19 minute read · November 29, 2022
Bringing the Semantic Layer to Life

· Principal Product Manager, Dremio


Future users of large data banks must be protected from having to know how the data is organized in the machine (the internal representation).
- E. F. Codd, A relational model of data for large shared data banks
Data teams can choose from a variety of data warehouses and query engines to support analytical workloads. In many cases, data teams also build a semantic layer on top of their data stores so their non-technical end users can work with their data in business-friendly terms.
Semantic layers aim to protect end users from the complexities of the underlying physical data model. End users should be able to use their semantic layer to understand what data exists, write queries or create dashboards (using business-friendly language), and then let the underlying system do whatever it needs to return results quickly.
However, this rarely happens in practice. While semantic layers make it easier for end users to understand their data, they don’t provide sufficient performance to support BI and analytics workloads. End users need to know about underlying physical structures, such as materialized views, to get the performance they need — which defeats the purpose of having a semantic layer in the first place.
In this blog, we’ll explore how Dremio’s semantic layer helps end users analyze massive datasets, without sacrificing speed or ease of use, by effectively decoupling the logical data model from its physical implementation. We’ll dive into one of the key technologies that makes this possible, and discuss how Dremio’s approach also benefits data engineers.
The problem with today’s approach
To help end users analyze data quickly, data teams build pipelines to create a variety of derived datasets, such as summary tables and materialized views, that pre-aggregate, pre-sort, and/or pre-filter data.
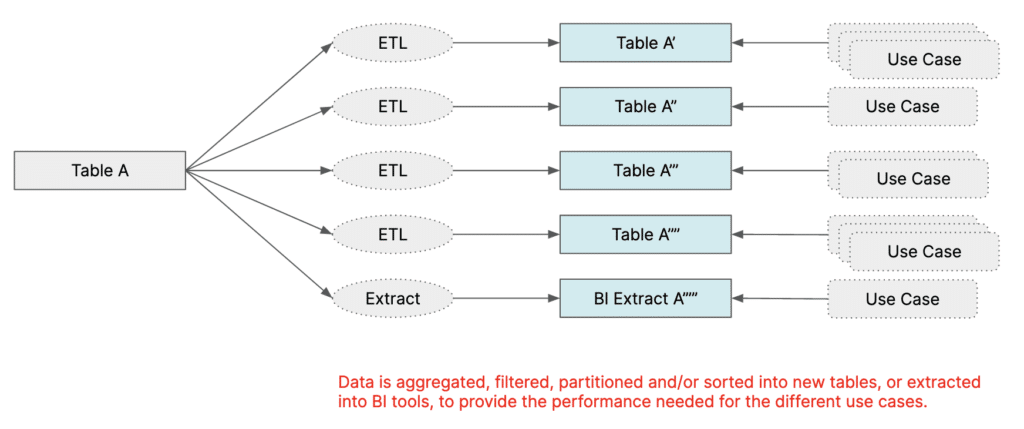
While these derived datasets can help end users accelerate their workloads, they come with drawbacks for both end users and data engineers:
- Limited scope: Each derived dataset is often narrow in scope and can only accelerate a limited set of use cases, so data engineers need to create many derived datasets to support different use cases. This results in sprawling physical copies of data and multiplies storage costs.
- Need maintenance: Derived datasets need to be updated regularly to ensure end users can run accurate analyses on fresh data. Each refresh consumes compute resources.
- Expensive to update: If end users want to alter their derived datasets in any way (e.g., by adding new columns or changing a column name), then data engineers need to update their dataset definitions and upstream ETL jobs. Similarly, if end users find that they need an entirely new derived dataset to support a new use case, then data engineers need to set up new ETL pipelines to create these new datasets. Each change request can take days or even weeks to complete.
- Communication overhead: End users need to work closely with data engineers to understand which derived datasets exist, which datasets could potentially accelerate their queries, and if their derived datasets are up-to-date (or stale and invalid). This slows down both data engineers and end users.
