17 minute read · July 26, 2022
Row-Level Changes on the Lakehouse: Copy-On-Write vs. Merge-On-Read in Apache Iceberg
· Senior Tech Evangelist, Dremio

Updating Tables on the Data Lake
The ability to update and delete rows in traditional databases is something that was always needed, and was always available, yet we took for granted. Data warehouses, which are essentially specialized databases for analytics, have been around a long time and evolved from those very features. They are easier to implement as they internally handle the storage and processing of data.
Data lakes exist to solve cost and scale challenges, and is achieved by using independent technologies to solve problems like storage, compute and more. Storage at scale was solved by the advent of cloud object storage, and compute engines evolved to handle read-only queries at scale. In today’s world, the idea of the data lakehouse promises cost savings and scalability in moving traditionally data warehouse workloads to the data lake.
To facilitate these kinds of workloads, which include many write-intensive workloads, data lakes needed new abstractions between storage and compute to help provide ACID guarantees and performance. And this is what data lake table formats provide: a layer of abstraction for data lakehouse engines to look at your data as well-defined tables that can be operated on at scale.
Apache Iceberg is a table format that serves as the layer between storage and compute to provide analytics at scale on the lake, manifesting the promise of the data lakehouse.
While Apache Iceberg delivers ACID guarantees with updates/deletes to the data lakehouse, version 2 (v2) of the Apache Iceberg table format offers the ability to update and delete rows to enable more use cases. V2 of the format enables updating and deleting individual rows in immutable data files without rewriting the files.
There are two approaches to handle deletes and updates in the data lakehouse: copy-on-write (COW) and merge-on-read (MOR).
Like with almost everything in computing, there isn’t a one-size-fits-all approach – each strategy has trade-offs that make it the better choice in certain situations. The considerations largely come down to latency on the read versus write side. These considerations aren't unique to Iceberg or data lakes in general, the same considerations and trade-offs exist in many other places, such as lambda architecture.
The following walks through how each of the strategies work, identifies their pros and cons, and discusses which situations are best for their use.
Copy-On-Write (COW) – Best for tables with frequent reads, infrequent writes/updates, or large batch updates
With COW, when a change is made to delete or update a particular row or rows, the datafiles with those rows are duplicated, but the new version has the updated rows. This makes writes slower depending on how many data files must be re-written which can lead to concurrent writes having conflicts and potentially exceeding the number of reattempts and failing.
If updating a large number of rows, COW is ideal. However, if updating just a few rows you still have to rewrite the entire data file, making small or frequent changes expensive.
On the read side, COW is ideal as there is no additional data processing needed for reads – the read query has nice big files to read with high throughput.

| Summary of COW (Copy-On-Write) | |
| PROS | CONS |
| Fastest reads | Expensive writes |
| Good for infrequent updates/deletes | Bad for frequent updates/deletes |
Merge-On-Read (MOR) – Best for tables with frequent writes/updates
With merge-on-read, the file is not rewritten, instead the changes are written to a new file. Then when the data is read, the changes are applied or merged to the original data file to form the new state of the data during processing.
This makes writing the changes much quicker, but also means more work must be done when the data is read.
In Apache Iceberg tables, this pattern is implemented through the use of delete files that track updates to existing data files.
If you delete a row, it gets added to a delete file and reconciled on each subsequent read till the files undergo compaction which will rewrite all the data into new files that won’t require the need for the delete file.
If you update a row, that row is tracked via a delete file so future reads ignore it from the old data file and the updated row is added to a new data file. Again, once compaction is run, all the data will be in fewer data files and the delete files will no longer be needed.
So when a query is underway the changes listed in the delete files will be applied to the appropriate data files before executing the query.
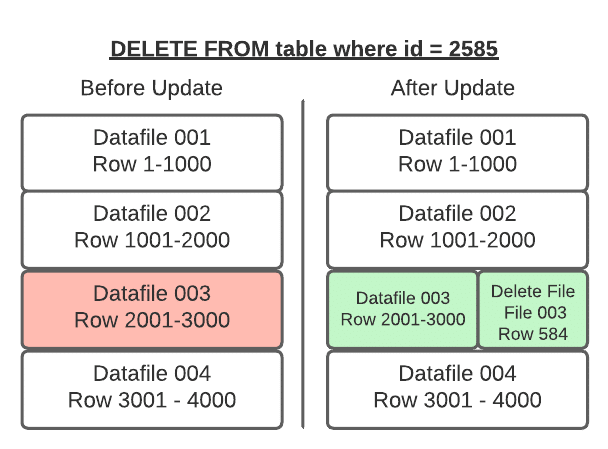
Position Deletes
Position deletes still read files to determine which records are deleted, but instead of rewriting the data files after the read, it only writes a delete file that tracks the file and position in that file of records to be deleted. This strategy greatly reduces write times for updates and deletes, and there is a minor cost to merge the delete files at read time.
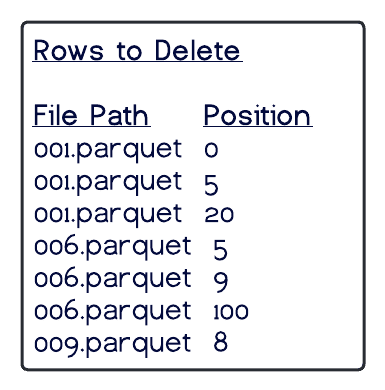
Equality Deletes
When using equality deletes, you save even more time during the write by avoiding reading any files at all. Instead, the delete file is written to include the fields and values that are targeted by the query. This makes update/delete writes much faster than using position deletes. However, there is a much higher cost on the read time since it will have to match the delete criteria against all scanned rows to reconcile at read, which can be quite costly.

