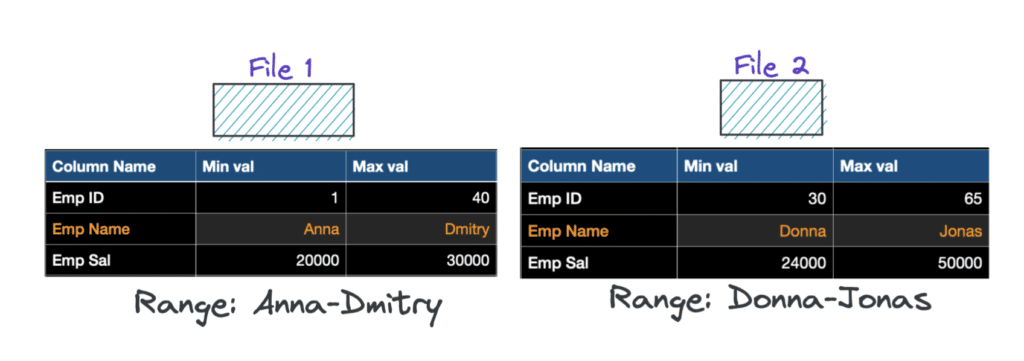
Using column-level stats from Iceberg manifest files (example here) allows query engines to skip data files, thus enabling faster queries. However, the physical layout of the data matters a lot for it to be effective. For example, consider a scenario with overlapping metrics like the one below.

As you can see, the metrics in both of these files are very similar. File 1 has an Emp Name column in the range from A-J, and File 2 also has the same range (A-J).
Let’s say you run the following query:
SELECT * FROM Employee WHERE Emp Name = 'Dennis'
Since this query has a predicate on the Emp Name field, and the value ‘Dennis’ is between A-J (which exists in both the files), the query engine has to look into both. Now, that means the min/max statistics of the files weren’t really helpful in this particular case, right?
So for situations like this, can you optimize the layout of the data within each file and further compliment the data skipping process? For sure, which is the focus of this blog.
Reorganizing Data Within Files
A common strategy to address the overlapping metrics scenario described above is to sort the data within a file based on the metrics. Sorting the whole dataset, reorders the data in such a way that each data file ends up with a unique range of values for the specific column it is sorted on. And, of course, you can add other columns to the already sorted column in a hierarchical fashion. So, in this example, you can sort the Emp Name column and rewrite the files so that each file has a specific range like below.
SELECT * FROM Employee WHERE Emp Name = 'Dennis'
If you execute the above SELECT query now, the query engine has to read only File 1 as the range for the Emp Name column is Anna-Dmitry in that file. Therefore, by changing the layout of the data using a technique like sorting, you are able to answer the query by reading only half the data files, which is very helpful.
You could also hierarchically sort columns, i.e., first sort by Emp Name followed by Emp Sal and Emp ID, if you have a query with a filter on all three fields such as:
SELECT * FROM Employee WHERE Emp Name='Dennis' AND Emp Sal=25000 AND Emp ID=22

The engine will take every predicate Emp Name = ‘Dennis’, Emp Sal = 25000, Emp ID = 22 and compare the min-max ranges of each column to filter files.
However, for queries (see below) without a filter on the first sorted column, i.e. Emp Name, the min-max ranges of the other columns may not be beneficial to skip data files.
SELECT * FROM Employee WHERE Emp Sal>18000
Why?
This is because the engine will first sort the data with Emp Name, then scatter the rest of the data (for the other columns) based on the Emp Name column. Let’s take a look at a hypothetical scenario. Consider that the table has two columns: Emp Name and Emp Sal. The range of the Emp Name column is [Anna-Julien] and Emp Sal is [10000-20000].

