47 minute read · April 18, 2022
Comparison of Data Lake Table Formats (Apache Iceberg, Apache Hudi and Delta Lake)
· Senior Tech Evangelist, Dremio

by Alex Merced, Developer Advocate at Dremio
Article updated May 23, 2022 to reflect new support for Delta Lake multi-cluster writes on S3.
Article updated on May 12, 2022 to reflect additional tooling support and updates from the newly released Hudi 0.11.0.
Article updated on June 7, 2022 to reflect new flink support bug fix for Delta Lake OSS along with updating calculation of contributions to better reflect committers employer at the time of commits for top contributors.
Article updated on June 28, 2022 to reflect new Delta Lake open source announcement and other updates.
Article was updated on April 13, 2023 first route of revisions including some updates of summary of github stats in main summary chart and some newer pie charts of % contributions. I made some updates to engine support, will make deeper update later on.
Update to engine support August 7th, 2023 main changes seen in Apache Beam and Redshift in the engines being tracked.
What Is a Table Format?
Table formats allow us to interact with data lakes as easily as we interact with databases, using our favorite tools and languages. A table format allows us to abstract different data files as a singular dataset, a table.
Data in a data lake can often be stretched across several files. We can engineer and analyze this data using R, Python, Scala and Java using tools like Spark and Flink. Being able to define groups of these files as a single dataset, such as a table, makes analyzing them much easier (versus manually grouping files, or analyzing one file at a time). On top of that, SQL depends on the idea of a table and SQL is probably the most accessible language for conducting analytics.
Hive: A First-Generation Table Format
The original table format was Apache Hive. In Hive, a table is defined as all the files in one or more particular directories. While this enabled SQL expressions and other analytics to be run on a data lake, It couldn’t effectively scale to the volumes and complexity of analytics needed to meet today’s needs. Other table formats were developed to provide the scalability required.
The Next Generation
Introducing: Apache Iceberg, Apache Hudi, and Databricks Delta Lake. All three take a similar approach of leveraging metadata to handle the heavy lifting. Metadata structures are used to define:
- What is the table?
- What is the table’s schema?
- How is the table partitioned?
- What data files make up the table?
While starting from a similar premise, each format has many differences, which may make one table format more compelling than another when it comes to enabling analytics on your data lake.
 |
|||
| ACID Transactions | |||
| Partition Evolution | |||
| Schema Evolution (later chart with more detail) |
|||
| Time-Travel | |||
| Project Governance | Apache Project with a diverse PMC (top-level project) |
Apache Project with a diverse PMC (top-level project) |
Linux Foundation Project with an all-Databricks TSC |
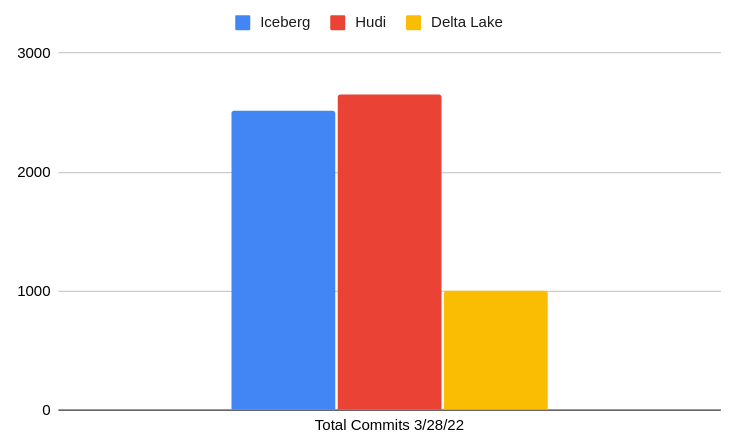
| Community Contributions (stats as of 4/13/23) |
347 contributors, 3836 merged PRs, 465 open PRs |
379 contributors, 4496 merged PRs, 393 open PRs |
231 contributors, 26 merged PRs, 73 open PRs |
| Tool Read Compatibility | Apache Hive, Dremio Sonar, Apache Flink, Apache Spark, Presto, Trino, Athena, Snowflake, Databricks Spark, Apache Impala, Apache Drill, BigQuery | Apache Hive, Apache Flink, Apache Spark, Presto, Trino, Athena, Databricks Spark, Redshift, Apache Impala, BigQuery | Apache Hive, Dremio Sonar, Apache Flink, Databricks Spark, Apache Spark, Databricks SQL Analytics, Trino, Presto, Snowflake, Redshift, Apache Beam, Athena |
| Tool Write Compatibility | Apache Hive, Dremio Sonar, Apache Flink, Apache Spark, Trino, Athena, Databricks Spark, Debezium, Kafka Connect, BigQuery, Snowflake | Apache Flink, Apache Spark, Databricks Spark, Debezium, Kafka Connect | OSS Delta Lake: Trino, Apache Spark, Databricks Spark Apache Flink, Debezium, Athena Databricks Delta Lake: Databricks Spark, Kafka Connect |