- Clunky experience for end users: End users usually need to explicitly mention the derived dataset as part of their query if they want to leverage it. For example,
SELECT * FROM catalog.salesschema.materialized_view_total_sales; - Result in even more data copies: If materialized views don’t work well enough, users create cubes and extracts in downstream tools — that are only available to that single tool, and still limited in scope and flexibility.
This approach to supporting analytics is complex and inhibits self-service data access. The latter issue is particularly problematic, as companies want to help more users, especially those who are non-technical, derive value from data in a self-service manner.
Dremio’s self-service semantic layer
At Dremio, we want to make data as easy as possible. One of the ways we do this is by enabling data architects to build a lakehouse architecture to support analytics — which is simpler, cheaper, and more open than a warehouse-centric architecture. Another key innovation that makes data easy is our semantic layer, which helps data engineers build a logical view of data, define common business logic and metrics across data sources, and expose data in business-friendly terms for end users.
Dremio’s semantic layer has two important differentiators that make data easy for end users. First, Dremio’s semantic layer gives end users a self-service experience to curate, analyze, and share datasets. In addition, query acceleration is completely transparent to end users, so analysts can quickly build out datasets and consume data without worrying about performance, and work completely in their logical data model. Every user and tool that connects to Dremio benefits from Dremio’s transparent query acceleration, so analysts can use BI tools as thin clients through a live connection, instead of having to create extracts and cubes for performance.
Making data easy and eliminating copies with Reflections
One of the key technologies in Dremio’s query acceleration toolbox that makes Dremio’s semantic layer so powerful is Reflections. Reflections are materializations that are aggregated, sorted, and partitioned in different ways and transparently accelerate queries — like indexes on steroids. Dremio persists reflections as Parquet files in your data lake.
Reflections are similar to materialized views, but have a few key differences:
- Easy to configure: Administrators can use a simple drag-and-drop UI to create and manage reflections, instead of writing lengthy SQL statements (Dremio does provide an API as well as SQL commands to manage reflections).
- Flexible: Reflections support joins and can contain data from one or more data sources, unlike materialized views in many other systems. Dremio also supports several types of reflections (e.g., raw and aggregation) to accelerate various workloads — from needle-in-haystack lookups to complex BI-style aggregations.
- Transparent: Reflections are completely transparent to end users, so end users can run workloads at interactive speed without needing to know about underlying physical structures. In fact, users can’t query reflections directly.
- Reusable: A single reflection can apply to many different use cases, so data engineers don't need to create a new reflection for every new use case that comes along. For example, if a user creates a reflection on a dataset that joins a fact table with three dimension tables, Dremio can accelerate queries that include any subset of these joins (e.g., the fact table joined with just one of the dimension tables).
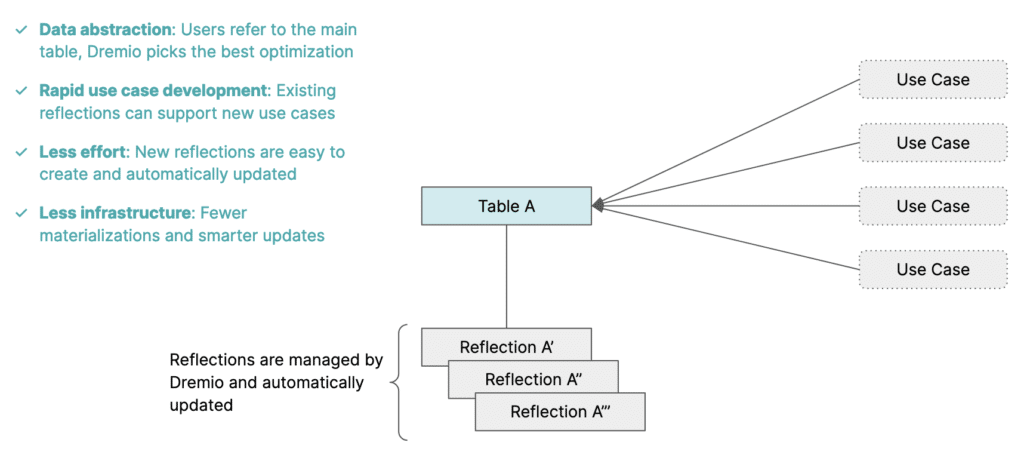
With reflections, end users can work freely in their semantic layer without ever needing to know about their physical data model. Data engineers can eliminate redundant data pipelines and physical data copies, as well as their associated compute and storage costs. In addition, data engineers no longer need to spend time working with end users to help them understand which derived datasets can accelerate their specific workloads, which ultimately accelerates time to value.