Now if you sort this table in the order Emp Name, Emp Sal, and rewrite it into four files evenly, the files may look something like below:
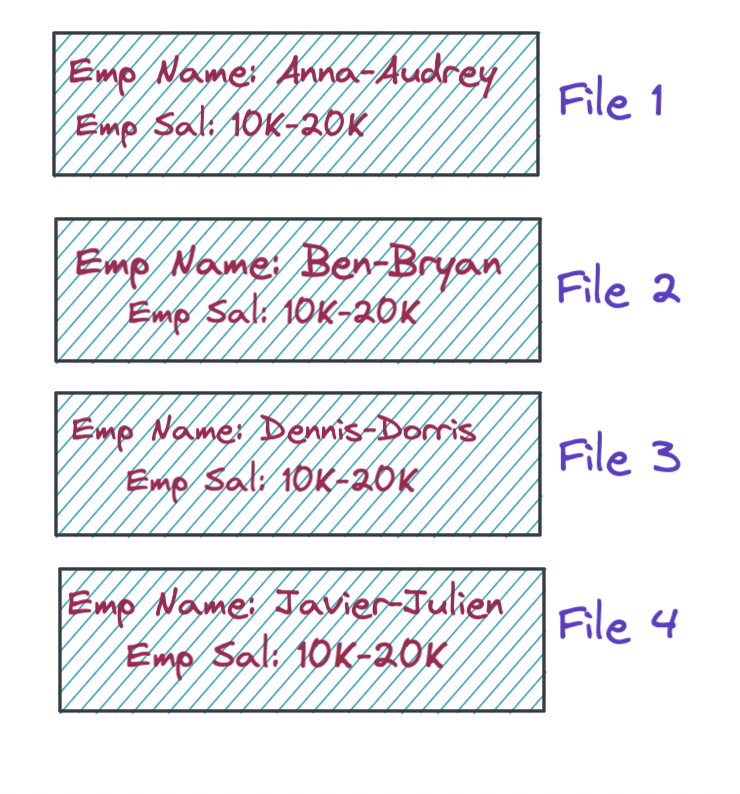
So, the first file contains all the Emp Name in the [A-*] range and Emp Sal [10K, 20K]. Similarly, the second file has Emp Name data in the [B-*] range and Emp Sal [10K, 20K] and so on.
If you run the same query SELECT * FROM Employee WHERE Emp Sal>18000 which has a filter on the Emp Sal column instead of the first sorted column, you are now back to the same problem again — the engine still has to scan all four files.
So, in the case of hierarchical sorting, you will only benefit if you have a predicate on the first sorted column. The engine cannot take advantage if predicates are on the other fields in that hierarchy. But how do you optimize the queries when you have multiple dimensions to filter on?
Another important aspect to consider while reorganizing the data is to keep the closely related data points in the same file as they would have been in a high dimension space. For instance, check out this table:
| Emp Name | Emp Sal | Emp ID | Years of exp (YOE) |
| Anna | 14000 | 10 | 5 |
| Dennis | 8000 | 16 | 2 |
| John | 15000 | 13 | 6 |
| Bryan | 20000 | 14 | 3 |
If you look at the two employees Anna and John, they are very close to each other if you represent them in two dimensions by Emp Sal and YOE.
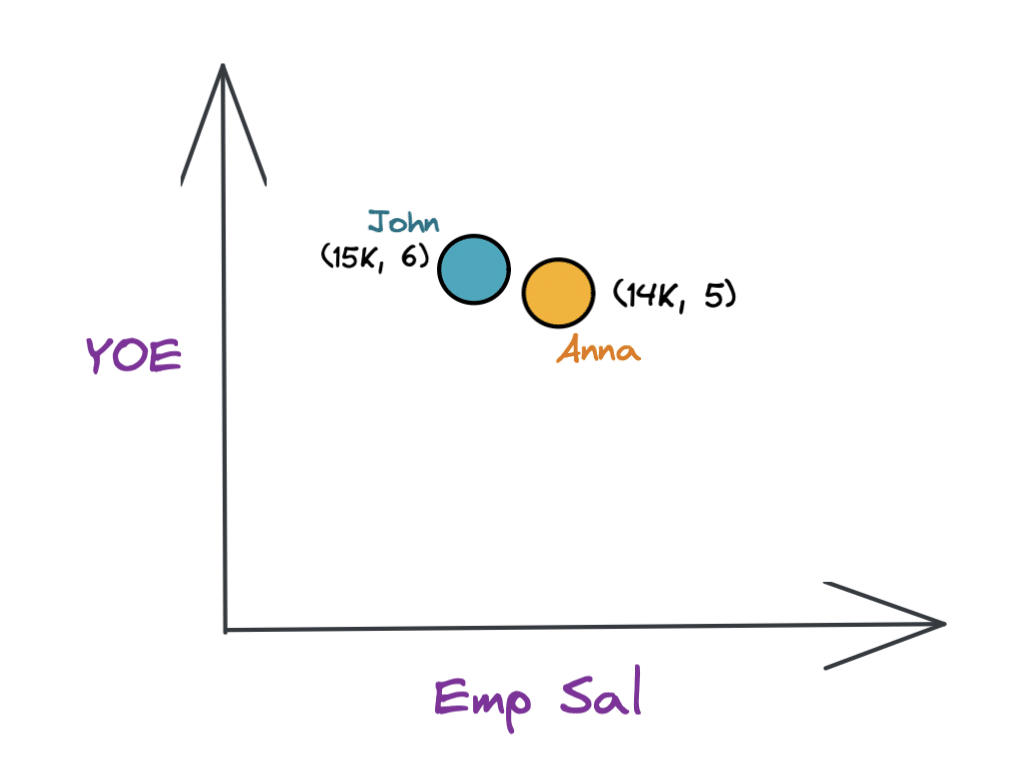
Now, let’s say you want to run a query on the above table, for example: “Give me all the employees who are 5+ years experienced and have salaries over 10000”. This query would require you to combine both predicates (Emp Sal and YOE) to narrow down your query search results.