Minimizing the Read Costs
When running compaction, new data files will be written to reconcile any existing delete files, eliminating the need to reconcile them during read queries. So when using merge-on-read, it is recommended to have regular compaction jobs to impact reads as little as possible while still maintaining the faster write speeds.
Types of Delete Files Summary
| How it works | Pros | Cons | How to manage read costs | Good fit | |
| Position | Tracks file path and row position in file | Fast writes | Slower reads | Run compaction jobs regularly | Better for frequent updates/deletes in which copy- on-write is not fast enough |
| Equality | Tracks query criteria for delete/update targets | Super-fast writes | Much slower reads | For when updates/deletes with position deletes is still not fast enough |
| How it works | Pros | Cons | How to manage read costs | Good fit | |
| Position | Tracks file path and row position in file | Fast writes | Slower reads | Run compaction jobs regularly | Better for frequent updates/deletes in which copy- on-write is not fast enough |
| Equality | Tracks query criteria for delete/update targets | Super- fast writes | Much slower reads | For when updates/deletes with position deletes is still not fast enough |
When to Use COW and When to Use MOR
Architecting your tables to take advantage of COW, MOR/Position deletes or MOR/Equality deletes is based on how the table will be used.
Note that you can choose a strategy you believe is the best option for your table, and if it turns out to be the wrong choice or the workloads change, it’s easy to change the table to use another.
| Approach | Update/Delete Frequency | Insert Performance | Update/Delete Latency/Performance | Read Latency/ Performance |
| Copy-On-Write | Infrequent updates/deletes | Same | Slowest | Fastest |
| Merge-On-Read Position Deletes | Frequent updates/deletes | Same | Fast | Fast |
| Merge-On-Read Equality Deletes | Frequent updates/deletes where position delete MOR is still not fast enough on the write side | Same | Fastest | Slowest |
Configuring COW and MOR
COW and MOR are not an either/or proposition with Apache Iceberg. You can specify different modes in your table settings based on the type of operation, so you can specify deletes, updates, and merges as either COW or MOR independently. For example, you can set the settings when the table is created.
CREATE TABLE catalog.db.students (
id int,
first_name string,
last_name string,
major string,
class_year int
) TBLPROPERTIES (
'write.delete.mode'='copy-on-write',
'write.update.mode'='merge-on-read',
'write.merge.mode'='merge-on-read'
) PARTITIONED BY (class_year) USING iceberg; This can also be changed using ALTER TABLE statements:
ALTER TABLE catalog.db.students SET TBLPROPERTIES (
'write.delete.mode'='merge-on-read',
'write.update.mode'='copy-on-write',
'write.merge.mode'='copy-on-write'
);Further Optional Delete/Updates Fine-Tuning Strategies
- Partitioning the table by fields that are often included in query filters, so if you regularly filter a field by a particular timestamp field during updates, then partitioning the table by that field will speed updates.
- Sorting the table by fields often included in the filters
(Example: if table partitioned byday(timestamp)setting the sort key totimestamp). - Tuning the metadata tracked for each individual column so extra metadata isn’t written for columns the table is rarely filtered by, ultimately wasting time on the write side. This can be done with the
write.metadata.metricscategory or properties to set a default rule and also customize each column.
ALTER TABLE catalog.db.students SET TBLPROPERTIES (
'write.metadata.metrics.column.col1'='none',
'write.metadata.metrics.column.col2'='full',
'write.metadata.metrics.column.col3'='counts',
'write.metadata.metrics.column.col4'='truncate(16)',
);- Fine-tuning at the engine level, which will differ based on the engine you are using. For example, for streaming ingestion where you’re confident there won’t be schema fluctuations in the incoming data, you may want to tweak certain Iceberg-specific Spark write settings such as disabling the “check-ordering” setting which would save time by not checking that the data being written has the fields in the same order as the table.
For further details on tuning row-level operations, check out Apple’s Anton Okolnychyi’s in-depth talk on fine-tuning row-level operations in Apache Iceberg at the 2022 Subsurface Live! conference.
With Apache Iceberg v2 tables, you now have more flexibility to handle deletes, updates, and upserts so you can choose the trade-offs between writes and reads to engineer the best performance for your particular workloads. Using copy-on-write, merge-on-read, position deletes, and equality deletes gives you the flexibility to tailor how engines update in your Iceberg tables.
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Dremio Blog: Product Insights,
Learn More ->

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->