Transparent acceleration in action
The easiest way to see how Dremio’s transparent acceleration benefits end users is through a quick example. We’ll run through the example below from the perspective of an end user, interacting through the Dremio UI.
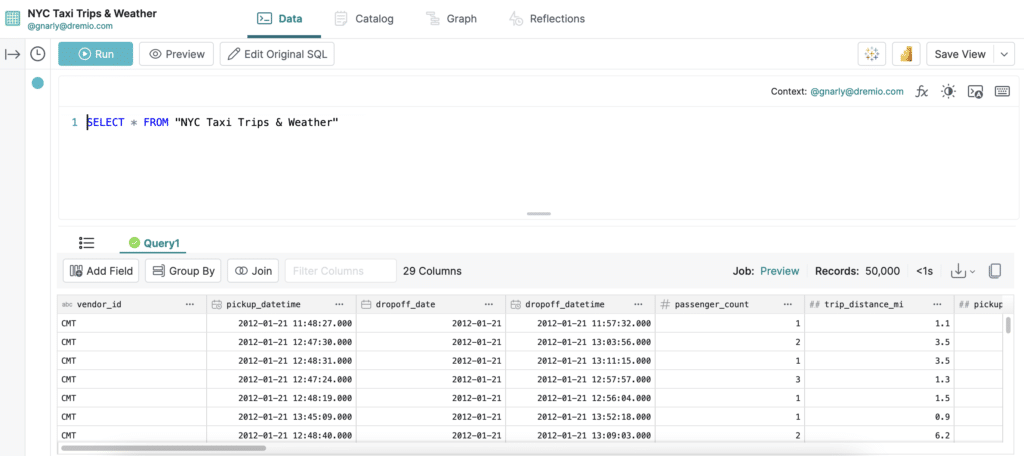
Our dataset
Suppose we have a dataset named NYC Taxi Trips & Weather:
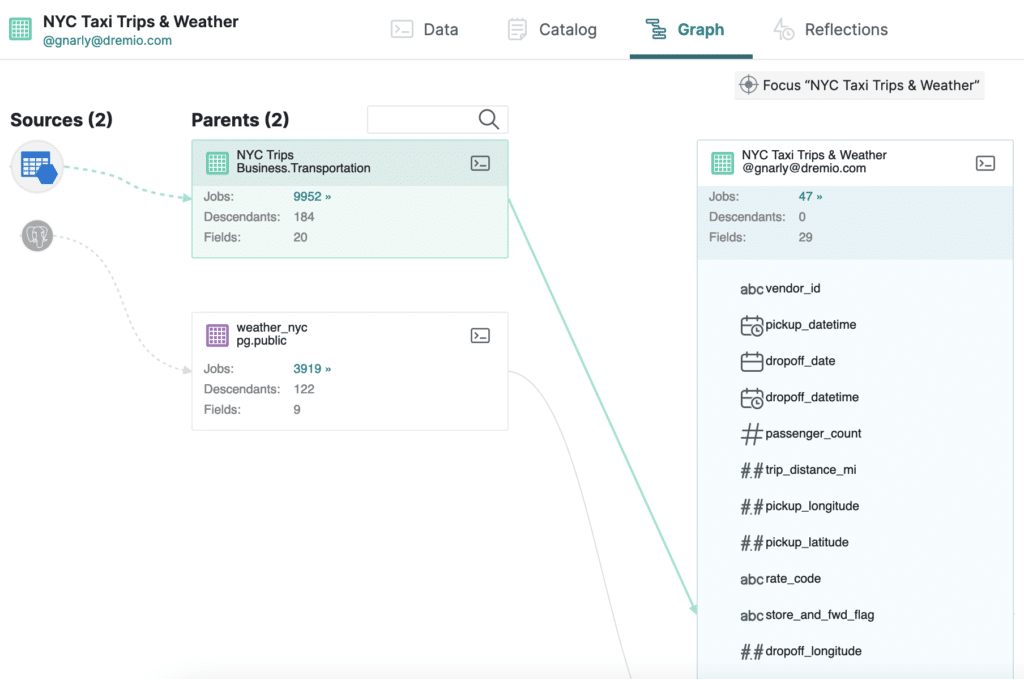
Dremio’s built-in lineage graph shows us that NYC Taxi Trips & Weather is a view that combines two datasets:
- NYC Trips: A dataset containing information on all the taxi trips that happened in New York City over a certain period of time (e.g., vendor name, passenger count, pickup/dropoff location, trip distance, trip cost, etc.). This dataset lives in Azure Data Lake Storage.