| File Format Support | Parquet, ORC, AVRO | Parquet, ORC | Parquet |
* Note Regarding Delta Lake and Spark
This article will primarily focus on comparing open-source table formats that enable you to run analytics using open architecture on your data lake using different engines and tools so we will be focusing on the open-source version of Delta Lake. Open architectures help minimize costs, avoid vendor lock-in, and ensure the latest and best-in-breed tools can always be available on your data.
Keep in mind Databricks has its own proprietary fork of Delta Lake, which has features only available on the Databricks platform. This is also true of Spark - Databricks-managed Spark clusters run a proprietary fork of Spark with features only available to Databricks customers. These proprietary forks aren’t open to enable other engines and tools to take full advantage of them, so they are not this article's focus.
ACID Transactions
One of the benefits of moving away from Hive’s directory-based approach is that it opens a new possibility of having ACID (Atomicity, Consistency, Isolation, Durability) guarantees on more types of transactions, such as inserts, deletes, and updates. In addition to ACID functionality, next-generation table formats enable these operations to run concurrently.
Apache Iceberg
Apache Iceberg’s approach is to define the table through three categories of metadata. These categories are:
- “metadata files” that define the table
- “manifest lists” that define a snapshot of the table
- “manifests” that define groups of data files that may be part of one or more snapshots
Query optimization and all of Iceberg’s features are enabled by the data in these three layers of metadata.
Through the metadata tree (i.e., metadata files, manifest lists, and manifests), Iceberg provides snapshot isolation and ACID support. When a query is run, Iceberg will use the latest snapshot unless otherwise stated. Writes to any given table create a new snapshot, which does not affect concurrent queries. Concurrent writes are handled through optimistic concurrency (whoever writes the new snapshot first, does so, and other writes are reattempted).
Beyond the typical creates, inserts, and merges, row-level updates and deletes are also possible with Apache Iceberg. All of these transactions are possible using SQL commands.
Apache Hudi
Apache Hudi’s approach is to group all transactions into different types of actions that occur along a timeline. Hudi uses a directory-based approach with files that are timestamped and log files that track changes to the records in that data file. Hudi allows you the option to enable a metadata table for query optimization (The metadata table is now on by default starting in version 0.11.0). This table will track a list of files that can be used for query planning instead of file operations, avoiding a potential bottleneck for large datasets.
Apache Hudi also has atomic transactions and SQL support for CREATE TABLE, INSERT, UPDATE, DELETE and Queries
Delta Lake
Delta Lake’s approach is to track metadata in two types of files:
- Delta Logs sequentially track changes to the table.
- Checkpoints summarize all changes to the table up to that point minus transactions that cancel each other out.
Delta Lake also supports ACID transactions and includes SQ L support for creates, inserts, merges, updates, and deletes.
Partition Evolution
Partitions allow for more efficient queries that don’t scan the full depth of a table every time. Partitions are an important concept when you are organizing the data to be queried effectively. Often, the partitioning scheme of a table will need to change over time. With Hive, changing partitioning schemes is a very heavy operation. If data was partitioned by year and we wanted to change it to be partitioned by month, it would require a rewrite of the entire table. More efficient partitioning is needed for managing data at scale.
Partition evolution allows us to update the partition scheme of a table without having to rewrite all the previous data.