In an ideal world, when you group the data files by sorting, you want to have all the employees with similar data points (Emp Sal and YOE) stay together in the same file. Otherwise, the query engine has to read data from multiple files, which means more I/O, which is ineffective. So for queries like this, you want to be able to preserve the locality of the points, so they stay close even when they are projected to a single dimension. Enter the Z-order curve!
Z-Order Clustering
Two key problems were discussed above:
- Overlapping metrics (same min/max range across files)
- Keeping similar data points together
These problems ultimately boil down to one question: Can you use information from multiple columns in a more integrated way (i.e., together) versus independently to better cluster data by multiple fields and achieve effective file skipping?
The good news is that you can do this with Z-order clustering.

A Z-order curve, by definition, is a type of space-filling curve that keeps similar data points together when mapped from a higher to lower dimension (e.g., 3-D to 2-D).
This blog does not go into the depth on the math behind Z-order (you can read more here), but at a high level, the idea is to touch all the data points by drawing Zs through them (as shown in the figure above) to keep similar points closer.
So now, if you go back to the employee example and organize (cluster) the files based on the Z-curve, you should be able to use information from both the columns for clustering the data using Z-values*. And if you want to run the same query now to get all the employees with experience >5 years and salary >10K, the engine can fetch the data from just one file (File 2) as depicted in the image below.
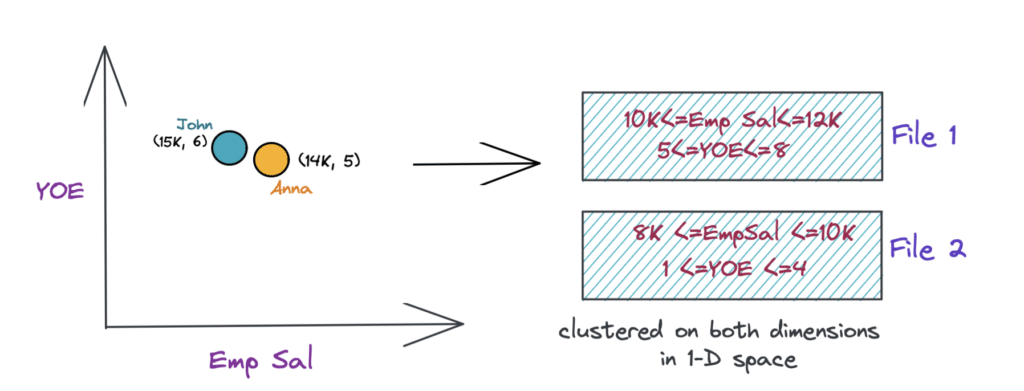
Using Z-order clustering, you can now be efficient with predicates on multiple columns and also keep similar data together. This allows you to have better min/max pruning and I/O compression so you can efficiently skip data files resulting in faster queries.