- weather_nyc: A dataset containing daily weather data for New York City. This dataset lives in a PostgreSQL instance.
We can also see through a simple COUNT(*) query that NYC Taxi Trips & Weather contains over 1 billion records:
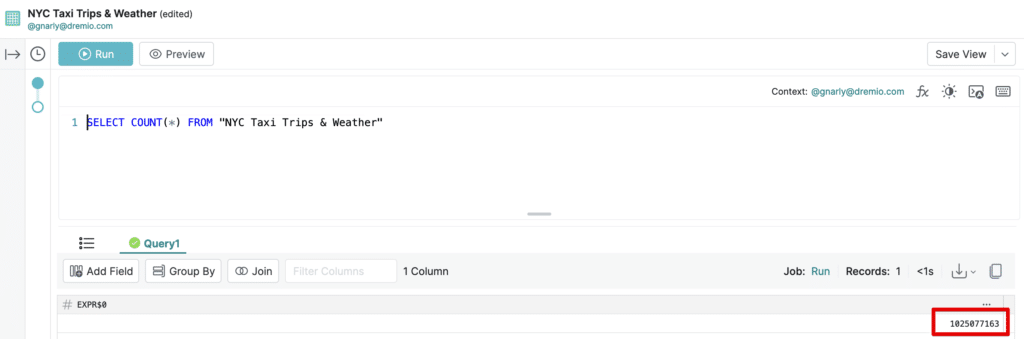
With Dremio’s transparent acceleration, we can analyze this billion-row dataset with interactive speed without having to know about how the data is organized, or any underlying physical optimizations that may (or may not) exist.
Analysis and query execution
Let’s use the SQL Runner to run the following query, which calculates the average tip amount for taxi trips in each month, along with each month’s average minimum and maximum temperature:
SELECT
MONTH(pickup_date) "Month",
ROUND(AVG(tip_amount), 2) "Average Tip Amount",