Apache Iceberg
Apache Iceberg is currently the only table format with partition evolution support. Partitions are tracked based on the partition column and the transform on the column (like transforming a timestamp into a day or year).
This is different from typical approaches, which rely on the values of a particular column and often require making new columns just for partitioning. With the traditional way, pre-Iceberg, data consumers would need to know to filter by the partition column to get the benefits of the partition (a query that includes a filter on a timestamp column but not on the partition column derived from that timestamp would result in a full table scan). This is a huge barrier to enabling broad usage of any underlying system. Iceberg enables great functionality for getting maximum value from partitions and delivering performance even for non-expert users.
Delta Lake
Delta Lake does not support partition evolution. It can achieve something similar to hidden partitioning with its generated columns feature which is currently in public preview for Databricks Delta Lake, still awaiting full support for OSS Delta Lake.
|
|||
| Add a new column | |||
| Drop a column | |||
| Rename a column | |||
| Update a column | |||
| Reorder columns |
Time-Travel
Time travel allows us to query a table at its previous states. A common use case is to test updated machine learning algorithms on the same data used in previous model tests. Comparing models against the same data is required to properly understand the changes to a model.
In general, all formats enable time travel through “snapshots.” Each snapshot contains the files associated with it. Periodically, you’ll want to clean up older, unneeded snapshots to prevent unnecessary storage costs. Each table format has different tools for maintaining snapshots, and once a snapshot is removed you can no longer time-travel to that snapshot.
Apache Iceberg
Every time an update is made to an Iceberg table, a snapshot is created. You can specify a snapshot-id or timestamp and query the data as it was with Apache Iceberg. To maintain Apache Iceberg tables you’ll want to periodically expire snapshots using the expireSnapshots procedure to reduce the number of files stored (for instance, you may want to expire all snapshots older than the current year.). Once a snapshot is expired you can’t time-travel back to it.