*The Z-values for the individual data points are calculated using an interleaving bits method. You can read more on Z-order here.
When to Use Z-Order vs. When Not To?
Z-ordering is a technique you can use to optimize the layout of the data stored in a data lake table. However, it is important to know when to use Z-order and when not to use Z-order, as well as on which columns.
Some common scenarios are:
- Consider Z-order for frequently run queries when you want to filter data using multiple dimensions. If most or all of your queries only filter on a single column, normal sorting should work fine.
- Z-order works best with data that have similar distribution and range. For example, geospatial, IoT data . Z-order keeps similar types of data in the same file to efficiently skip data files.This is not possible with normal/hierarchical sorting.
- Z-ordering on fields with a very small distribution range isn’t beneficial as the data points are already close to each other. In such cases, normal sorting would work best.
- Columns with high cardinality (large number of distinct values) are best suited for Z-ordering.
Z-Order in Apache Iceberg

Apache Iceberg provides the ability to organize the layout of the data within the files using the Z-ordering technique.
One way to use this optimization strategy is to leverage the rewrite_data_files action in Spark, which already enabled compacting smaller files and organizing data within files using methods such as bin-pack and sorting. The addition of this new clustering strategy makes the process of skipping files more efficient by complementing techniques such as min/max pruning.
So now let’s apply the Z-order clustering method to the Iceberg table Employee. To do so, first you need to run the Spark action rewrite_data_files with the following parameters:
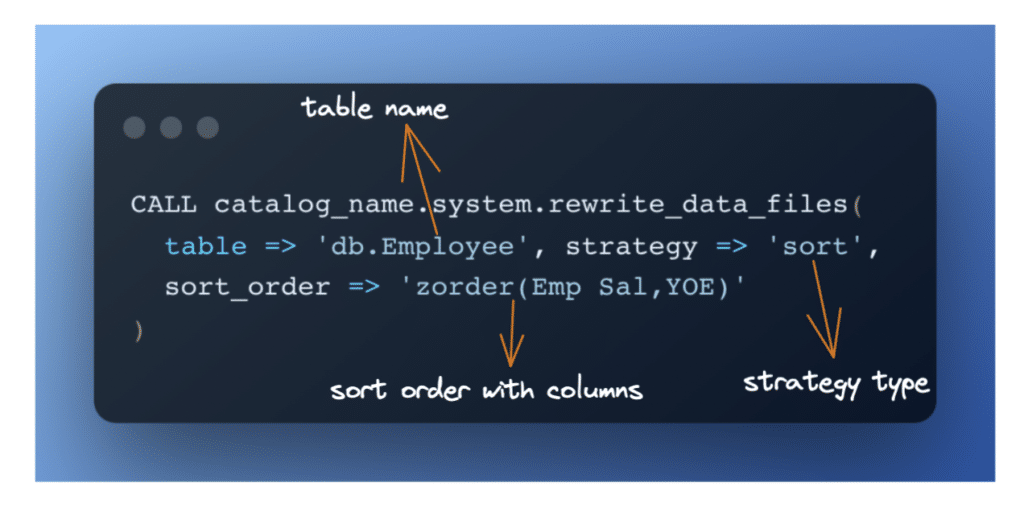
Now when you run the query below, the engine only has to scan one file.
SELECT * FROM Employee WHERE Emp Sal>10000 AND YOE>5
Considerations
In a real-world setting, it is important to consider when to optimize data files using Z-order as it is a comparatively costly operation. Therefore, there is often a trade-off between the performance needed versus the cost to Z-order. Depending on an organization’s maintenance strategy — weekly, monthly, etc. — Z-order can be automated using scheduling tools/jobs. It might also be a good idea to set some thresholds, such as looking at the number of small files using the metadata table, query patterns, etc., to automate Z-order clustering.
Conclusion
Maintaining data files and optimally laying out the data within them is critical in querying petabytes of data stored in a data lake. By leveraging Apache Iceberg’s out-of-the-box Z-order clustering technique, you can preserve your data’s locality and efficiently skip data files even with multiple query predicates.
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Dremio Blog: Product Insights,
Learn More ->

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->