ROUND(AVG(tempmin), 2) "Average Min Temp",
ROUND(AVG(tempmax), 2) "Average Max Temp"
FROM "NYC Taxi Trips & Weather"
GROUP BY 1
ORDER BY 1 ASC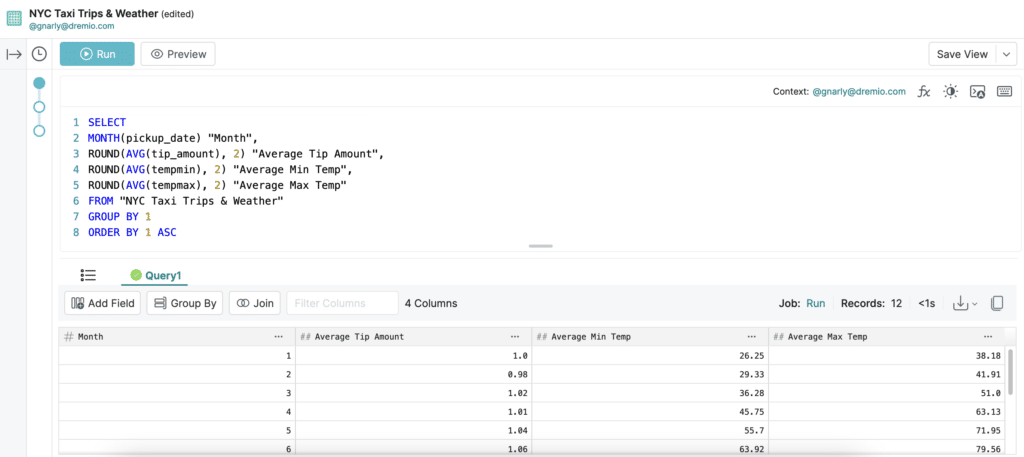
This query on a billion-row dataset took less than a second to run — 493ms to be precise. The query’s raw profile shows us the details:
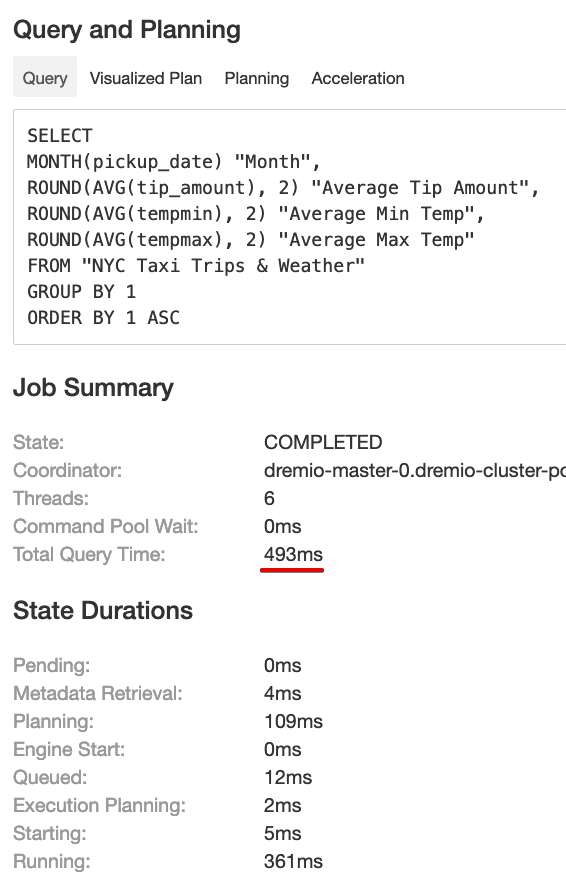
493ms (including preparation steps like metadata retrieval and planning) to run an aggregate query on a billion-row dataset? How? Let’s take a look at what happens under the hood when we run a query.
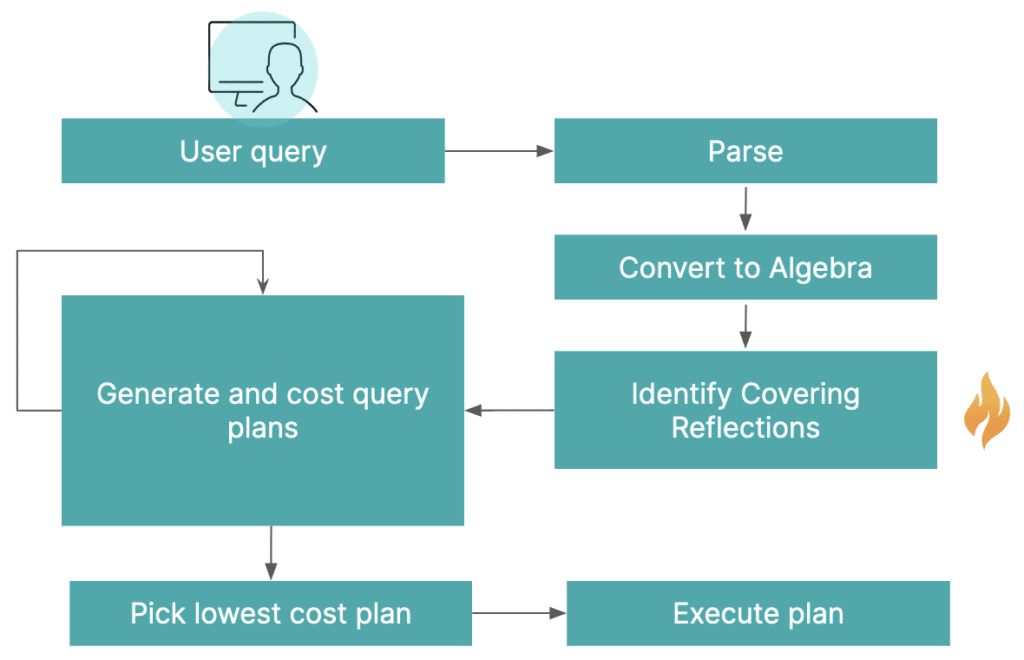
- Parse/validate the query: When you submit a query, Dremio first parses it and makes sure the SQL statement is valid — including syntax checking and making sure you have the right permissions to the specified table(s).