|
|||
| Apache Governed Project | |||
| Open Source License | Apache | Apache | Apache |
| First Open Source Commit | 12/13/2017 | 12/16/2016 | 4/12/2019 |
Many projects are created out of a need at a particular company. Apache Iceberg came out of Netflix, Hudi out of Uber, and Delta Lake out of Databricks.
There are many different types of open-source licensing, including the popular Apache license. Before becoming an Apache Project, reporting, governance, technical, branding, and community standards must be met. The Apache Project status assures that there is a fair governing body behind a project and that the commercial influences of any particular company aren’t steering it.
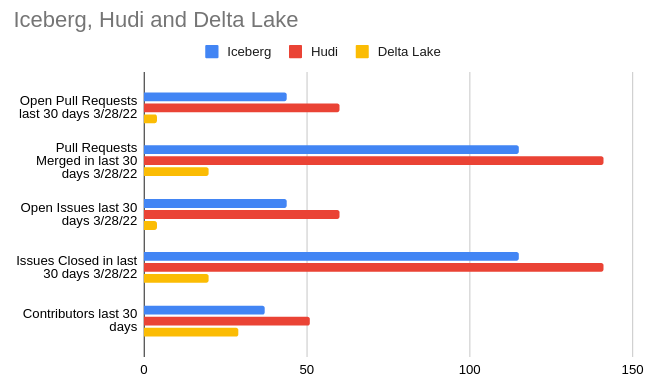
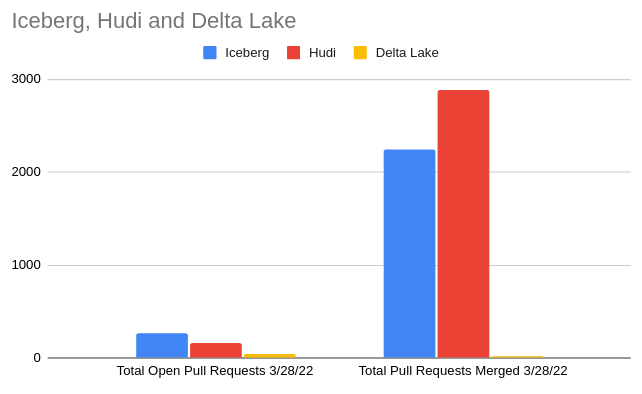
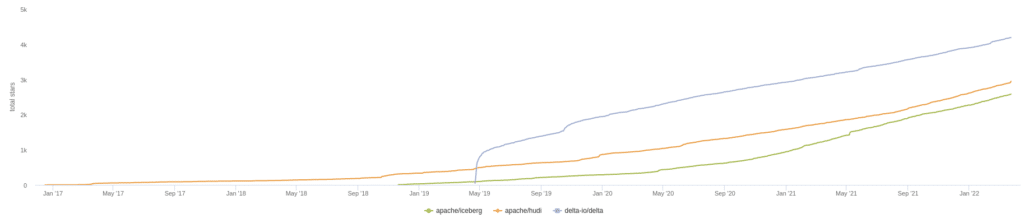
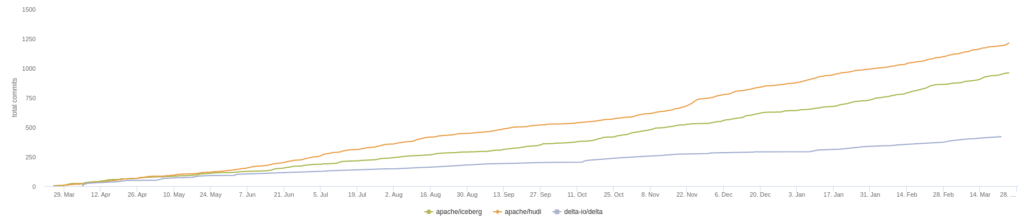
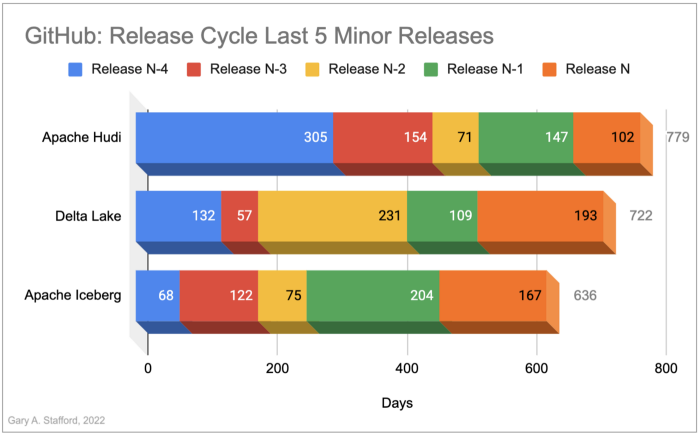