- Generate an initial plan: Dremio generates an initial query plan from queries it has parsed and validated. Here’s the plan from the query we just ran (recall that we read these query execution trees starting from the bottom):
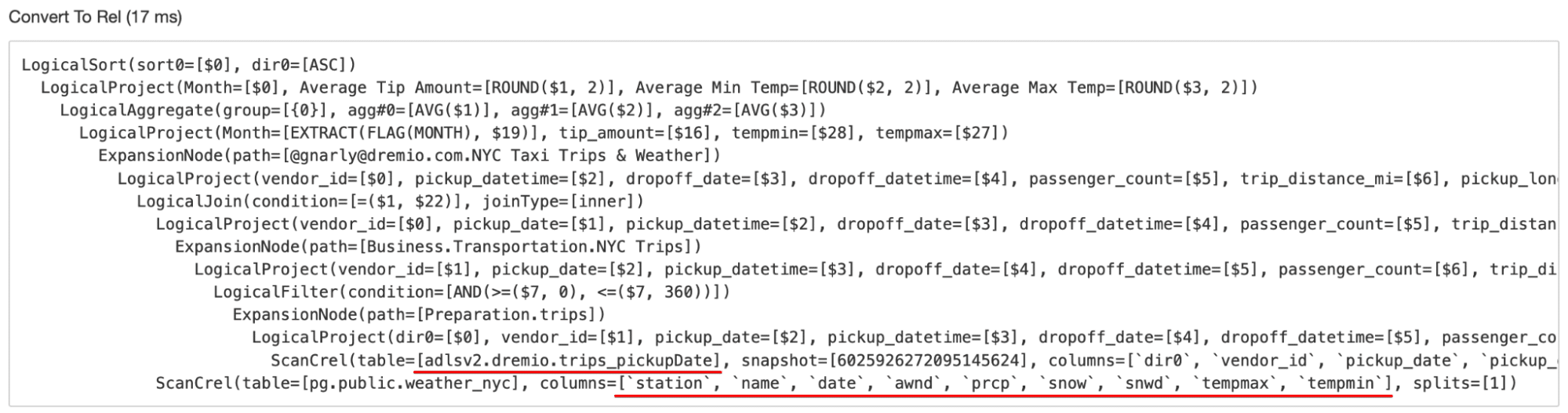
Note that the first operations specified in this plan are to scan the original billion-row base table residing in ADLS, as well as the original base table in PostgreSQL. In addition, note that the scan for the PostgreSQL table includes all columns in the Weather NYC dataset, regardless of whether or not they were needed to satisfy the query. - Rewrite to a cheaper, logically-equivalent plan: Dremio automatically performs an algebraic match between the query and reflections that potentially satisfy the query. If any reflections match, Dremio substitutes the reflection with the lowest cost into the query plan to build a logically-equivalent plan. Dremio also performs other optimizations to minimize data processing, such as column pruning. This is all done automatically behind the scenes. Here’s the logically-equivalent plan that was generated in our example:
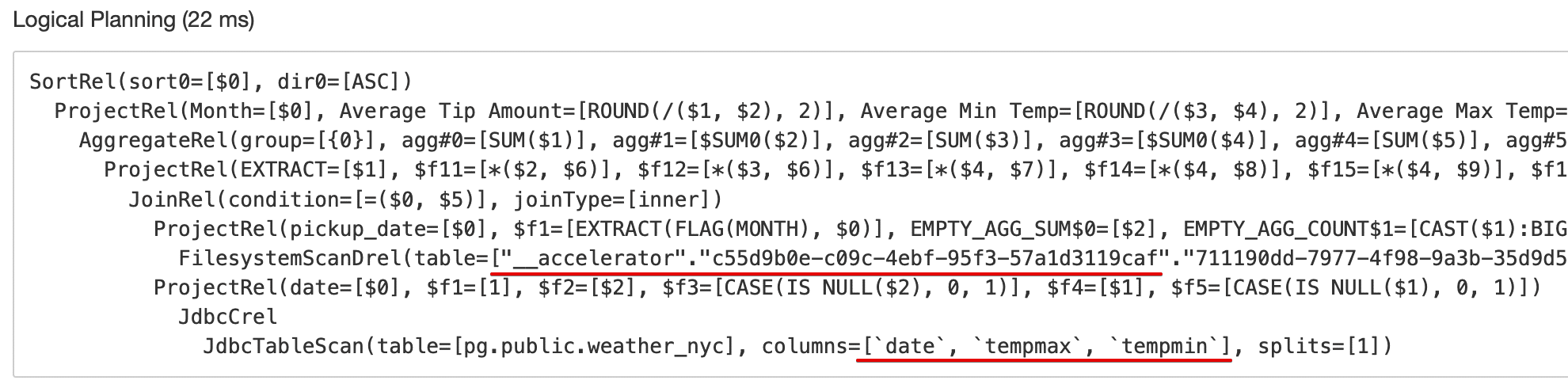
There are two notable changes here which will save us a lot of time:- Instead of reading the billion-row base dataset from ADLS, the optimizer found a reflection that covers the query and substituted it into the query plan for us automatically. This is much more efficient as Dremio needs to read and operate on much less data (especially as the reflection, by definition, has at least partially precomputed what’s needed to satisfy the query).
- The rewritten plan only reads the PostgreSQL columns required to satisfy our query.
- Generate and execute the physical plan: The logical plan generated above becomes the basis for the physical plan, which implements how to operate on the logical expression (including engine selection and thread parallelism). Here’s a snippet of the physical plan in Dremio’s query plan visualizer:
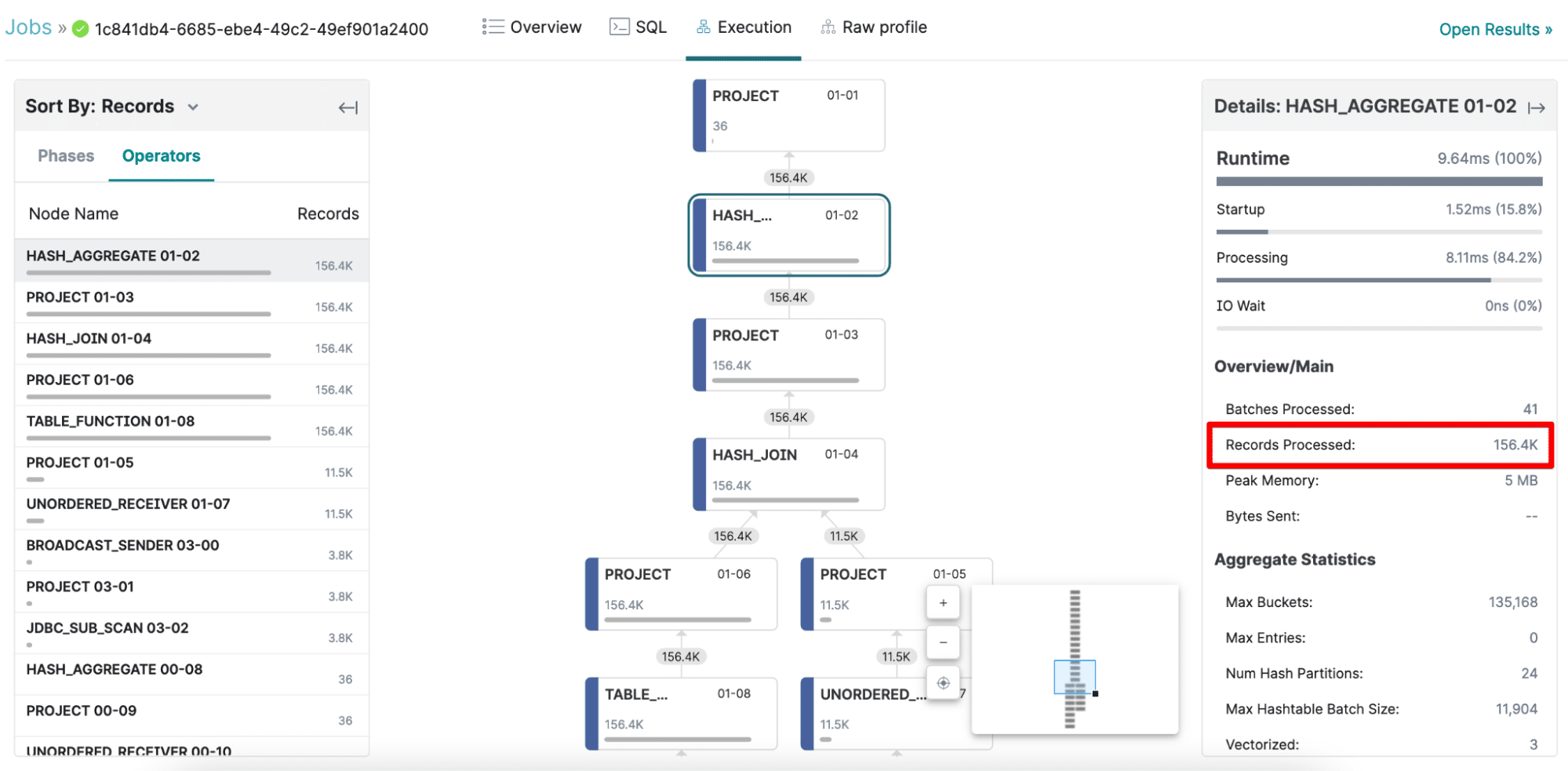
Even though the dataset contains over a billion records, the operators only process a maximum of 156K records because Dremio used a reflection to satisfy the query — 6,500x fewer rows.
The best part is that to a user, all this acceleration is completely transparent and happens behind the scenes. In the example above, we saw that we didn’t need to know anything about the underlying physical data model when working with our data. We submitted a query that performed aggregations over a large virtual dataset that contains data residing across multiple sources, and let Dremio do the rest.
Conclusion
While semantic layers aim to expose a common view of data for end users in business-friendly terms (with common business logic and metrics across data sources), it’s important to ensure that end users can also still work with data quickly so they can make timely, impactful decisions for their companies.
In this blog, we discussed how Dremio’s semantic layer achieves this through transparent query acceleration. We showed how easy it is for end users to analyze large datasets in their semantic layer without sacrificing speed or ease of use, and walked through one of the key technologies in Dremio’s query acceleration toolbox that makes this possible. In addition, we learned about how Dremio’s approach to query acceleration makes life easier for data engineers, not just end users.
If you’d like to learn more about reflections, check out our documentation, watch this technical deep dive video, or read this whitepaper. You can also get hands-on with Dremio here. It’s the simplest and fastest way to experience Dremio’s lakehouse (for free!).
Additional resources
- Webinar: Enable No-Copy Data Marts with a Unified Semantic Layer
- Webinar: Unified Access for Your Data Mesh: Self-Service Data with Dremio’s Semantic Layer
- Whitepaper: Best Practices to Deliver Self-Service Analytics
- Whitepaper: Dremio Semantic Layer Best Practices for Cost-Efficient Analytics
- Whitepaper: Dremio Architecture Guide
Thanks to Brock Griffey, Jason Hughes, and Tomer Shiran for their guidance on this blog.
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->