In the chart above we see the summary of current GitHub stats over a 30-day period, which illustrates the current moment of contributions to a particular project. When choosing an open-source project to build your data architecture around you want strong contribution momentum to ensure the project's long-term support. Let’s look at several other metrics relating to the activity in each project’s GitHub repository and discuss why they matter.

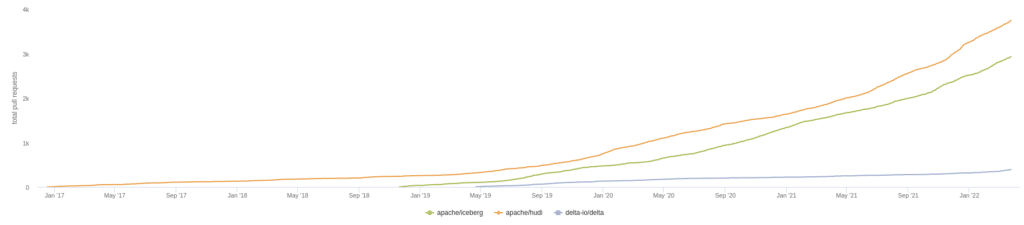
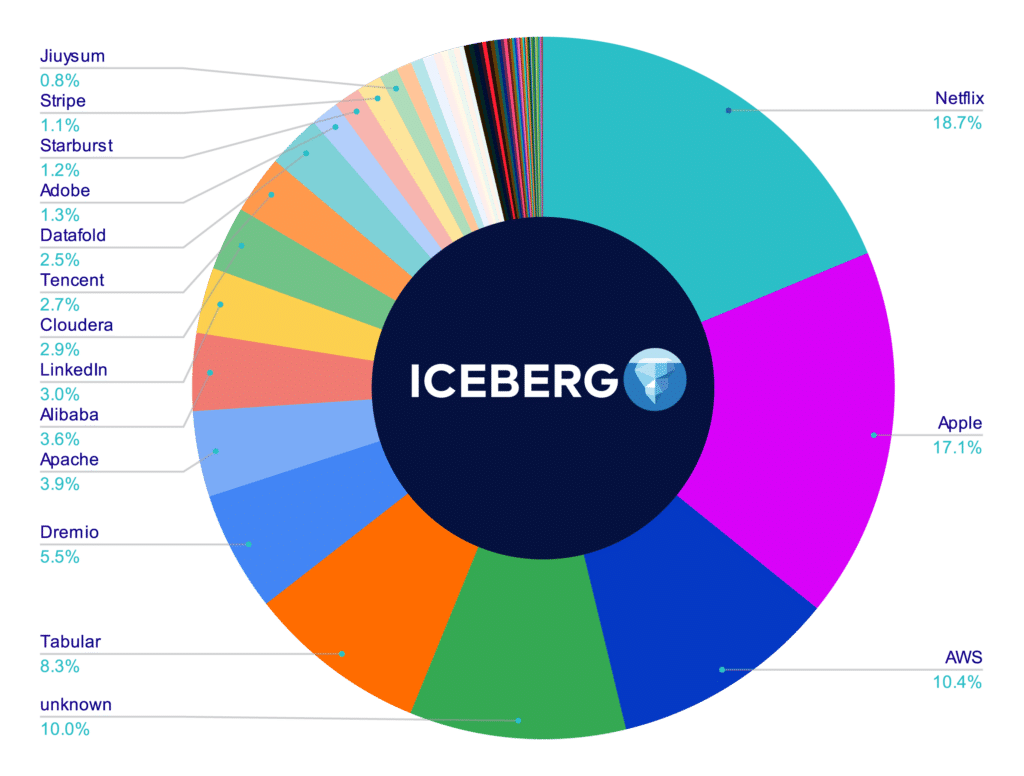
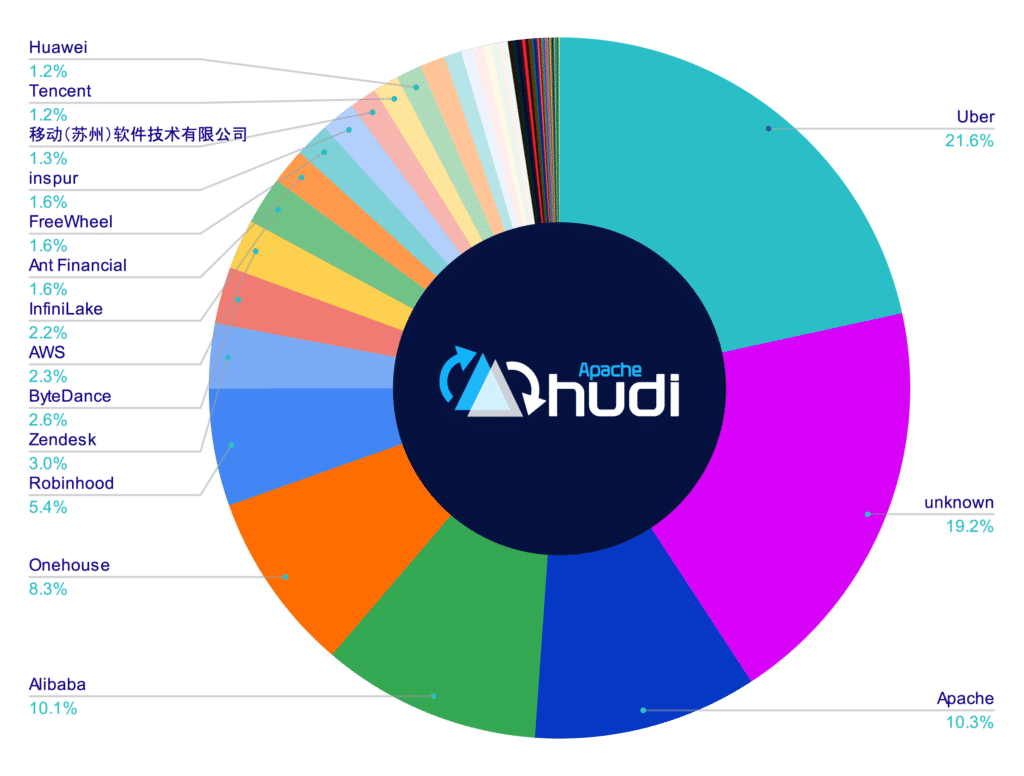
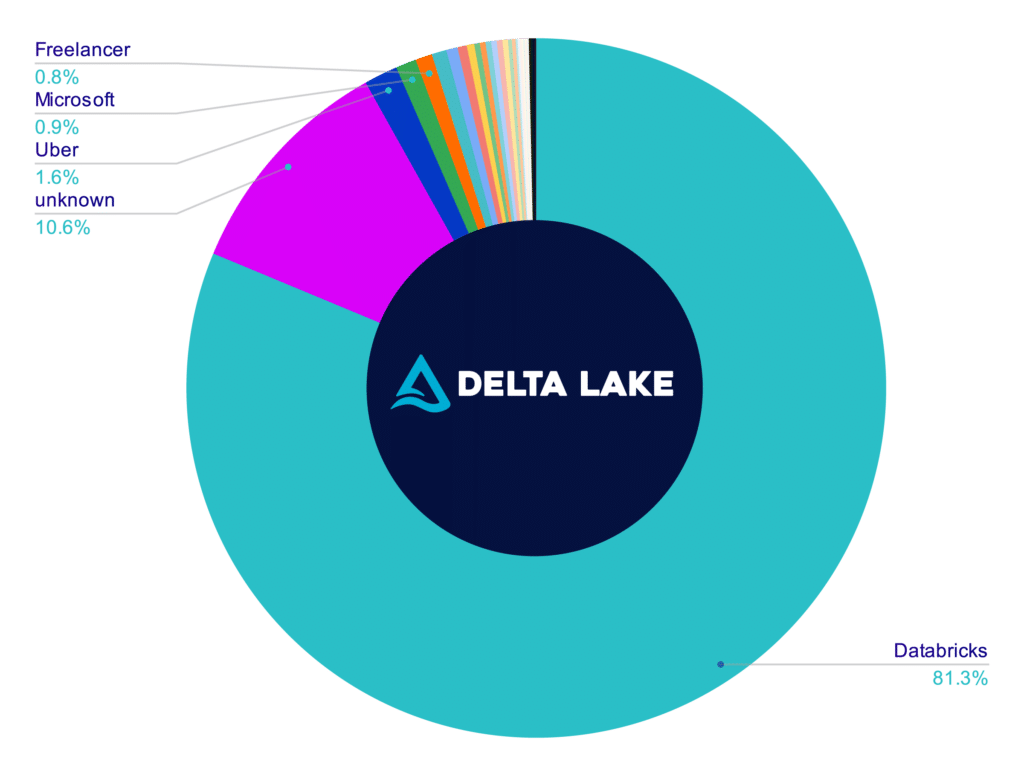
Attributable Repository Contributors
[UPDATE] On January 13th, 2023 the number on the apache/iceberg and delta-io/delta repositories were calculated again using the same methodology as the above. The charts below represent the results; in this run, all contributors whose company could not be researched were removed so this only accounts for contributors whose contributions could be attributed to a particular company versus the charts above, which included "unknown" contributors". If you want to recalculate these values, you can find my scripts and methodology in this repository.
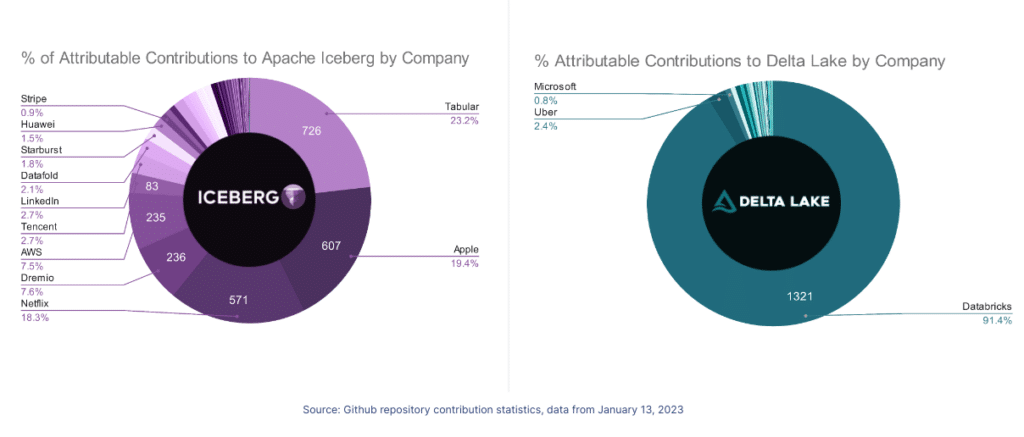
When you’re looking at an open source project, two things matter quite a bit:
-
- Number of community contributions
-
- Whether the project is community governed
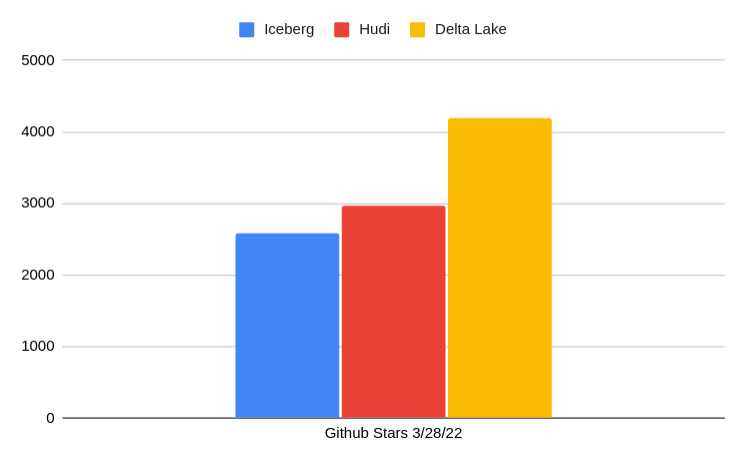
Community contributions matter because they can signal whether the project will be sustainable for the long haul. Community governed matters because when one particular party has too much control of the governance it can result in unintentional prioritization of issues and pull requests towards that party’s particular interests.
|
|||
| Apache Flink | Read & Write | Read & Write | Read & Write |
| Apache Spark | Read & Write | Read & Write | Read & Write |
| Databricks Spark | Read & Write | Read & Write | Read & Write |
| Dremio Sonar | Read & Write | Read | |
| Presto | Read & Write | Read | Read |
| Trino | Read & Write | Read | Read & Write |
| Athena | Read & Write | Read | Read & Write |
| Snowflake | Read & Write | Read | |
| Apache Impala | Read & Write | Read & Write | |
| Apache Beam | Pending | Read | |
| Apache Drill | Read | Read | |
| AWS Redshift | Read | Read | Read |
| BigQuery | Write & Read | Read | |
| Debezium | Write | Write | Write |
| Kafka Connect | Write | Write | Write |
|
|||
| Parquet | |||
| AVRO | |||
| ORC |
Tutorials for Trying Out the Dremio Data Lakehouse Platform (all can be done from locally on your laptop):
-
- Lakehouse on Your Laptop with Apache Iceberg, Nessie and DremioExperience Dremio: dbt, git for data and moreFrom Postgres to Apache Iceberg to BI DashboardFrom MongoDB to Apache Iceberg to BI DashboardFrom SQLServer to Apache Iceberg to BI DashboardFrom MySQL to Apache Iceberg to BI DashboardFrom Elasticsearch to Apache Iceberg to BI DashboardFrom Apache Druid to Apache Iceberg to BI DashboardFrom JSON/CSV/Parquet to Apache to BI DashboardFrom Kafka to Apache Iceberg to Dremio
Tutorials of Dremio with Cloud Services (AWS, Snowflake, etc.)
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Dremio Blog: Product Insights,
Learn More ->

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->